Qwen-AgentWorld-Leitfaden: Wie Language World Models das Training, die Evaluation und den Einsatz von KI-Agenten verändern
Ein praxisnah überarbeiteter Leitfaden zu Qwen-AgentWorld für Entwickler und KI-Produktteams. Er behandelt Language World Models, sieben Interaktionsdomänen für Agenten, die CPT/SFT/RL-Trainingspipeline, AgentWorldBench, die Modellfamilien 35B-A3B und 397B-A17B, den Einsatz mit SGLang/vLLM sowie die Bedeutung dieses Wandels für Infrastruktur und Evaluation von KI-Agenten.

Originalbild des Artikels: Qwen-AgentWorld vereinheitlicht Text- und GUI-Umgebungen
Der interessanteste Teil von Qwen-AgentWorld ist nicht, dass es ein weiterer stärkerer KI-Agent ist. Es verlagert das Problem eine Ebene tiefer: Wenn Agenten innerhalb von Umgebungen lernen müssen, kann dann die Umgebung selbst durch ein Sprachmodell modelliert werden?
Traditionelle Agenten stützen sich für Training und Evaluierung auf reale Browser, Terminals, Code-Repositories, mobile Apps und Desktop-Umgebungen. Das ist realistisch, aber teuer, schwer zu skalieren und schwierig zu kontrollieren. Qwen-AgentWorld verwendet ein Sprach-Weltmodell, um diese Umgebungen zu simulieren, sodass Agenten in einer besser kontrollierbaren sprachbasierten Welt trainiert und getestet werden können.
Das bedeutet, dass Qwen-AgentWorld nicht nur ein Chatbot und auch nicht einfach ein autonomer Agent ist. Es lässt sich besser als Infrastruktur zur Umgebungssimulation für KI-Agenten verstehen.
Warum Sprach-Weltmodelle wichtig sind
Der schwierige Teil der Agentenarbeit besteht nicht nur darin, ob das Modell antworten kann. Der schwierige Teil besteht darin vorherzusagen, was nach einer Aktion geschieht. Ein Web-Klick, ein Terminalbefehl, eine Codeänderung, ein MCP-Toolaufruf oder eine Android-Geste verändern alle den Zustand der Umgebung.
Wenn jeder Trainingsschritt von realen Umgebungen abhängt, sind die Kosten hoch und die Ergebnisse schwerer zu reproduzieren. Ein Sprach-Weltmodell versucht, die nächste Beobachtung aus dem aktuellen Kontext und der Aktion des Agenten vorherzusagen.
• Niedrigere Trainingskosten: weniger Starts realer Umgebungen für jede Trajektorie.
• Kontrolliertere Evaluierung: Störungen und fiktive Welten können sicher eingebracht werden.
• Sauberere Übertragung: verschiedene Domänen werden zu Varianten der Modellierung von Zustand-Aktion-Folgezustand.
Sieben Domänen: von Textwerkzeugen bis zu GUI-Umgebungen
Originalbild des Artikels: Qwen-AgentWorld deckt MCP, Suche, IDE/SWE, Terminal, Web, Betriebssystem und Android ab
Qwen-AgentWorld deckt MCP, Suche, Terminal, SWE, Web, Betriebssystem und Android ab. Die ersten vier liegen näher an Textumgebungen; die letzten drei sind GUI-zentrierte Umgebungen.
Domäne | Typ | Was simuliert werden kann |
MCP | Textwerkzeug | Toolaufrufe, Funktionsrückgaben, Änderungen des Dienstzustands |
Suche | Textumgebung | Suchergebnisse, Snippets, Ranking und Risiken von Antwort-Leaks |
Terminal | Befehlszeile | Shell-Ausgabe, Dateisystemzustand, Prozessverhalten |
SWE | Softwareentwicklung | Codeänderungen, Tests, Patches und Fehlermeldungen |
Web | GUI | Browser-DOM-Zustand, Formulare, Schaltflächen und Navigation |
OS | GUI | Desktopfenster, Dateien, Apps und Systemzustand |
Android | GUI | Mobile UI-Bäume und Zustand nach Touch-Aktionen |
Der Nutzen besteht darin, dass Teams nicht für jede Umgebung einen separaten Simulator benötigen. Stattdessen lernt das Modell eine sprachbasierte Darstellung von Zustandsübergängen über Domänen hinweg.
Natives Weltmodell, keine nachträgliche Anpassung
Das Wort „nativ“ ist wichtig. Qwen-AgentWorld wird nicht als allgemeines LLM präsentiert, das mit ein paar Agenten-Prompts nachgerüstet wurde. Die Modellierung von Umgebungen ist ab der Phase des kontinuierlichen Pre-Trainings in das Trainingsziel integriert.
Dimension | Nachträgliche LLM-Anpassung | Qwen-AgentWorld |
Trainingsziel | Zuerst allgemeine Sprache, später Agentenverhalten | Übergang von Umgebungszuständen ab CPT |
Pipeline | Meist SFT oder RL nach dem Training | CPT -> SFT -> RL |
Wissenseinbringung | Prompting und Datenaugmentation | Umgebungsdynamiken in die Modellgewichte eingebettet |
Abdeckung | Oft eine oder wenige Domänen | Sieben Domänen in einem Modell |
CPT bringt Umgebungsdynamiken ein, SFT aktiviert Schlussfolgern zur Vorhersage des nächsten Zustands, und RL verbessert Format, Faktentreue, Konsistenz, Realismus und Gesamtqualität.
Modelle und Benchmarks: Die Zahlen genau lesen
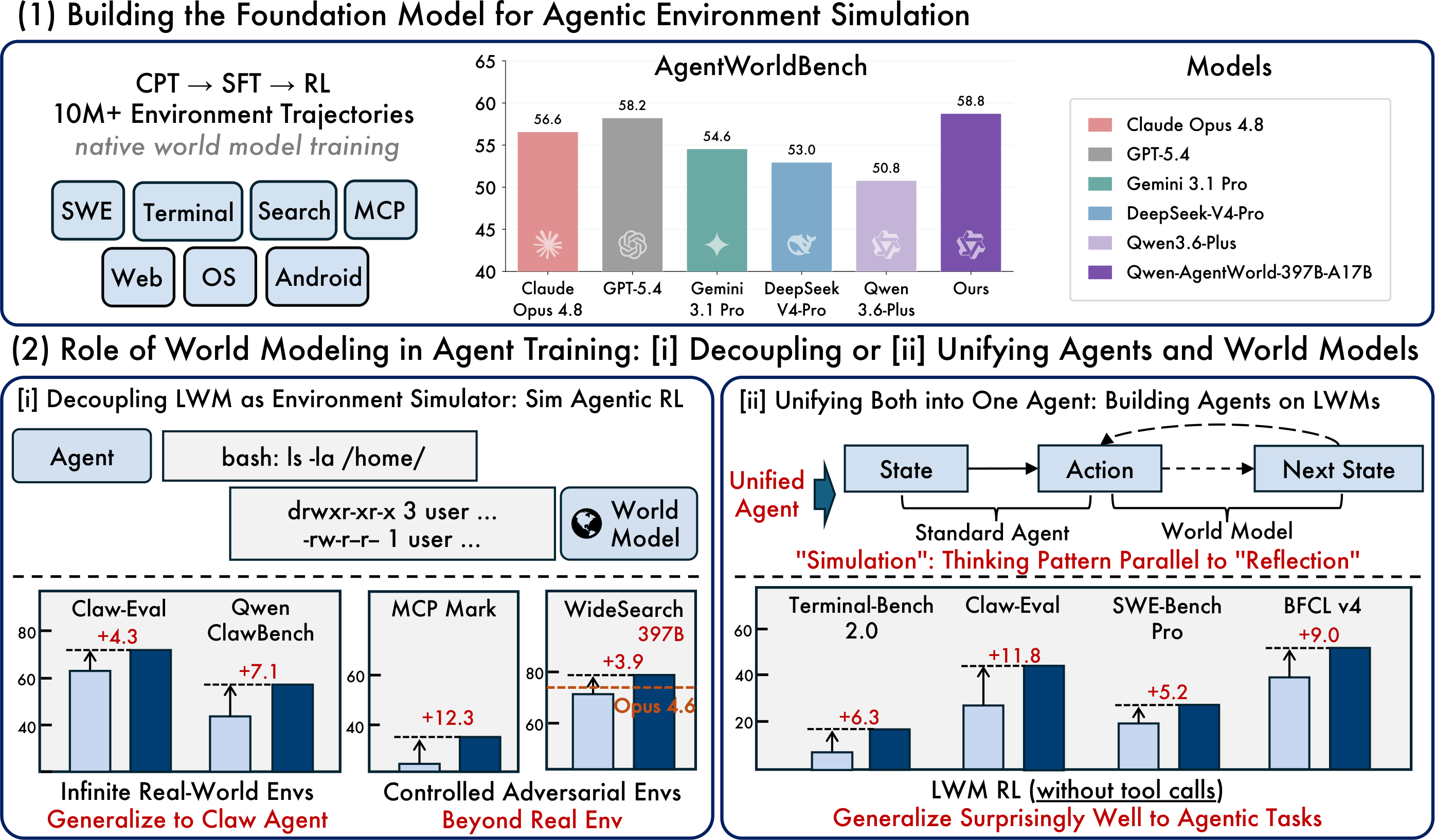
Bild aus dem Originalartikel: Basismodell, simuliertes RL und vereinheitlichte Agentenparadigmen
Die praktischste offene Veröffentlichung ist Qwen-AgentWorld-35B-A3B, ein MoE-Modell mit insgesamt 35B / 3B aktiven Parametern und einer standardmäßigen Kontextlänge von 262K Tokens. Das Forschungs-Flaggschiff Qwen-AgentWorld-397B-A17B erzielt den von Qwen gemeldeten stärkeren AgentWorldBench-Score.
Element | Erklärung |
Qwen-AgentWorld-35B-A3B | Offene Modellgewichte, die Entwickler herunterladen, bereitstellen und testen können |
Qwen-AgentWorld-397B-A17B | Forschungs-Flaggschiff mit einem gemeldeten stärkeren Benchmark-Ergebnis |
AgentWorldBench | Ein Benchmark mit sieben Domänen und Ground-Truth-Beobachtungen aus der Ausführung in realen Umgebungen |
Bewertungsdimensionen | Format, Faktizität, Konsistenz, Realismus und Qualität |
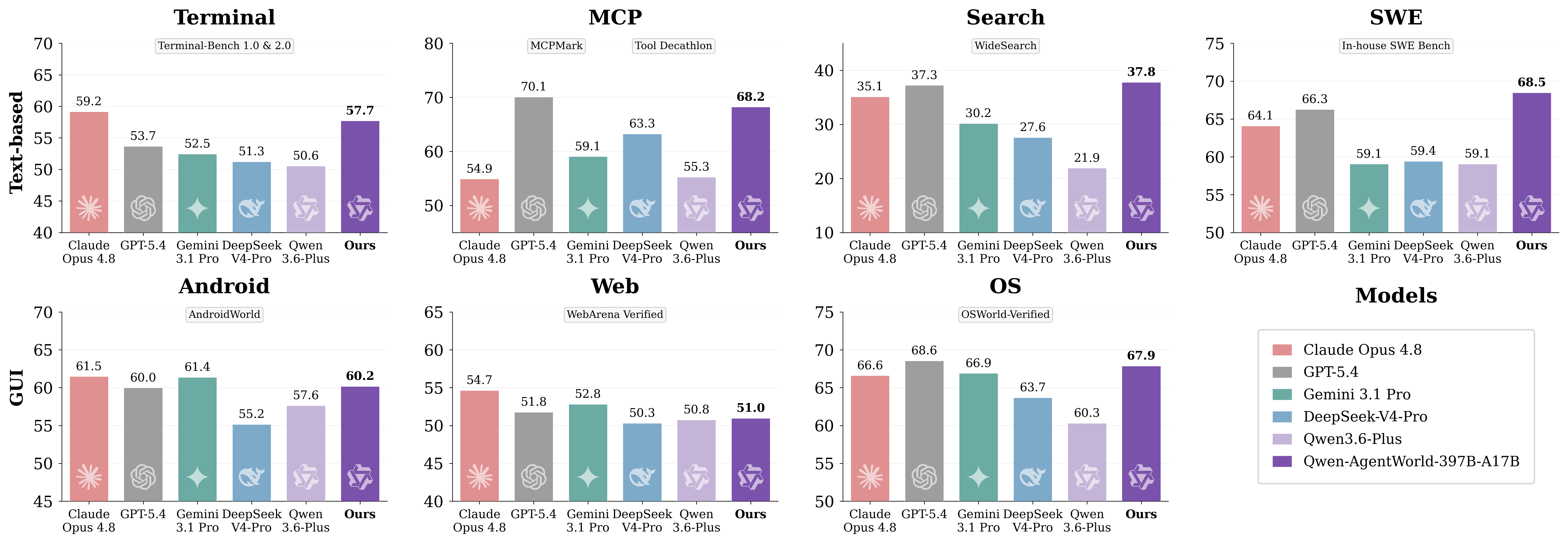
Bild aus dem Originalartikel: Ergebnisse von AgentWorldBench auf Domänenebene
Entscheidend ist, den Benchmark nicht als universelles Chatbot-Ranking zu betrachten. AgentWorldBench misst die Qualität der Umgebungssimulation. Für Entwickler lautet die praktische Frage, ob das Modell dabei hilft, zuverlässigere Workflows für Agententraining, Evaluation und Regressionstests aufzubauen.
Bereitstellung: Sie kann schnell starten, aber die Hardware bleibt wichtig
Der Originalartikel betont die schnelle Bereitstellung. Das stimmt, wenn GPU, Treiber, Python-Umgebung und Inferenz-Framework bereits vorbereitet sind. Für normale Nutzer sind die eigentlichen Engpässe VRAM, langer Kontext und Multi-GPU-Bereitstellung.
Die offiziellen Anweisungen unterstützen SGLang, vLLM, Transformers und OpenAI-kompatible API-Aufrufe. Für den serverartigen Einsatz sind SGLang oder vLLM der sauberere Weg.
# SGLang-Beispiel pip install sglang python -m sglang.launch_server \ --model-path Qwen/Qwen-AgentWorld-35B-A3B \ --port 8000 \ --tp-size 4 \ --context-length 262144 \ --reasoning-parser qwen3
# vLLM-Beispiel pip install vllm vllm serve Qwen/Qwen-AgentWorld-35B-A3B \ --port 8000 \ --tensor-parallel-size 4 \ --max-model-len 262144 \ --reasoning-parser qwen3 \ --language-model-only \ --trust-remote-code
In der Praxis sollte man bei OOM-Fehlern zuerst die Kontextlänge reduzieren, die Tensor-Parallel-Einstellungen für Multi-GPU-Bereitstellungen überprüfen und vermeiden, ein 256K-Kontextfenster zu erzwingen, wenn das Ziel nur ein kleiner Proof of Concept ist.
Für wen ist Qwen-AgentWorld relevant?
• Agentenforscher können World Modeling, simulierte Umgebungen und Agenten-RL untersuchen.
• KI-Engineering-Teams können Simulationstests für Tools, Terminals, Browser, Betriebssysteme und mobile Umgebungen erstellen.
• Enterprise-KI-Produktteams können verstehen, wie sich Agenteninfrastruktur von „Antworten“ hin zu umgebungsbewusstem Reasoning entwickelt.
Wenn Ihr Ziel einfaches Schreiben, Chatten oder normale Codevervollständigung ist, ist dies nicht das direkteste Modell. Sein Wert ist grundlegender: die Modellierung von Kausalität zwischen Agentenaktionen und Umweltveränderungen.
Was das für Enterprise-KI-Infrastruktur bedeutet
Projekte wie Qwen-AgentWorld zeigen, dass KI-Agenteninfrastruktur über Demos hinausgeht. Doch je technischer ein Produkt wird, desto klarer muss es erklären, was es tut, für wen es gedacht ist, wie es bereitgestellt wird, wo seine Grenzen liegen und welche Ergebnisse es ermöglicht.
Bei KI-Agentenprodukten, Modelldiensten, Entwicklertools und Enterprise-KI-Infrastruktur darf technische Kommunikation nicht bei Modellnamen und Benchmark-Zahlen aufhören. Teams müssen Architektur, Umgebungen, Evaluationsmethoden, Einschränkungen und reale Anwendungsfälle klar erläutern.
Ein Team, das Plattformen für Agententraining oder Dienste zur Modellbereitstellung entwickelt, benötigt Architekturnotizen, Anwendungsfälle, FAQs, Bereitstellungsdokumentation, Evaluationsberichte und Sicherheitsgrenzen — nicht nur eine kurze Produkteinführung.
Abschließende Erkenntnis
Der Wert von Qwen-AgentWorld liegt nicht nur darin, dass ein Modell ein höheres Ergebnis meldet als ein anderes. Die tiefere Veränderung besteht darin, dass Agententraining und -evaluation sprachbasierte Weltmodelle als Infrastruktur nutzen können: Umgebungen simulieren, fundierte Benchmarks aufbauen, Schwächen durch kontrollierbare Störungen sichtbar machen und Wissen aus dem World Modeling auf schwierigere Agentenaufgaben übertragen.
Für Entwickler ist es eine leistungsstarke Umgebungssimulation zum Studieren. Für Produktteams weist es auf die Zukunft der Agenteninfrastruktur hin. Für Enterprise-KI-Teams unterstreicht es einen weiteren Punkt: Je komplexer die Technologie, desto wichtiger werden klare Architekturhinweise, Dokumentation und Evaluierungsmethoden.
FAQ
Ist Qwen-AgentWorld ein normales Chatmodell?
Nein. Es lässt sich besser als sprachbasiertes Weltmodell verstehen, das Agentenumgebungen simuliert und die nächste Beobachtung nach einer Aktion vorhersagt.
Welche Bereiche deckt Qwen-AgentWorld ab?
Es deckt MCP, Suche, Terminal, SWE, Web, OS und Android ab und umfasst sowohl Text- als auch GUI-Umgebungen.
Kann Qwen-AgentWorld-35B-A3B lokal bereitgestellt werden?
Ja, aber es erfordert leistungsstarke Hardware für Long-Context-Inferenz. Nutzer sollten das Kontextfenster verkleinern, wenn sie an Speichergrenzen stoßen.
Was bewertet AgentWorldBench?
Es bewertet vorhergesagte Umgebungsbeobachtungen anhand von Format, Faktentreue, Konsistenz, Realismus und Qualität.
Warum ist das für Unternehmen wichtig?
Es ermöglicht eine besser kontrollierbare Agentensimulation, Tests und Sicherheitsbewertung, bevor Agenten realen Betriebsumgebungen ausgesetzt werden.
Verwandte Tools
• SGLang
• vLLM
Quellen
• Technischer Bericht zu Qwen-AgentWorld
• Qwen-AgentWorld-35B-A3B auf Hugging Face