Guide Qwen-AgentWorld : comment les modèles de monde linguistique transforment l’entraînement, l’évaluation et le déploiement des agents IA
Un guide pratique réécrit de Qwen-AgentWorld destiné aux développeurs et aux équipes produit IA, couvrant les modèles de monde linguistique, les sept domaines d’interaction des agents, le pipeline d’entraînement CPT/SFT/RL, AgentWorldBench, la famille de modèles 35B-A3B et 397B-A17B, le déploiement avec SGLang/vLLM, ainsi que les implications de cette évolution pour l’infrastructure et l’évaluation des agents IA.

Image de l’article original : Qwen-AgentWorld unifie les environnements textuels et d’interface graphique
La partie la plus intéressante de Qwen-AgentWorld n’est pas qu’il s’agit d’un nouvel agent d’IA plus puissant. Il déplace le problème à un niveau plus profond : si les agents doivent apprendre au sein d’environnements, l’environnement lui-même peut-il être modélisé par un modèle de langage ?
Les agents traditionnels s’appuient sur de vrais navigateurs, terminaux, dépôts de code, applications mobiles et environnements de bureau pour l’entraînement et l’évaluation. C’est réaliste, mais coûteux, lent à mettre à l’échelle et difficile à contrôler. Qwen-AgentWorld utilise un modèle de monde linguistique pour simuler ces environnements, afin que les agents puissent être entraînés et testés dans un monde fondé sur le langage, plus contrôlable.
Cela signifie que Qwen-AgentWorld n’est pas seulement un chatbot ni simplement un agent autonome. Il se comprend plutôt comme une infrastructure de simulation d’environnements pour agents d’IA.
Pourquoi les modèles de monde linguistiques sont importants
La difficulté du travail des agents ne réside pas seulement dans la capacité du modèle à répondre. Elle réside dans la prédiction de ce qui se passe après une action. Un clic Web, une commande de terminal, une modification de code, un appel d’outil MCP ou un geste Android modifient tous l’état de l’environnement.
Si chaque étape d’entraînement dépend d’environnements réels, le coût est élevé et les résultats sont plus difficiles à reproduire. Un modèle de monde linguistique tente de prédire l’observation suivante à partir du contexte actuel et de l’action de l’agent.
• Coût d’entraînement réduit : moins de lancements d’environnements réels pour chaque trajectoire.
• Évaluation plus contrôlée : les perturbations et les mondes fictifs peuvent être injectés en toute sécurité.
• Transfert plus propre : différents domaines deviennent des variations de la modélisation état-action-état suivant.
Sept domaines : des outils textuels aux environnements d’interface graphique
Image de l’article original : Qwen-AgentWorld couvre MCP, Search, IDE/SWE, Terminal, Web, OS et Android
Qwen-AgentWorld couvre MCP, Search, Terminal, SWE, Web, OS et Android. Les quatre premiers sont plus proches des environnements textuels ; les trois derniers sont des environnements centrés sur l’interface graphique.
Domaine | Type | Ce qu’il peut simuler |
MCP | Outil textuel | Appels d’outils, retours de fonctions, changements d’état de service |
Search | Environnement textuel | Résultats de recherche, extraits, classement et risques de fuite de réponses |
Terminal | Ligne de commande | Sortie du shell, état du système de fichiers, comportement des processus |
SWE | Génie logiciel | Modifications de code, tests, correctifs et messages d’erreur |
Web | Interface graphique | État du DOM du navigateur, formulaires, boutons et navigation |
OS | Interface graphique | Fenêtres de bureau, fichiers, applications et état du système |
Android | Interface graphique | Arbres d’interface utilisateur mobile et état après des actions tactiles |
L’intérêt est que les équipes n’ont pas besoin d’un simulateur distinct pour chaque environnement. Au lieu de cela, le modèle apprend une représentation linguistique des transitions d’état entre les domaines.
Modèle du monde natif, pas une adaptation a posteriori
Le mot « natif » est important. Qwen-AgentWorld n’est pas présenté comme un LLM généraliste auquel on aurait ajouté quelques invites d’agent. La modélisation de l’environnement est intégrée à l’objectif d’entraînement dès l’étape de pré-entraînement continu.
Dimension | Adaptation a posteriori d’un LLM | Qwen-AgentWorld |
Objectif d’entraînement | Langage général d’abord, comportement d’agent ensuite | Transition d’état de l’environnement dès le CPT |
Pipeline | Principalement SFT ou RL après l’entraînement | CPT -> SFT -> RL |
Injection de connaissances | Invites et augmentation des données | Dynamique de l’environnement intégrée dans les poids du modèle |
Couverture | Souvent un ou quelques domaines | Sept domaines dans un seul modèle |
Le CPT injecte la dynamique de l’environnement, le SFT active le raisonnement de prédiction de l’état suivant, et le RL améliore le format, l’exactitude factuelle, la cohérence, le réalisme et la qualité globale.
Modèles et benchmarks : lisez les chiffres attentivement
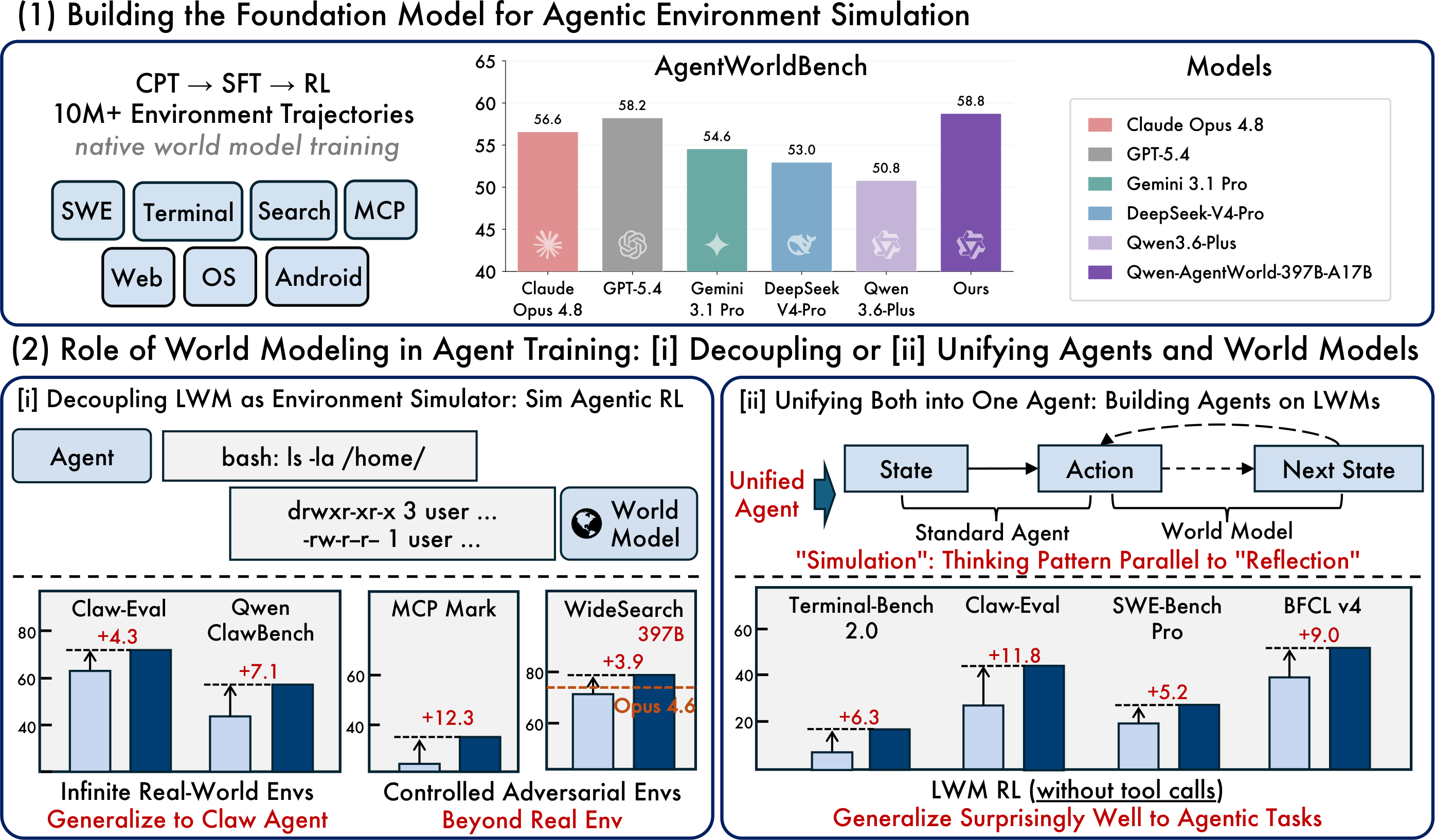
Image de l’article original : modèle de fondation, RL simulé et paradigmes d’agent unifiés
La version ouverte la plus pratique est Qwen-AgentWorld-35B-A3B, un modèle MoE de 35B au total / 3B actifs avec une longueur de contexte par défaut de 262K tokens. Le modèle phare de recherche, Qwen-AgentWorld-397B-A17B, obtient le score AgentWorldBench plus élevé rapporté par Qwen.
Élément | Explication |
Qwen-AgentWorld-35B-A3B | Poids de modèle ouverts que les développeurs peuvent télécharger, déployer et tester |
Qwen-AgentWorld-397B-A17B | Modèle phare de recherche avec un score de référence annoncé plus élevé |
AgentWorldBench | Un benchmark couvrant sept domaines avec des observations de référence issues de l’exécution dans des environnements réels |
Dimensions d’évaluation | Format, factualité, cohérence, réalisme et qualité |
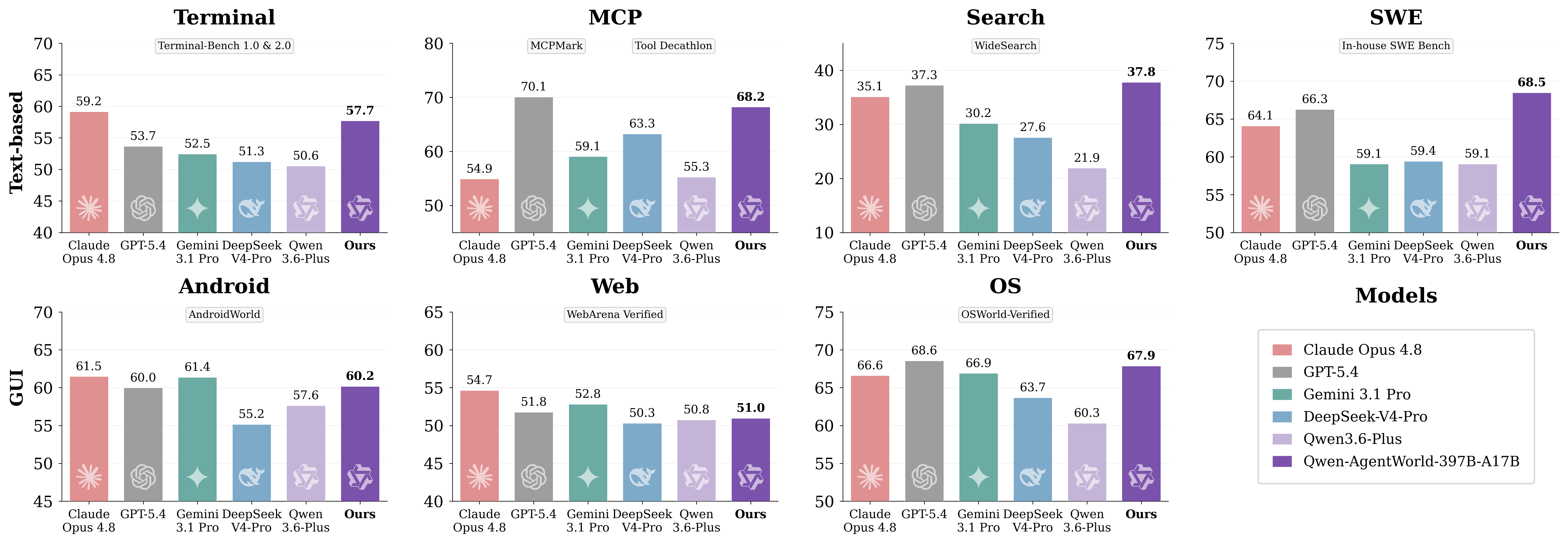
Image de l’article original : résultats d’AgentWorldBench au niveau des domaines
L’essentiel est de ne pas considérer le benchmark comme un classement universel de chatbots. AgentWorldBench mesure la qualité de simulation d’environnement. Pour les développeurs, la question pratique est de savoir si le modèle aide à créer des flux de travail plus fiables pour l’entraînement, l’évaluation et les tests de régression des agents.
Déploiement : il peut démarrer rapidement, mais le matériel reste important
L’article original met l’accent sur un déploiement rapide. C’est vrai lorsque le GPU, les pilotes, l’environnement Python et le framework d’inférence sont déjà prêts. Pour les utilisateurs ordinaires, les véritables goulots d’étranglement sont la VRAM, le contexte long et le service multi-GPU.
Les instructions officielles prennent en charge SGLang, vLLM, Transformers et les appels API compatibles avec OpenAI. Pour une utilisation de type serveur, SGLang ou vLLM constitue l’approche la plus propre.
# Exemple SGLang pip install sglang python -m sglang.launch_server \ --model-path Qwen/Qwen-AgentWorld-35B-A3B \ --port 8000 \ --tp-size 4 \ --context-length 262144 \ --reasoning-parser qwen3
# Exemple vLLM pip install vllm vllm serve Qwen/Qwen-AgentWorld-35B-A3B \ --port 8000 \ --tensor-parallel-size 4 \ --max-model-len 262144 \ --reasoning-parser qwen3 \ --language-model-only \ --trust-remote-code
En pratique, réduisez d’abord la longueur du contexte lorsque des erreurs OOM apparaissent, vérifiez les paramètres de parallélisme tensoriel pour les déploiements multi-GPU et évitez d’imposer une fenêtre de contexte de 256K si votre objectif est seulement une petite preuve de concept.
Qui devrait s’intéresser à Qwen-AgentWorld ?
• Les chercheurs en agents peuvent étudier la modélisation du monde, les environnements simulés et l’apprentissage par renforcement des agents.
• Les équipes d’ingénierie IA peuvent créer des tests de simulation pour les outils, les terminaux, les navigateurs, les systèmes d’exploitation et les environnements mobiles.
• Les équipes produit IA en entreprise peuvent comprendre comment l’infrastructure des agents évolue des « réponses » vers un raisonnement conscient de l’environnement.
Si votre objectif est la rédaction simple, le chat ou la complétion de code classique, ce n’est pas le modèle le plus direct. Sa valeur est plus fondamentale : modéliser la causalité entre les actions des agents et les changements de l’environnement.
Ce que cela signifie pour l’infrastructure IA en entreprise
Des projets comme Qwen-AgentWorld montrent que l’infrastructure des agents IA dépasse le stade des démonstrations. Mais plus un produit devient technique, plus il doit expliquer clairement ce qu’il fait, à qui il s’adresse, comment il est déployé, quelles sont ses limites et quels résultats il permet d’obtenir.
Pour les produits d’agents IA, les services de modèles, les outils pour développeurs et l’infrastructure IA d’entreprise, la communication technique ne peut pas s’arrêter aux noms de modèles et aux chiffres de benchmark. Les équipes doivent expliquer clairement l’architecture, les environnements, les méthodes d’évaluation, les limites et les cas d’utilisation réels.
Une équipe qui construit des plateformes d’entraînement d’agents ou des services de déploiement de modèles a besoin de notes d’architecture, de cas d’utilisation, de FAQ, de documentation de déploiement, de rapports d’évaluation et de périmètres de sécurité — pas seulement d’une courte présentation produit.
Conclusion finale
La valeur de Qwen-AgentWorld ne réside pas seulement dans le fait qu’un modèle annonce un score supérieur à un autre. Le changement plus profond est que l’entraînement et l’évaluation des agents peuvent utiliser les modèles linguistiques du monde comme infrastructure : simuler des environnements, créer des benchmarks ancrés dans la réalité, révéler les faiblesses grâce à des perturbations contrôlables et transférer les connaissances de modélisation du monde vers des tâches d’agents plus difficiles.
Pour les développeurs, c’est un puissant simulateur d’environnement à étudier. Pour les équipes produit, il indique l’avenir de l’infrastructure des agents. Pour les équipes d’IA en entreprise, il renforce un autre point : plus la technologie est complexe, plus des notes d’architecture claires, une documentation solide et des méthodes d’évaluation deviennent importantes.
FAQ
Qwen-AgentWorld est-il un modèle de chat classique ?
Non. Il est préférable de le comprendre comme un modèle de monde linguistique qui simule des environnements d’agents et prédit la prochaine observation après une action.
Quels domaines Qwen-AgentWorld couvre-t-il ?
Il couvre MCP, Search, Terminal, SWE, Web, OS et Android, englobant à la fois des environnements textuels et des interfaces graphiques.
Qwen-AgentWorld-35B-A3B peut-il être déployé localement ?
Oui, mais il nécessite du matériel robuste pour l’inférence à long contexte. Les utilisateurs doivent réduire la fenêtre de contexte s’ils atteignent les limites de mémoire.
Qu’évalue AgentWorldBench ?
Il évalue les observations d’environnement prédites selon le format, la factualité, la cohérence, le réalisme et la qualité.
Pourquoi est-ce important pour les entreprises ?
Cela permet une simulation, des tests et une évaluation de la sécurité des agents plus contrôlables avant qu’ils ne soient exposés à des environnements opérationnels réels.
Outils connexes
• SGLang
• vLLM
Sources
• Rapport technique Qwen-AgentWorld
• Qwen-AgentWorld-35B-A3B sur Hugging Face
• Jeu de données AgentWorldBench