Guia do Qwen-AgentWorld: como os modelos de mundo de linguagem transformam o treinamento, a avaliação e a implantação de agentes de IA
Um guia prático reescrito sobre o Qwen-AgentWorld para desenvolvedores e equipes de produto de IA, abordando modelos de mundo de linguagem, sete domínios de interação de agentes, o pipeline de treinamento CPT/SFT/RL, o AgentWorldBench, a família de modelos 35B-A3B e 397B-A17B, a implantação com SGLang/vLLM e o que essa mudança significa para a infraestrutura e a avaliação de agentes de IA.

Imagem do artigo original: Qwen-AgentWorld unifica ambientes de texto e GUI
A parte mais interessante do Qwen-AgentWorld não é o fato de ser mais um agente de IA mais poderoso. Ele leva o problema a uma camada mais profunda: se os agentes precisam aprender dentro de ambientes, o próprio ambiente pode ser modelado por um modelo de linguagem?
Agentes tradicionais dependem de navegadores reais, terminais, repositórios de código, aplicativos móveis e ambientes de desktop para treinamento e avaliação. Isso é realista, mas é caro, lento para escalar e difícil de controlar. O Qwen-AgentWorld usa um modelo de mundo baseado em linguagem para simular esses ambientes, para que os agentes possam ser treinados e testados em um mundo baseado em linguagem mais controlável.
Isso significa que o Qwen-AgentWorld não é apenas um chatbot nem simplesmente um agente autônomo. Ele é melhor compreendido como infraestrutura de simulação de ambientes para agentes de IA.
Por que os modelos de mundo baseados em linguagem são importantes
A parte difícil do trabalho com agentes não é apenas saber se o modelo consegue responder. A parte difícil é prever o que acontece depois de uma ação. Um clique na web, um comando de terminal, uma edição de código, uma chamada de ferramenta MCP ou um gesto no Android mudam o estado do ambiente.
Se cada etapa de treinamento depende de ambientes reais, o custo é alto e os resultados são mais difíceis de reproduzir. Um modelo de mundo baseado em linguagem tenta prever a próxima observação a partir do contexto atual e da ação do agente.
• Menor custo de treinamento: menos inicializações de ambientes reais para cada trajetória.
• Avaliação mais controlada: perturbações e mundos fictícios podem ser inseridos com segurança.
• Transferência mais limpa: diferentes domínios tornam-se variações de modelagem estado-ação-próximo estado.
Sete domínios: de ferramentas de texto a ambientes GUI
Imagem do artigo original: Qwen-AgentWorld abrange MCP, Search, IDE/SWE, Terminal, Web, OS e Android
O Qwen-AgentWorld abrange MCP, Search, Terminal, SWE, Web, OS e Android. Os quatro primeiros estão mais próximos de ambientes de texto; os três últimos são ambientes centrados em GUI.
Domínio | Tipo | O que pode simular |
MCP | Ferramenta de texto | Chamadas de ferramentas, retornos de funções, alterações no estado do serviço |
Search | Ambiente de texto | Resultados de pesquisa, trechos, classificação e riscos de vazamento de respostas |
Terminal | Linha de comando | Saída do shell, estado do sistema de arquivos, comportamento de processos |
SWE | Engenharia de software | Edições de código, testes, patches e mensagens de erro |
Web | GUI | Estado do DOM do navegador, formulários, botões e navegação |
SO | GUI | Janelas da área de trabalho, arquivos, apps e estado do sistema |
Android | GUI | Árvores de UI móvel e estado após ações de toque |
O valor está no fato de que as equipes não precisam de um simulador separado para cada ambiente. Em vez disso, o modelo aprende uma representação baseada em linguagem das transições de estado entre domínios.
Modelo de mundo nativo, não adaptação pós-hoc
A palavra “nativo” importa. O Qwen-AgentWorld não é apresentado como um LLM de uso geral remendado com alguns prompts de agente. A modelagem de ambientes é incorporada ao objetivo de treinamento desde a etapa de pré-treinamento contínuo em diante.
Dimensão | Adaptação pós-hoc de LLM | Qwen-AgentWorld |
Objetivo de treinamento | Linguagem geral primeiro, comportamento de agente depois | Transição de estado do ambiente desde o CPT |
Pipeline | Principalmente SFT ou RL após o treinamento | CPT -> SFT -> RL |
Injeção de conhecimento | Prompts e aumento de dados | Dinâmicas do ambiente incorporadas aos pesos do modelo |
Cobertura | Frequentemente um ou poucos domínios | Sete domínios em um único modelo |
O CPT injeta dinâmicas do ambiente, o SFT ativa o raciocínio de previsão do próximo estado, e o RL melhora formato, factualidade, consistência, realismo e qualidade geral.
Modelos e benchmarks: leia os números com atenção
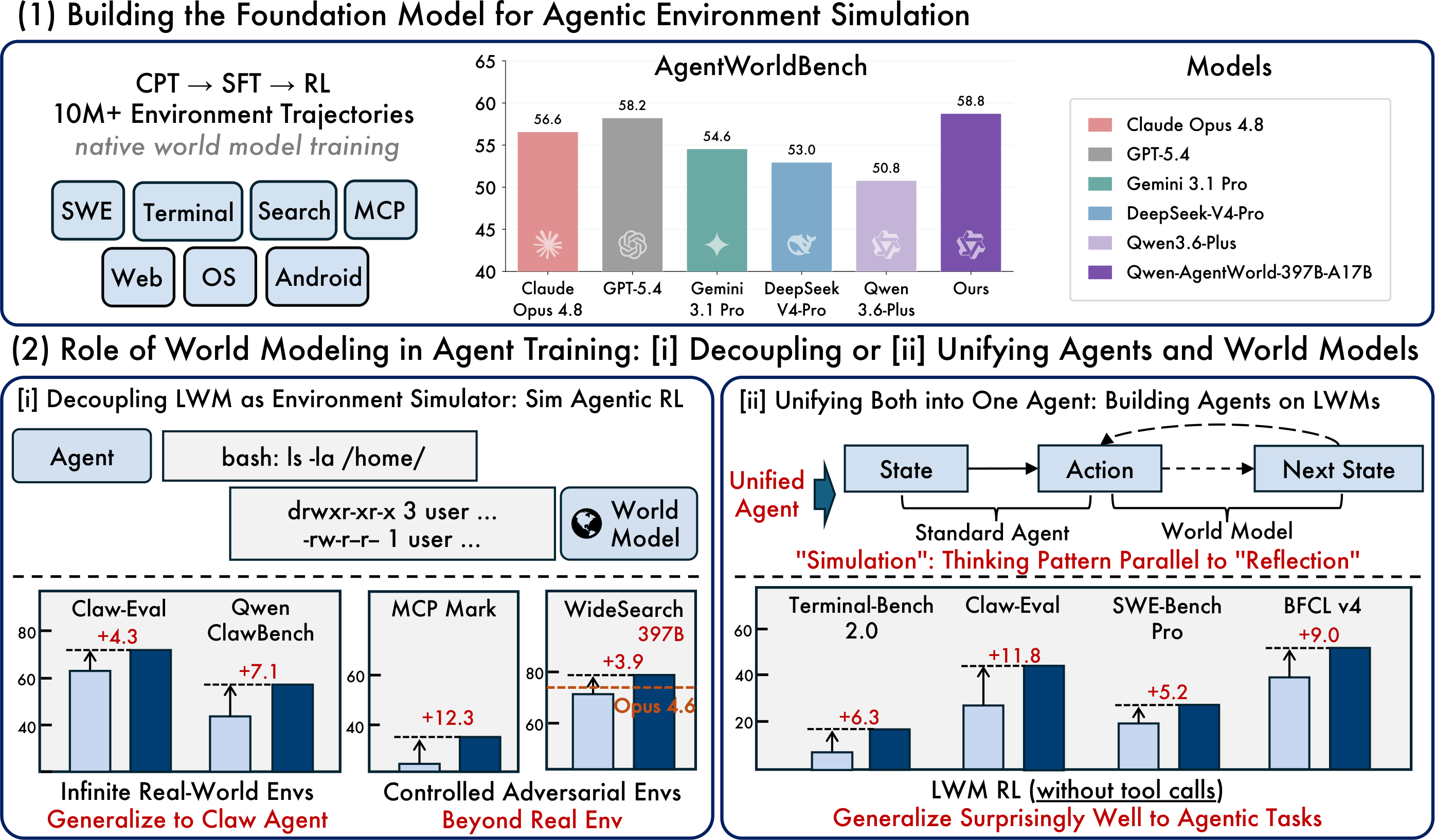
Imagem do artigo original: modelo de base, RL simulado e paradigmas de agente unificados
O lançamento aberto mais prático é o Qwen-AgentWorld-35B-A3B, um modelo MoE com 35B no total / 3B ativos e comprimento de contexto padrão de 262K tokens. O carro-chefe de pesquisa, Qwen-AgentWorld-397B-A17B, alcança a pontuação mais alta no AgentWorldBench relatada pela Qwen.
Item | Explicação |
Qwen-AgentWorld-35B-A3B | Pesos de modelo abertos para desenvolvedores baixarem, servirem e testarem |
Qwen-AgentWorld-397B-A17B | Modelo principal de pesquisa com pontuação de benchmark relatada mais forte |
AgentWorldBench | Um benchmark de sete domínios com observações de referência obtidas da execução em ambientes reais |
Dimensões de avaliação | Formato, factualidade, consistência, realismo e qualidade |
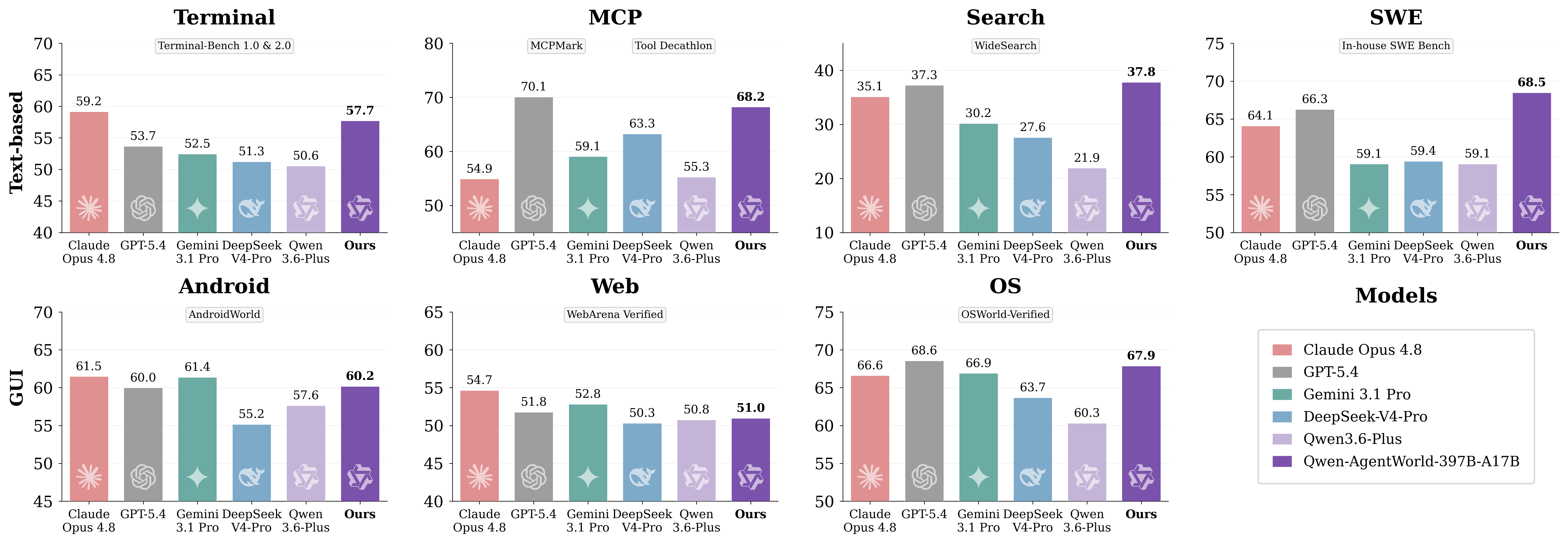
Imagem do artigo original: resultados por domínio do AgentWorldBench
O essencial é não tratar o benchmark como uma classificação universal de chatbots. O AgentWorldBench mede a qualidade da simulação de ambientes. Para desenvolvedores, a questão prática é se o modelo ajuda a criar fluxos de trabalho mais confiáveis para treinamento, avaliação e testes de regressão de agentes.
Implantação: pode começar rapidamente, mas o hardware ainda importa
O artigo original enfatiza a implantação rápida. Isso é verdade quando GPU, drivers, ambiente Python e framework de inferência já estão preparados. Para usuários comuns, os verdadeiros gargalos são VRAM, contexto longo e serviço com múltiplas GPUs.
As instruções oficiais oferecem suporte a SGLang, vLLM, Transformers e chamadas de API compatíveis com OpenAI. Para uso em estilo servidor, SGLang ou vLLM é o caminho mais limpo.
# Exemplo de SGLang pip install sglang python -m sglang.launch_server \ --model-path Qwen/Qwen-AgentWorld-35B-A3B \ --port 8000 \ --tp-size 4 \ --context-length 262144 \ --reasoning-parser qwen3
# Exemplo de vLLM pip install vllm vllm serve Qwen/Qwen-AgentWorld-35B-A3B \ --port 8000 \ --tensor-parallel-size 4 \ --max-model-len 262144 \ --reasoning-parser qwen3 \ --language-model-only \ --trust-remote-code
Na prática, reduza primeiro o comprimento do contexto quando aparecer OOM, confirme as configurações de paralelismo de tensores para implantações com múltiplas GPUs e evite forçar uma janela de contexto de 256K se seu objetivo for apenas uma pequena prova de conceito.
Quem deve se importar com o Qwen-AgentWorld?
• Pesquisadores de agentes podem estudar modelagem de mundo, ambientes simulados e RL de agentes.
• Equipes de engenharia de IA podem criar testes de simulação para ferramentas, terminais, navegadores, sistemas operacionais e ambientes móveis.
• Equipes de produtos de IA empresarial podem entender como a infraestrutura de agentes está evoluindo de “respostas” para raciocínio consciente do ambiente.
Se seu objetivo é escrita simples, chat ou conclusão normal de código, este não é o modelo mais direto. Seu valor é mais fundamental: modelar a causalidade entre ações de agentes e mudanças no ambiente.
O que isso significa para a infraestrutura de IA empresarial
Projetos como o Qwen-AgentWorld mostram que a infraestrutura de agentes de IA está indo além das demonstrações. Mas quanto mais técnico um produto se torna, mais claramente ele precisa explicar o que faz, para quem é, como é implantado, quais são seus limites e quais resultados permite alcançar.
Para produtos de agentes de IA, serviços de modelos, ferramentas para desenvolvedores e infraestrutura de IA empresarial, a comunicação técnica não pode parar em nomes de modelos e números de benchmarks. As equipes precisam explicar claramente arquitetura, ambientes, métodos de avaliação, limitações e casos de uso reais.
Uma equipe que cria plataformas de treinamento de agentes ou serviços de implantação de modelos precisa de notas de arquitetura, casos de uso, FAQs, documentação de implantação, relatórios de avaliação e limites de segurança — não apenas uma breve introdução do produto.
Conclusão final
O valor do Qwen-AgentWorld não está apenas no fato de um modelo relatar uma pontuação maior do que outro. A mudança mais profunda é que o treinamento e a avaliação de agentes podem usar modelos de mundo baseados em linguagem como infraestrutura: simular ambientes, criar benchmarks fundamentados, expor fraquezas por meio de perturbações controláveis e transferir conhecimento de modelagem de mundo para tarefas de agentes mais difíceis.
Para desenvolvedores, é um poderoso simulador de ambientes para estudo. Para equipes de produto, aponta para o futuro da infraestrutura de agentes. Para equipes de IA empresarial, reforça outro ponto: quanto mais complexa a tecnologia, mais importantes se tornam notas claras de arquitetura, documentação e métodos de avaliação.
Perguntas frequentes
O Qwen-AgentWorld é um modelo de chat normal?
Não. Ele é melhor compreendido como um modelo de mundo linguístico que simula ambientes de agentes e prevê a próxima observação após uma ação.
Quais domínios o Qwen-AgentWorld cobre?
Ele cobre MCP, Pesquisa, Terminal, SWE, Web, SO e Android, abrangendo ambientes de texto e de GUI.
O Qwen-AgentWorld-35B-A3B pode ser implantado localmente?
Sim, mas requer hardware robusto para inferência de contexto longo. Os usuários devem reduzir a janela de contexto se atingirem limites de memória.
O que o AgentWorldBench avalia?
Ele avalia observações de ambiente previstas em Formato, Veracidade, Consistência, Realismo e Qualidade.
Por que isso é importante para as empresas?
Isso permite simulação, testes e avaliação de segurança de agentes de forma mais controlável antes que os agentes sejam expostos a ambientes operacionais reais.
Ferramentas relacionadas
• SGLang
• vLLM
Fontes
• Relatório técnico do Qwen-AgentWorld
• Qwen-AgentWorld-35B-A3B no Hugging Face
• Conjunto de dados AgentWorldBench