Qwen-AgentWorld 指南:語言世界模型如何改變 AI 代理的訓練、評估與部署
一份為開發者及 AI 產品團隊而重寫的實用 Qwen-AgentWorld 指南,涵蓋語言世界模型、七個代理互動領域、CPT/SFT/RL 訓練流程、AgentWorldBench、35B-A3B 及 397B-A17B 模型系列、SGLang/vLLM 部署,以及這項轉變對 AI 代理基建與評估的意義。

原文圖片:Qwen-AgentWorld 統一文字及 GUI 環境
Qwen-AgentWorld 最有趣之處,並不在於它又是一個更強大的 AI 代理。它將問題推向更深一層:如果代理需要在環境中學習,環境本身可否由語言模型建模?
傳統代理依賴真實瀏覽器、終端機、程式碼倉庫、流動應用程式及桌面環境進行訓練和評估。這樣做很真實,但成本高、難以快速擴展,而且難以控制。Qwen-AgentWorld 使用語言世界模型來模擬這些環境,讓代理可以在更可控、以語言為基礎的世界中接受訓練和測試。
這意味住 Qwen-AgentWorld 不只是一個聊天機械人,也不單純是一個自主代理。更準確地說,它是面向 AI 代理的環境模擬基礎設施。
為何語言世界模型重要
代理工作的難點不只在於模型能否回答。真正困難的是預測一個動作之後會發生甚麼。一次網頁點擊、一條終端機指令、一次程式碼編輯、一次 MCP 工具調用,或一個 Android 手勢,都會改變環境狀態。
如果每個訓練步驟都依賴真實環境,成本會很高,結果亦更難重現。語言世界模型嘗試根據當前上下文及代理動作,預測下一個觀察結果。
• 降低訓練成本:每條軌跡所需啟動的真實環境更少。
• 更可控的評估:可以安全地注入擾動及虛構世界。
• 更清晰的遷移:不同領域都變成狀態—動作—下一狀態建模的變體。
七個領域:由文字工具到 GUI 環境
原文圖片:Qwen-AgentWorld 涵蓋 MCP、搜尋、IDE/SWE、終端機、網頁、OS 及 Android
Qwen-AgentWorld 涵蓋 MCP、搜尋、終端機、SWE、網頁、OS 及 Android。前四項較接近文字環境;後三項則以 GUI 為中心。
領域 | 類型 | 可模擬內容 |
MCP | 文字工具 | 工具調用、函數返回、服務狀態變化 |
搜尋 | 文字環境 | 搜尋結果、摘要片段、排名及答案洩漏風險 |
終端機 | 命令列 | Shell 輸出、檔案系統狀態、程序行為 |
SWE | colspan="1" rowspan="1"> 軟件工程 | 代碼編輯、測試、修補程式及錯誤訊息 |
網頁 | 圖形用戶介面 | 瀏覽器 DOM 狀態、表單、按鈕及導覽 |
作業系統 | 圖形用戶介面 | 桌面視窗、檔案、應用程式及系統狀態 |
Android | 圖形用戶介面 | 流動用戶介面樹,以及觸控操作後的狀態 |
其價值在於,團隊毋須為每個環境建立獨立模擬器。相反,模型會學習一種以語言為基礎、可跨領域表示狀態轉移的方式。
原生世界模型,而非事後適配
「原生」一詞很重要。Qwen-AgentWorld 並非被描述成一個通用 LLM,再加上幾個代理提示詞作修補。從持續預訓練階段開始,環境建模已內建於訓練目標之中。
維度 | 事後 LLM 適配 | Qwen-AgentWorld |
訓練目標 | 先學一般語言,之後才學代理行為 | 由 CPT 起學習環境狀態轉移 |
流程 | 大多是在訓練後進行 SFT 或 RL | CPT -> SFT -> RL |
知識注入 | 提示詞及數據增強 | 環境動態嵌入模型權重之中 |
覆蓋範圍 | 通常只有一個或少數幾個領域 | 單一模型涵蓋七個領域 |
CPT 注入環境動態,SFT 啟動下一狀態預測推理,而 RL 則提升格式、事實準確性、一致性、真實感及整體質素。
模型與基準測試:細閱數字
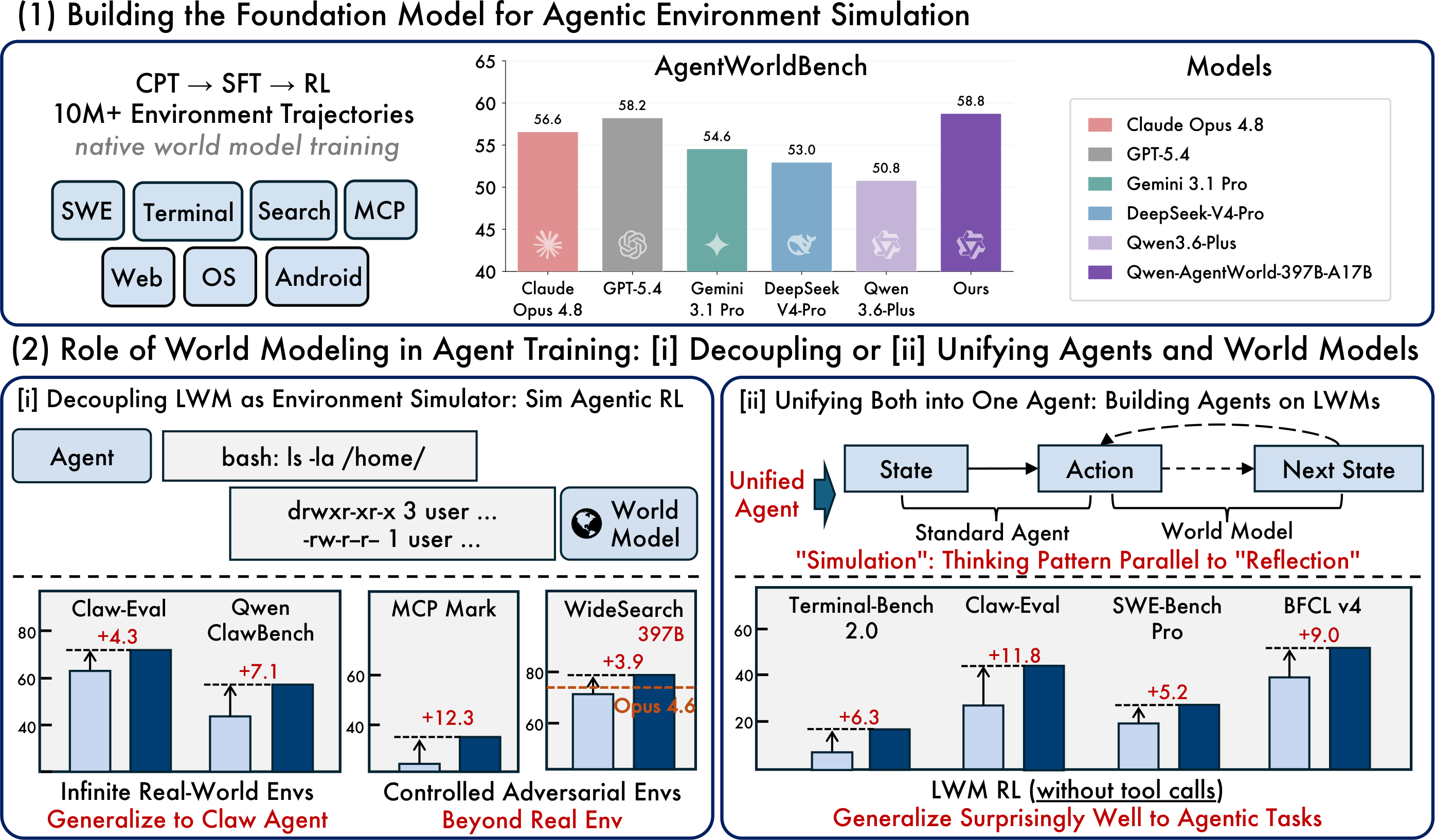
原文圖片:基礎模型、模擬 RL 及統一代理範式
最實用的開源版本是 Qwen-AgentWorld-35B-A3B,這是一個總參數 35B、活躍參數 3B 的 MoE 模型,預設上下文長度為 262K tokens。研究旗艦版 Qwen-AgentWorld-397B-A17B 則達到 Qwen 所報告的更高 AgentWorldBench 分數。
項目 | 說明 |
Qwen-AgentWorld-35B-A3B | 開放模型權重,供開發者下載、部署及測試 |
Qwen-AgentWorld-397B-A17B | 研究旗艦模型,據報基準測試分數更高 |
AgentWorldBench | 涵蓋七個領域的基準測試,具備來自真實環境執行的真值觀察結果 |
評估維度 | 格式、事實性、一致性、真實感及質素 |
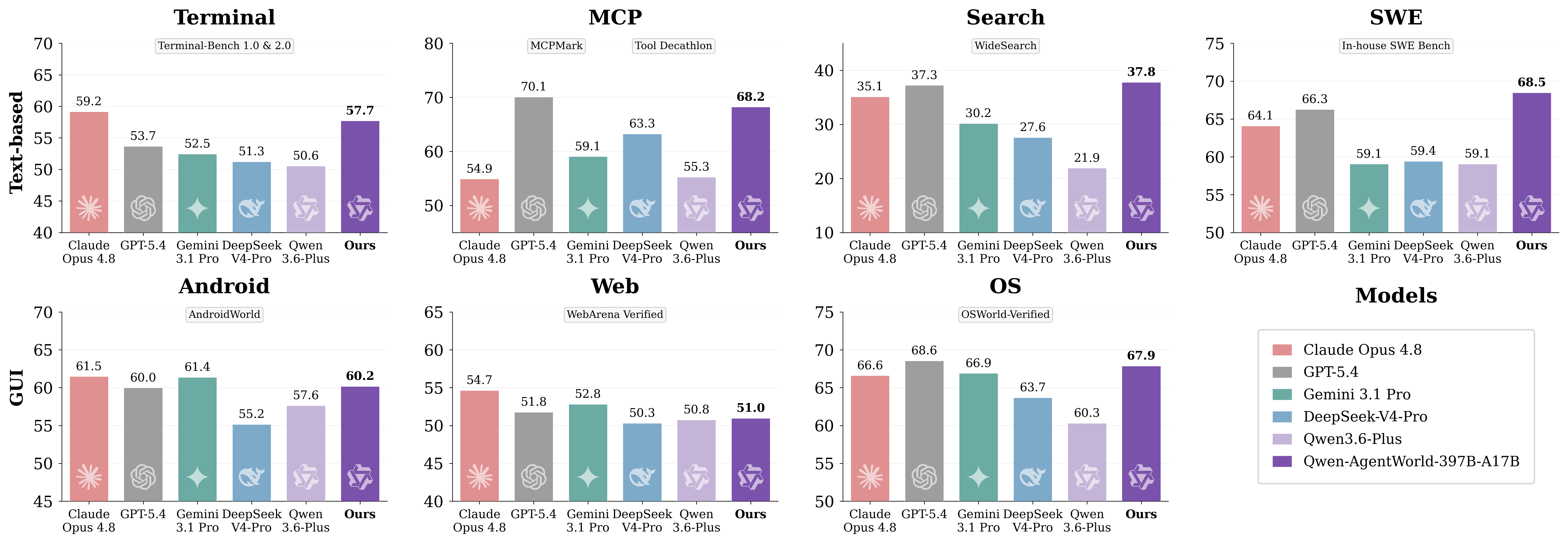
原文圖片:AgentWorldBench 領域級結果
關鍵在於不要把這個基準測試視為通用聊天機械人排名。AgentWorldBench 衡量的是環境模擬質素。對開發者而言,實際問題是該模型能否有助建立更可靠的智能體訓練、評估及回歸測試工作流程。
部署:可以快速開始,但硬件仍然重要
原文強調快速部署。當 GPU、驅動程式、Python 環境及推理框架都已準備好時,這確實成立。對一般用戶而言,真正的瓶頸是 VRAM、長上下文及多 GPU 服務。
官方指引支援 SGLang、vLLM、Transformers 及兼容 OpenAI 的 API 調用。對於伺服器式使用,SGLang 或 vLLM 是更清晰的路徑。
# SGLang 範例 pip install sglang python -m sglang.launch_server \ --model-path Qwen/Qwen-AgentWorld-35B-A3B \ --port 8000 \ --tp-size 4 \ --context-length 262144 \ --reasoning-parser qwen3
# vLLM 範例 pip install vllm vllm serve Qwen/Qwen-AgentWorld-35B-A3B \ --port 8000 \ --tensor-parallel-size 4 \ --max-model-len 262144 \ --reasoning-parser qwen3 \ --language-model-only \ --trust-remote-code
實際使用時,若出現 OOM,應先降低上下文長度;為多 GPU 部署確認張量並行設定;如果目標只是小型概念驗證,則避免強行使用 256K 上下文窗口。
誰應該關注 Qwen-AgentWorld?
• 智能體研究人員可以研究世界建模、模擬環境及智能體強化學習。
• AI 工程團隊可以為工具、終端機、瀏覽器、操作系統及流動環境建立模擬測試。
• 企業 AI 產品團隊可以了解智能體基礎設施如何由「答案」轉向具環境感知的推理。
如果你的目標是簡單寫作、聊天或一般程式碼補全,這並不是最直接的模型。它的價值更偏向基礎層面:為智能體動作與環境變化之間的因果關係建模。
這對企業 AI 基礎設施意味著甚麼
像 Qwen-AgentWorld 這類項目顯示,AI 智能體基礎設施正超越示範階段。但產品越技術化,就越需要清楚說明它做甚麼、為誰而設、如何部署、有甚麼限制,以及能帶來甚麼成果。
對於 AI 智能體產品、模型服務、開發者工具及企業 AI 基礎設施,技術溝通不能只停留在模型名稱和基準測試數字。團隊需要清晰解釋架構、環境、評估方法、限制及真實用例。
建立智能體訓練平台或模型部署服務的團隊,需要架構說明、用例、常見問題、部署文件、評估報告及安全邊界——而不只是簡短的產品介紹。
最後重點
Qwen-AgentWorld 的價值不僅在於某個模型報告的分數高於另一個模型。更深層的轉變是,智能體訓練及評估可以把語言世界模型用作基礎設施:模擬環境、建立有根據的基準測試、透過可控擾動暴露弱點,並將世界建模知識轉移至更艱深的智能體任務。
對開發人員而言,這是一個強大的環境模擬器,值得研究。對產品團隊而言,它指向代理基礎設施的未來。對企業 AI 團隊而言,它進一步強調一點:技術越複雜,清晰的架構說明、文件及評估方法就越重要。
常見問題
Qwen-AgentWorld 是一般聊天模型嗎?
不是。更準確來說,它是一個語言世界模型,用於模擬代理環境,並預測執行動作後的下一個觀察結果。
Qwen-AgentWorld 涵蓋哪些領域?
它涵蓋 MCP、搜尋、終端機、SWE、網頁、OS 及 Android,橫跨文字及 GUI 環境。
Qwen-AgentWorld-35B-A3B 可以在本地部署嗎?
可以,但長上下文推理需要相當高規格的硬件。如果用戶遇到記憶體限制,應降低上下文視窗大小。
AgentWorldBench 評估甚麼?
它會從格式、事實性、一致性、真實感及質素等方面,評估預測的環境觀察結果。
為甚麼這對企業重要?
它讓代理在接觸真實營運環境之前,能夠進行更可控的代理模擬、測試及安全評估。
相關工具
• Qwen 網誌
• SGLang
• vLLM
來源
• CSDN 原文
• Hugging Face 上的 Qwen-AgentWorld-35B-A3B