Qwen-AgentWorld 指南:语言世界模型如何改变 AI 智能体的训练、评估与部署
一份面向开发者和 AI 产品团队的 Qwen-AgentWorld 实用改写指南,涵盖语言世界模型、七大智能体交互领域、CPT/SFT/RL 训练流水线、AgentWorldBench、35B-A3B 与 397B-A17B 模型家族、SGLang/vLLM 部署,以及这一转变对 AI 智能体基础设施和评估意味着什么。

原文图片:Qwen-AgentWorld 统一文本与 GUI 环境
Qwen-AgentWorld 最有趣的地方,并不在于它又是一个更强的 AI 智能体。它把问题向更深一层推进:如果智能体需要在环境中学习,那么环境本身能否由语言模型来建模?
传统智能体依赖真实浏览器、终端、代码仓库、移动应用和桌面环境进行训练与评估。这很现实,但成本高、难以规模化,而且不易控制。Qwen-AgentWorld 使用语言世界模型来模拟这些环境,因此智能体可以在一个更可控的、基于语言的世界中进行训练和测试。
这意味着 Qwen-AgentWorld 不只是一个聊天机器人,也不只是一个自主智能体。更准确地说,它是面向 AI 智能体的环境模拟基础设施。
为什么语言世界模型很重要
智能体工作的难点不只是模型能否回答。真正困难的是预测一个动作之后会发生什么。一次网页点击、一条终端命令、一次代码编辑、一次 MCP 工具调用或一个 Android 手势,都会改变环境状态。
如果每个训练步骤都依赖真实环境,成本会很高,结果也更难复现。语言世界模型试图根据当前上下文和智能体动作,预测下一次观察结果。
• 降低训练成本:每条轨迹所需启动的真实环境更少。
• 更可控的评估:可以安全地注入扰动和虚构世界。
• 更清晰的迁移:不同领域会变成“状态-动作-下一状态”建模的变体。
七个领域:从文本工具到 GUI 环境
原文图片:Qwen-AgentWorld 涵盖 MCP、搜索、IDE/SWE、终端、Web、OS 和 Android
Qwen-AgentWorld 涵盖 MCP、搜索、终端、SWE、Web、OS 和 Android。前四个更接近文本环境;后三个则以 GUI 为中心。
领域 | 类型 | 它可以模拟什么 |
MCP | 文本工具 | 工具调用、函数返回、服务状态变化 |
搜索 | 文本环境 | 搜索结果、摘要片段、排序和答案泄露风险 |
终端 | 命令行 | Shell 输出、文件系统状态、进程行为 |
SWE | 软件工程 | 代码编辑、测试、补丁和错误消息 |
Web | 图形用户界面 | 浏览器 DOM 状态、表单、按钮和导航 |
操作系统 | 图形用户界面 | 桌面窗口、文件、应用和系统状态 |
Android | 图形用户界面 | 触控操作后的移动端 UI 树和状态 |
其价值在于,团队不需要为每个环境单独构建模拟器。相反,模型会学习一种基于语言的状态转换表示,适用于不同领域。
原生世界模型,而非事后适配
“原生”一词很重要。Qwen-AgentWorld 并不是一个通用 LLM 再打上几个智能体提示词补丁。环境建模从持续预训练阶段开始就被纳入训练目标。
维度 | 事后 LLM 适配 | Qwen-AgentWorld |
训练目标 | 先通用语言,后智能体行为 | 从 CPT 开始进行环境状态转换 |
流程 | 主要是在训练后进行 SFT 或 RL | CPT -> SFT -> RL |
知识注入 | 提示词和数据增强 | 环境动态嵌入模型权重 |
覆盖范围 | 通常是一个或少数几个领域 | 一个模型覆盖七个领域 |
CPT 注入环境动态,SFT 激活下一状态预测推理,而 RL 则提升格式、事实性、一致性、真实感和整体质量。
模型和基准:谨慎解读数字
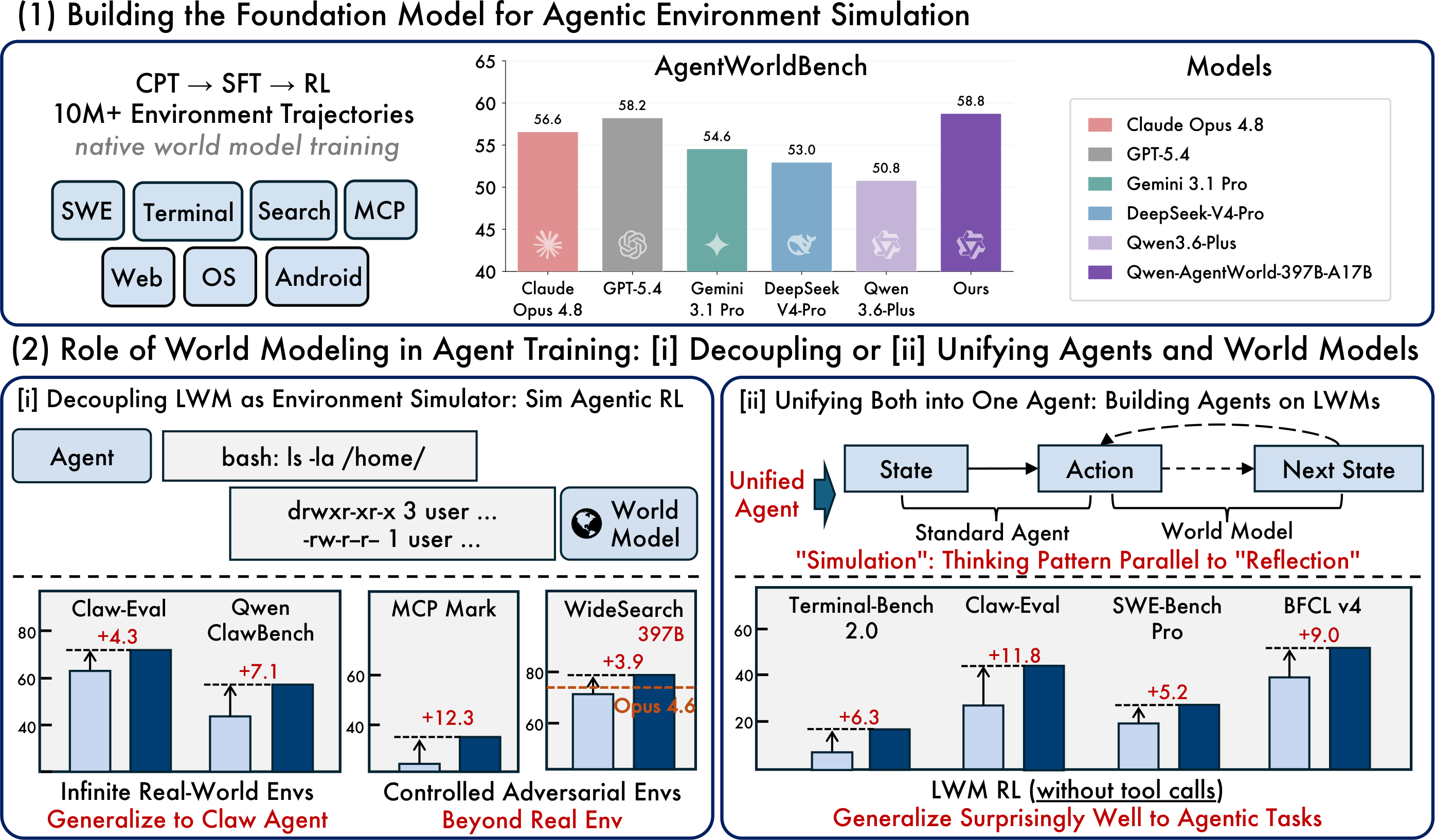
原文配图:基础模型、模拟 RL 与统一智能体范式
最实用的开放版本是 Qwen-AgentWorld-35B-A3B,这是一个总参数 35B / 激活参数 3B 的 MoE 模型,默认上下文长度为 262K token。研究旗舰版 Qwen-AgentWorld-397B-A17B 则取得了 Qwen 报告的更高 AgentWorldBench 分数。
项目 | 说明 |
Qwen-AgentWorld-35B-A3B | 面向开发者开放模型权重,可下载、部署和测试 |
Qwen-AgentWorld-397B-A17B | 研究旗舰模型,报告的基准测试得分更强 |
AgentWorldBench | 一个覆盖七个领域的基准测试,包含来自真实环境执行的真值观测 |
评估维度 | 格式、事实性、一致性、真实性和质量 |
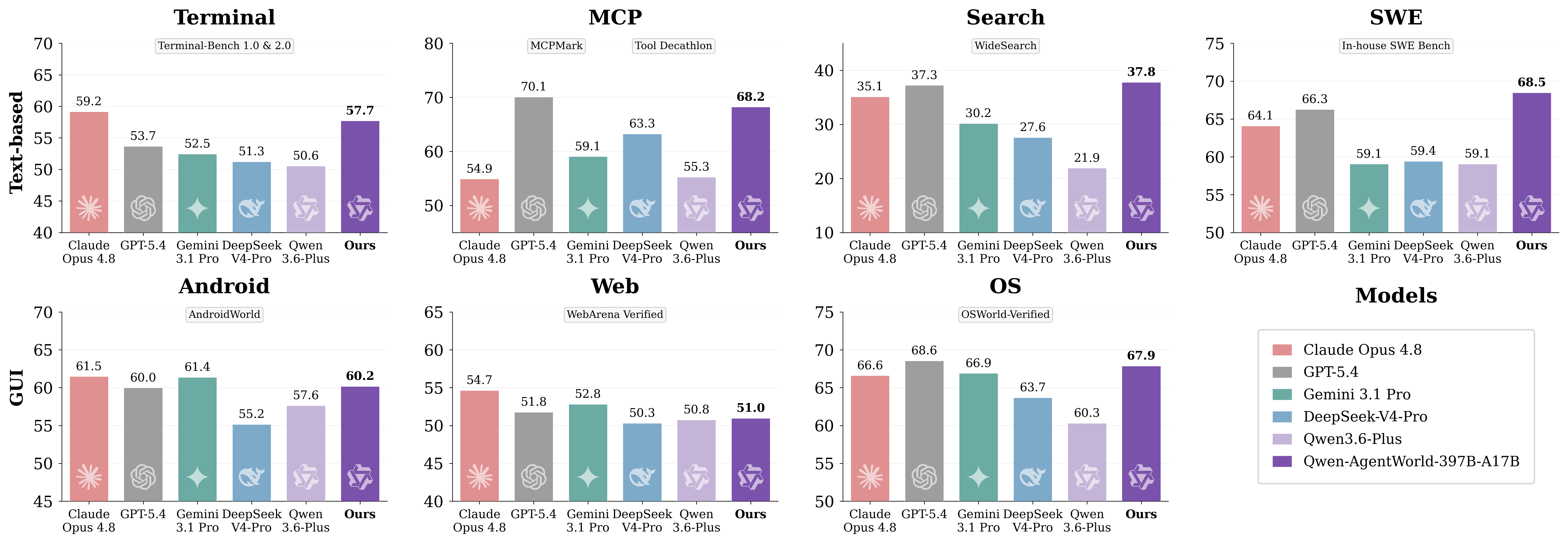
原文图片:AgentWorldBench 领域级结果
关键在于不要把该基准测试当作通用聊天机器人排名。AgentWorldBench 衡量的是环境模拟质量。对于开发者来说,实际问题是该模型是否有助于构建更可靠的智能体训练、评估和回归测试工作流。
部署:可以快速启动,但硬件仍然很重要
原文强调了快速部署。如果 GPU、驱动、Python 环境和推理框架已经准备好,这确实成立。对于普通用户来说,真正的瓶颈是显存、长上下文和多 GPU 服务部署。
官方说明支持 SGLang、vLLM、Transformers 和 OpenAI 兼容 API 调用。对于服务器式使用,SGLang 或 vLLM 是更简洁的路径。
# SGLang 示例 pip install sglang python -m sglang.launch_server \ --model-path Qwen/Qwen-AgentWorld-35B-A3B \ --port 8000 \ --tp-size 4 \ --context-length 262144 \ --reasoning-parser qwen3
# vLLM 示例 pip install vllm vllm serve Qwen/Qwen-AgentWorld-35B-A3B \ --port 8000 \ --tensor-parallel-size 4 \ --max-model-len 262144 \ --reasoning-parser qwen3 \ --language-model-only \ --trust-remote-code
在实践中,当出现 OOM 时,首先降低上下文长度;为多 GPU 部署确认张量并行设置;如果你的目标只是一个小型概念验证,就不要强行使用 256K 上下文窗口。
谁应该关注 Qwen-AgentWorld?
• 智能体研究人员可以研究世界建模、模拟环境和智能体强化学习。
• AI 工程团队可以为工具、终端、浏览器、操作系统和移动环境构建模拟测试。
• 企业 AI 产品团队可以了解智能体基础设施如何从“回答”走向具备环境感知的推理。
如果你的目标是简单写作、聊天或常规代码补全,这并不是最直接的模型。它的价值更具基础性:建模智能体动作与环境变化之间的因果关系。
这对企业 AI 基础设施意味着什么
像 Qwen-AgentWorld 这样的项目表明,AI 智能体基础设施正在超越演示阶段。但产品越技术化,就越需要清楚说明它做什么、面向谁、如何部署、有哪些限制,以及能够带来什么结果。
对于 AI 智能体产品、模型服务、开发者工具和企业 AI 基础设施,技术沟通不能止步于模型名称和基准测试数字。团队需要清晰说明架构、环境、评估方法、局限性和真实使用场景。
构建智能体训练平台或模型部署服务的团队需要架构说明、使用场景、常见问题、部署文档、评估报告和安全边界,而不仅仅是一段简短的产品介绍。
最终要点
Qwen-AgentWorld 的价值不只是某个模型报告的分数高于另一个模型。更深层的转变在于,智能体训练和评估可以将语言世界模型作为基础设施:模拟环境、构建有依据的基准测试、通过可控扰动暴露弱点,并将世界建模知识迁移到更困难的智能体任务中。
对于开发者而言,它是一个值得研究的强大环境模拟器。对于产品团队而言,它指向了智能体基础设施的未来。对于企业 AI 团队而言,它进一步强调了另一点:技术越复杂,清晰的架构说明、文档和评估方法就越重要。
常见问题
Qwen-AgentWorld 是普通聊天模型吗?
不是。更准确地说,它是一个语言世界模型,用于模拟智能体环境,并预测执行动作后的下一步观察结果。
Qwen-AgentWorld 覆盖哪些领域?
它覆盖 MCP、搜索、终端、SWE、Web、OS 和 Android,涵盖文本环境和 GUI 环境。
Qwen-AgentWorld-35B-A3B 可以本地部署吗?
可以,但它需要强大的硬件来进行长上下文推理。如果遇到内存限制,用户应降低上下文窗口大小。
AgentWorldBench 评估什么?
它从格式、事实性、一致性、真实性和质量等方面评估预测的环境观察结果。
为什么这对企业很重要?
它支持在智能体暴露于真实运营环境之前,进行更可控的智能体模拟、测试和安全评估。
相关工具
• Qwen 博客
• SGLang
• vLLM
来源
• CSDN 原文
• Hugging Face 上的 Qwen-AgentWorld-35B-A3B