Guía de Qwen-AgentWorld: cómo los modelos de mundo lingüísticos transforman el entrenamiento, la evaluación y el despliegue de agentes de IA
Una guía práctica reescrita de Qwen-AgentWorld para desarrolladores y equipos de producto de IA, que aborda los modelos de mundo lingüísticos, siete dominios de interacción de agentes, el flujo de entrenamiento CPT/SFT/RL, AgentWorldBench, la familia de modelos 35B-A3B y 397B-A17B, el despliegue con SGLang/vLLM y lo que este cambio implica para la infraestructura y la evaluación de agentes de IA.

Imagen del artículo original: Qwen-AgentWorld unifica entornos de texto y GUI
Lo más interesante de Qwen-AgentWorld no es que sea otro agente de IA más potente. Lleva el problema a una capa más profunda: si los agentes necesitan aprender dentro de entornos, ¿puede el propio entorno ser modelado por un modelo de lenguaje?
Los agentes tradicionales dependen de navegadores reales, terminales, repositorios de código, aplicaciones móviles y entornos de escritorio para el entrenamiento y la evaluación. Eso es realista, pero es costoso, difícil de escalar y complicado de controlar. Qwen-AgentWorld utiliza un modelo de mundo lingüístico para simular estos entornos, de modo que los agentes puedan entrenarse y probarse en un mundo basado en lenguaje más controlable.
Eso significa que Qwen-AgentWorld no es solo un chatbot ni simplemente un agente autónomo. Se entiende mejor como infraestructura de simulación de entornos para agentes de IA.
Por qué importan los modelos de mundo lingüísticos
La parte difícil del trabajo con agentes no es solo si el modelo puede responder. La parte difícil es predecir qué ocurre después de una acción. Un clic web, un comando de terminal, una edición de código, una llamada a una herramienta MCP o un gesto en Android cambian el estado del entorno.
Si cada paso de entrenamiento depende de entornos reales, el coste es alto y los resultados son más difíciles de reproducir. Un modelo de mundo lingüístico intenta predecir la siguiente observación a partir del contexto actual y la acción del agente.
• Menor coste de entrenamiento: menos ejecuciones de entornos reales para cada trayectoria.
• Evaluación más controlada: se pueden introducir perturbaciones y mundos ficticios de forma segura.
• Transferencia más limpia: diferentes dominios se convierten en variaciones del modelado estado-acción-siguiente estado.
Siete dominios: desde herramientas de texto hasta entornos GUI
Imagen del artículo original: Qwen-AgentWorld cubre MCP, búsqueda, IDE/SWE, terminal, web, sistema operativo y Android
Qwen-AgentWorld cubre MCP, búsqueda, terminal, SWE, web, sistema operativo y Android. Los cuatro primeros están más cerca de los entornos de texto; los tres últimos son entornos centrados en GUI.
Dominio | Tipo | Qué puede simular |
MCP | Herramienta de texto | Llamadas a herramientas, retornos de funciones, cambios de estado del servicio |
Búsqueda | Entorno de texto | Resultados de búsqueda, fragmentos, clasificación y riesgos de filtración de respuestas |
Terminal | Línea de comandos | Salida de shell, estado del sistema de archivos, comportamiento de procesos |
SWE | Ingeniería de software | Ediciones de código, pruebas, parches y mensajes de error |
Web | GUI | Estado del DOM del navegador, formularios, botones y navegación |
SO | GUI | Ventanas de escritorio, archivos, aplicaciones y estado del sistema |
Android | GUI | Árboles de interfaz móvil y estado tras acciones táctiles |
El valor reside en que los equipos no necesitan un simulador independiente para cada entorno. En su lugar, el modelo aprende una representación basada en lenguaje de las transiciones de estado entre dominios.
Modelo del mundo nativo, no adaptación a posteriori
La palabra “nativo” importa. Qwen-AgentWorld no se presenta como un LLM de propósito general parcheado con unas cuantas instrucciones para agentes. El modelado del entorno está integrado en el objetivo de entrenamiento desde la etapa de preentrenamiento continuo en adelante.
Dimensión | Adaptación a posteriori de LLM | Qwen-AgentWorld |
Objetivo de entrenamiento | Primero lenguaje general, después comportamiento de agente | Transición de estado del entorno desde el CPT en adelante |
Canalización | Principalmente SFT o RL después del entrenamiento | CPT -> SFT -> RL |
Inyección de conocimiento | Prompts y aumento de datos | Dinámicas del entorno incorporadas en los pesos del modelo |
Cobertura | A menudo uno o unos pocos dominios | Siete dominios en un solo modelo |
El CPT inyecta dinámicas del entorno, el SFT activa el razonamiento de predicción del siguiente estado y el RL mejora el formato, la factualidad, la coherencia, el realismo y la calidad general.
Modelos y benchmarks: lee las cifras con atención
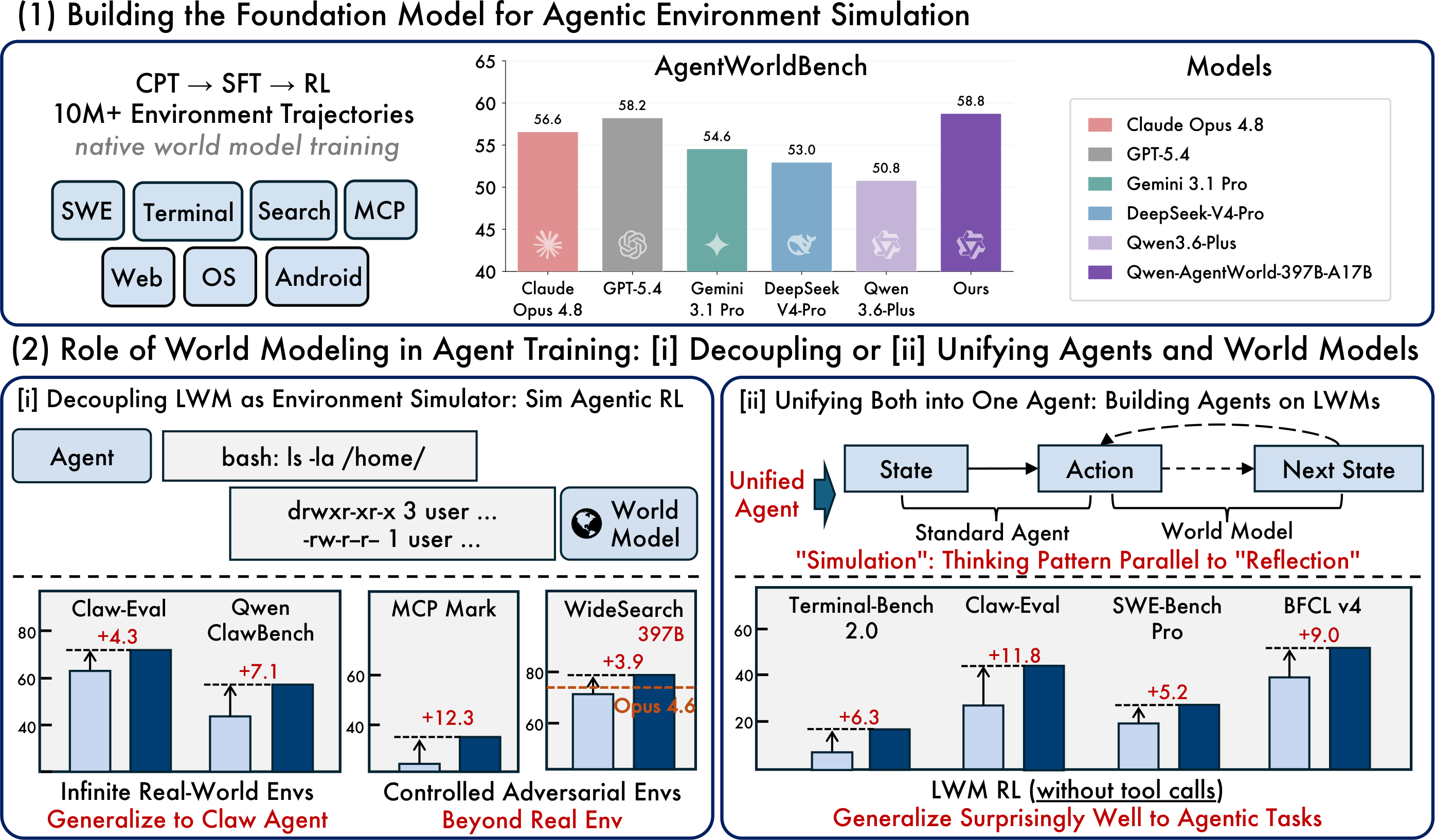
Imagen del artículo original: modelo fundacional, RL simulado y paradigmas de agentes unificados
La versión abierta más práctica es Qwen-AgentWorld-35B-A3B, un modelo MoE de 35B en total / 3B activos con una longitud de contexto predeterminada de 262K tokens. El buque insignia de investigación, Qwen-AgentWorld-397B-A17B, alcanza la puntuación más alta en AgentWorldBench reportada por Qwen.
Elemento | Explicación |
Qwen-AgentWorld-35B-A3B | Pesos de modelo abiertos para que los desarrolladores los descarguen, sirvan y prueben |
Qwen-AgentWorld-397B-A17B | Modelo insignia de investigación con una puntuación de referencia reportada más alta |
AgentWorldBench | Un benchmark de siete dominios con observaciones de referencia reales obtenidas de la ejecución en entornos reales |
Dimensiones de evaluación | Formato, factualidad, coherencia, realismo y calidad |
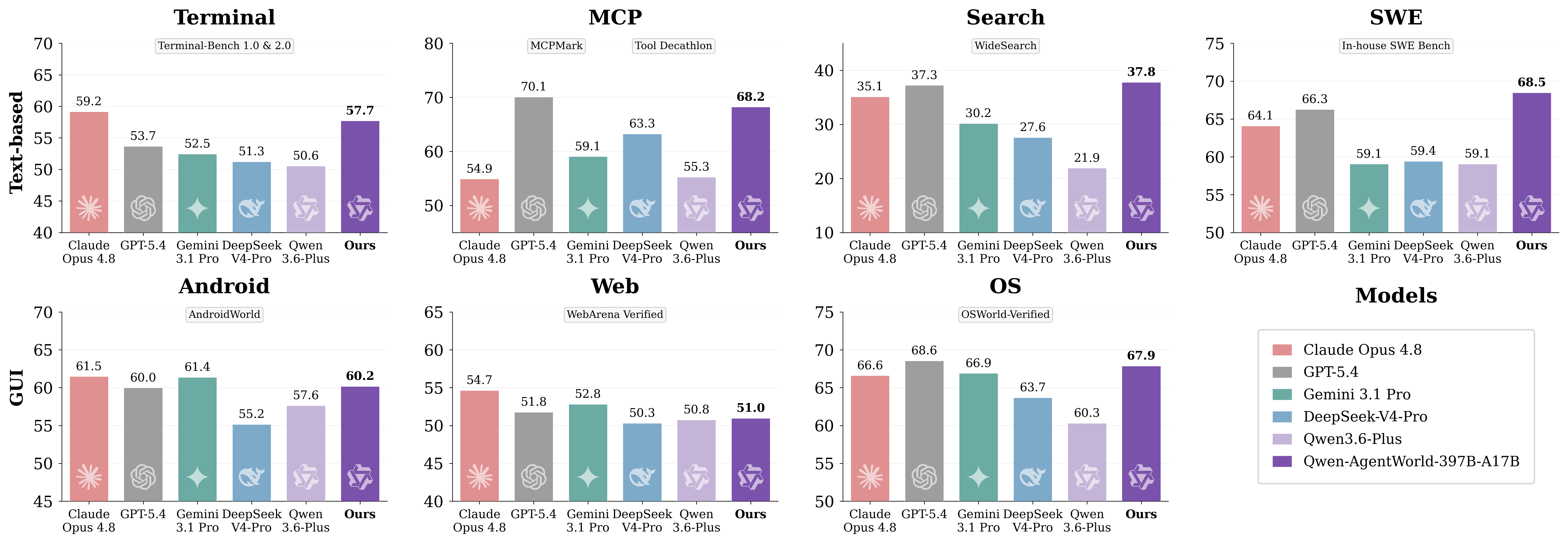
Imagen del artículo original: resultados de AgentWorldBench a nivel de dominio
La clave es no tratar el benchmark como una clasificación universal de chatbots. AgentWorldBench mide la calidad de la simulación de entornos. Para los desarrolladores, la pregunta práctica es si el modelo ayuda a crear flujos de trabajo más fiables para el entrenamiento, la evaluación y las pruebas de regresión de agentes.
Implementación: puede empezar rápido, pero el hardware sigue importando
El artículo original enfatiza la implementación rápida. Eso es cierto cuando la GPU, los controladores, el entorno de Python y el framework de inferencia ya están preparados. Para los usuarios normales, los verdaderos cuellos de botella son la VRAM, el contexto largo y el servicio multi-GPU.
Las instrucciones oficiales admiten SGLang, vLLM, Transformers y llamadas API compatibles con OpenAI. Para un uso tipo servidor, SGLang o vLLM es la vía más limpia.
# Ejemplo de SGLang pip install sglang python -m sglang.launch_server \ --model-path Qwen/Qwen-AgentWorld-35B-A3B \ --port 8000 \ --tp-size 4 \ --context-length 262144 \ --reasoning-parser qwen3
# Ejemplo de vLLM pip install vllm vllm serve Qwen/Qwen-AgentWorld-35B-A3B \ --port 8000 \ --tensor-parallel-size 4 \ --max-model-len 262144 \ --reasoning-parser qwen3 \ --language-model-only \ --trust-remote-code
En la práctica, reduce primero la longitud de contexto cuando aparezca un error OOM, confirma la configuración de paralelismo tensorial para implementaciones multi-GPU y evita forzar una ventana de contexto de 256K si tu objetivo es solo una pequeña prueba de concepto.
¿A quién debería importarle Qwen-AgentWorld?
• Los investigadores de agentes pueden estudiar el modelado del mundo, los entornos simulados y el aprendizaje por refuerzo de agentes.
• Los equipos de ingeniería de IA pueden crear pruebas de simulación para herramientas, terminales, navegadores, sistemas operativos y entornos móviles.
• Los equipos de productos de IA empresarial pueden entender cómo la infraestructura de agentes está pasando de las “respuestas” al razonamiento consciente del entorno.
Si tu objetivo es la escritura sencilla, el chat o la finalización de código normal, este no es el modelo más directo. Su valor es más fundamental: modelar la causalidad entre las acciones de los agentes y los cambios del entorno.
Qué significa esto para la infraestructura de IA empresarial
Proyectos como Qwen-AgentWorld muestran que la infraestructura de agentes de IA está yendo más allá de las demostraciones. Pero cuanto más técnico se vuelve un producto, con más claridad debe explicar qué hace, para quién es, cómo se implementa, cuáles son sus límites y qué resultados permite obtener.
Para productos de agentes de IA, servicios de modelos, herramientas para desarrolladores e infraestructura de IA empresarial, la comunicación técnica no puede limitarse a nombres de modelos y cifras de benchmarks. Los equipos deben explicar con claridad la arquitectura, los entornos, los métodos de evaluación, las limitaciones y los casos de uso reales.
Un equipo que construye plataformas de entrenamiento de agentes o servicios de implementación de modelos necesita notas de arquitectura, casos de uso, preguntas frecuentes, documentación de implementación, informes de evaluación y límites de seguridad, no solo una breve introducción del producto.
Conclusión final
El valor de Qwen-AgentWorld no reside solo en que un modelo reporte una puntuación más alta que otro. El cambio más profundo es que el entrenamiento y la evaluación de agentes pueden usar modelos lingüísticos del mundo como infraestructura: simular entornos, crear benchmarks fundamentados, exponer debilidades mediante perturbaciones controlables y transferir conocimientos de modelado del mundo a tareas de agentes más difíciles.
Para los desarrolladores, es un potente simulador de entornos para estudiar. Para los equipos de producto, apunta al futuro de la infraestructura de agentes. Para los equipos de IA empresarial, refuerza otro punto: cuanto más compleja es la tecnología, más importantes se vuelven las notas claras de arquitectura, la documentación y los métodos de evaluación.
Preguntas frecuentes
¿Qwen-AgentWorld es un modelo de chat normal?
No. Se entiende mejor como un modelo de mundo lingüístico que simula entornos de agentes y predice la siguiente observación después de una acción.
¿Qué dominios cubre Qwen-AgentWorld?
Cubre MCP, Search, Terminal, SWE, Web, OS y Android, abarcando tanto entornos de texto como de interfaz gráfica.
¿Se puede implementar Qwen-AgentWorld-35B-A3B localmente?
Sí, pero requiere hardware considerable para la inferencia de contexto largo. Los usuarios deberían reducir la ventana de contexto si se encuentran con límites de memoria.
¿Qué evalúa AgentWorldBench?
Evalúa las observaciones de entorno predichas en formato, factualidad, coherencia, realismo y calidad.
¿Por qué esto importa a las empresas?
Permite una simulación de agentes, pruebas y evaluación de seguridad más controlables antes de exponer los agentes a entornos operativos reales.
Herramientas relacionadas
• SGLang
• vLLM
Fuentes
• Informe técnico de Qwen-AgentWorld
• Qwen-AgentWorld-35B-A3B en Hugging Face
• Conjunto de datos AgentWorldBench