Qwen-AgentWorld Guide: How Language World Models Change AI Agent Training, Evaluation, and Deployment
A practical rewritten guide to Qwen-AgentWorld for developers and AI product teams, covering language world models, seven agent interaction domains, the CPT/SFT/RL training pipeline, AgentWorldBench, the 35B-A3B and 397B-A17B model family, SGLang/vLLM deployment, and what this shift means for AI agent infrastructure and evaluation.

Original article image: Qwen-AgentWorld unifies text and GUI environments
The most interesting part of Qwen-AgentWorld is not that it is another stronger AI agent. It moves the problem one layer deeper: if agents need to learn inside environments, can the environment itself be modeled by a language model?
Traditional agents rely on real browsers, terminals, code repositories, mobile apps, and desktop environments for training and evaluation. That is realistic, but it is expensive, slow to scale, and hard to control. Qwen-AgentWorld uses a language world model to simulate these environments, so agents can be trained and tested in a more controllable language-based world.
That means Qwen-AgentWorld is not just a chatbot and not simply an autonomous agent. It is better understood as environment simulation infrastructure for AI agents.
Why language world models matter
The hard part of agent work is not only whether the model can answer. The hard part is predicting what happens after an action. A web click, terminal command, code edit, MCP tool call, or Android gesture all change the environment state.
If every training step depends on real environments, the cost is high and the results are harder to reproduce. A language world model tries to predict the next observation from the current context and the agent action.
• Lower training cost: fewer real environment launches for every trajectory.
• More controlled evaluation: perturbations and fictional worlds can be injected safely.
• Cleaner transfer: different domains become variations of state-action-next-state modeling.
Seven domains: from text tools to GUI environments
Original article image: Qwen-AgentWorld covers MCP, Search, IDE/SWE, Terminal, Web, OS, and Android
Qwen-AgentWorld covers MCP, Search, Terminal, SWE, Web, OS, and Android. The first four are closer to text environments; the last three are GUI-centered environments.
Domain | Type | What it can simulate |
MCP | Text tool | Tool calls, function returns, service state changes |
Search | Text environment | Search results, snippets, ranking and answer leakage risks |
Terminal | Command line | Shell output, file system state, process behavior |
SWE | Software engineering | Code edits, tests, patches and error messages |
Web | GUI | Browser DOM state, forms, buttons and navigation |
OS | GUI | Desktop windows, files, apps and system state |
Android | GUI | Mobile UI trees and state after touch actions |
The value is that teams do not need a separate simulator for every environment. Instead, the model learns a language-based representation of state transitions across domains.
Native world model, not post-hoc adaptation
The word “native” matters. Qwen-AgentWorld is not presented as a general-purpose LLM patched with a few agent prompts. Environment modeling is built into the training objective from the continual pre-training stage onward.
Dimension | Post-hoc LLM adaptation | Qwen-AgentWorld |
Training objective | General language first, agent behavior later | Environment state transition from CPT onward |
Pipeline | Mostly SFT or RL after training | CPT -> SFT -> RL |
Knowledge injection | Prompting and data augmentation | Environment dynamics embedded into model weights |
Coverage | Often one or a few domains | Seven domains in one model |
CPT injects environment dynamics, SFT activates next-state-prediction reasoning, and RL improves format, factuality, consistency, realism, and overall quality.
Models and benchmarks: read the numbers carefully
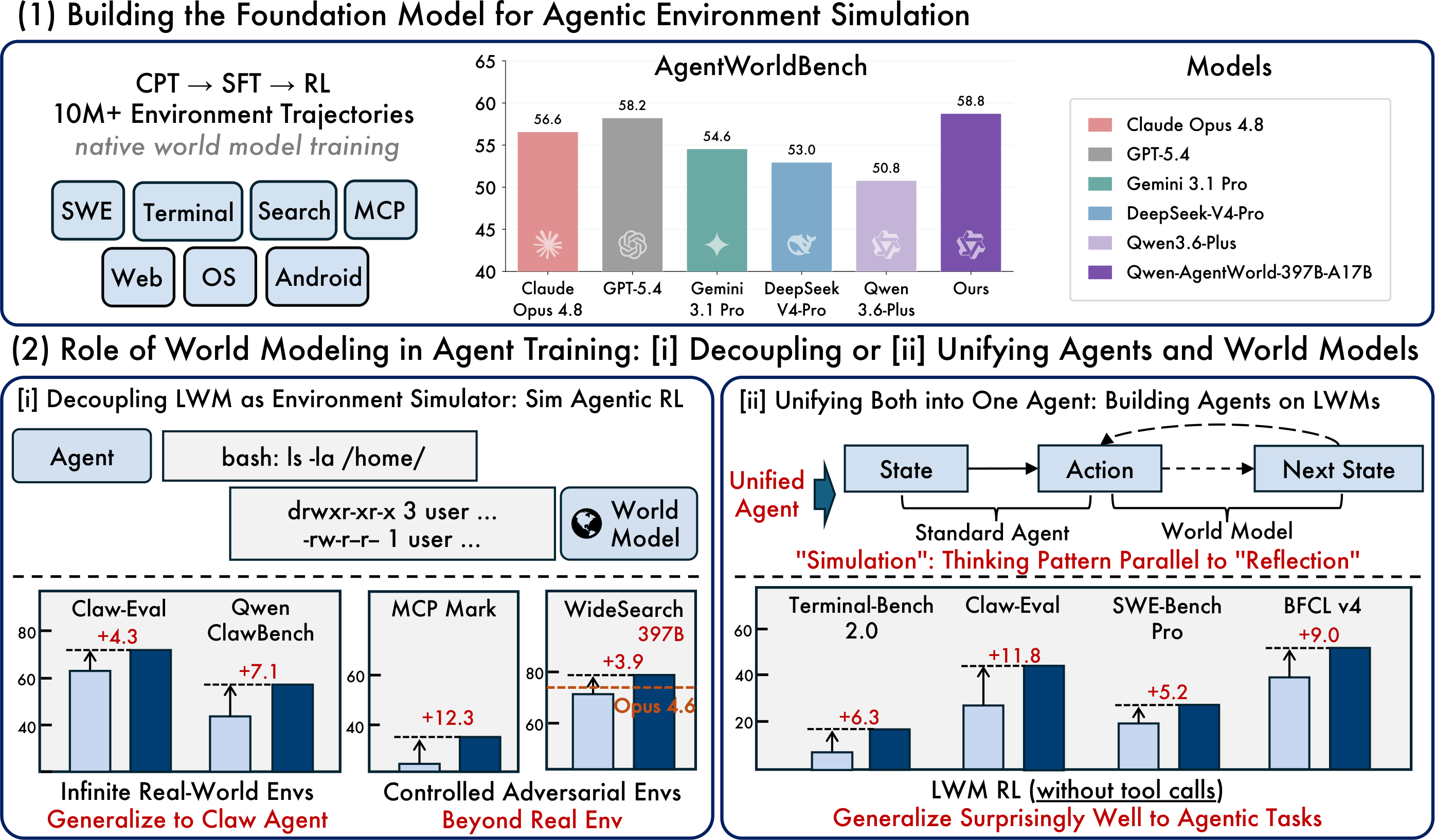
Original article image: foundation model, simulated RL and unified agent paradigms
The most practical open release is Qwen-AgentWorld-35B-A3B, a 35B-total / 3B-active MoE model with a default context length of 262K tokens. The research flagship, Qwen-AgentWorld-397B-A17B, achieves the stronger AgentWorldBench score reported by Qwen.
Item | Explanation |
Qwen-AgentWorld-35B-A3B | Open model weights for developers to download, serve and test |
Qwen-AgentWorld-397B-A17B | Research flagship with stronger reported benchmark score |
AgentWorldBench | A seven-domain benchmark with ground-truth observations from real environment execution |
Evaluation dimensions | Format, Factuality, Consistency, Realism and Quality |
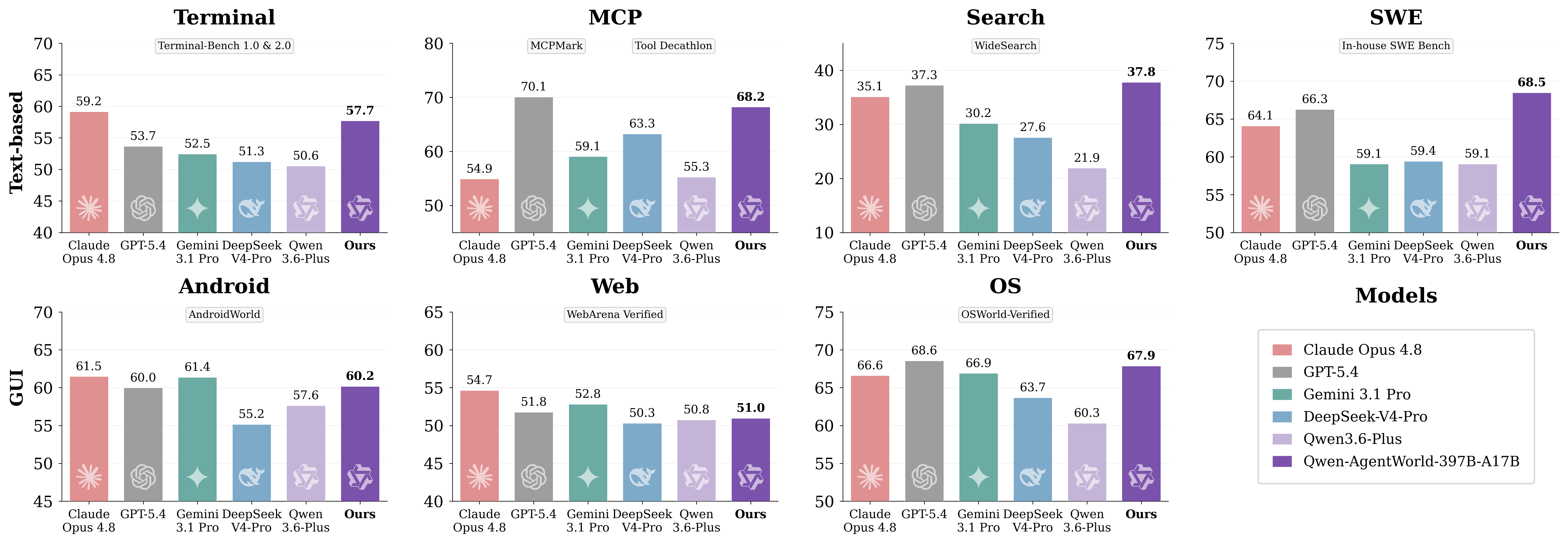
Original article image: AgentWorldBench domain-level results
The key is not to treat the benchmark as a universal chatbot ranking. AgentWorldBench measures environment simulation quality. For developers, the practical question is whether the model helps build more reliable agent training, evaluation and regression-testing workflows.
Deployment: it can start fast, but hardware still matters
The original article emphasizes fast deployment. That is true when GPU, drivers, Python environment and inference framework are already prepared. For normal users, the real bottlenecks are VRAM, long context and multi-GPU serving.
The official instructions support SGLang, vLLM, Transformers and OpenAI-compatible API calls. For server-style use, SGLang or vLLM is the cleaner path.
# SGLang example pip install sglang python -m sglang.launch_server \ --model-path Qwen/Qwen-AgentWorld-35B-A3B \ --port 8000 \ --tp-size 4 \ --context-length 262144 \ --reasoning-parser qwen3
# vLLM example pip install vllm vllm serve Qwen/Qwen-AgentWorld-35B-A3B \ --port 8000 \ --tensor-parallel-size 4 \ --max-model-len 262144 \ --reasoning-parser qwen3 \ --language-model-only \ --trust-remote-code
In practice, reduce context length first when OOM appears, confirm tensor parallel settings for multi-GPU deployments, and avoid forcing a 256K context window if your goal is only a small proof of concept.
Who should care about Qwen-AgentWorld?
• Agent researchers can study world modeling, simulated environments and agent RL.
• AI engineering teams can build simulation tests for tools, terminals, browsers, operating systems and mobile environments.
• Enterprise AI product teams can understand how agent infrastructure is moving from “answers” to environment-aware reasoning.
If your goal is simple writing, chat or normal code completion, this is not the most direct model. Its value is more foundational: modeling causality between agent actions and environment changes.
What this means for enterprise AI infrastructure
Projects like Qwen-AgentWorld show that AI agent infrastructure is moving beyond demos. But the more technical a product becomes, the more clearly it must explain what it does, who it is for, how it is deployed, what its limits are, and what outcomes it enables.
For AI agent products, model services, developer tools and enterprise AI infrastructure, technical communication cannot stop at model names and benchmark numbers. Teams need to explain architecture, environments, evaluation methods, limitations and real use cases clearly.
A team building agent training platforms or model deployment services needs architecture notes, use cases, FAQs, deployment documentation, evaluation reports and security boundaries — not just a short product introduction.
Final takeaway
The value of Qwen-AgentWorld is not only that one model reports a higher score than another. The deeper shift is that agent training and evaluation can use language world models as infrastructure: simulate environments, build grounded benchmarks, expose weaknesses through controllable perturbations, and transfer world-modeling knowledge to harder agent tasks.
For developers, it is a powerful environment simulator to study. For product teams, it points to the future of agent infrastructure. For enterprise AI teams, it reinforces another point: the more complex the technology, the more important clear architecture notes, documentation and evaluation methods become.
FAQ
Is Qwen-AgentWorld a normal chat model?
No. It is better understood as a language world model that simulates agent environments and predicts the next observation after an action.
Which domains does Qwen-AgentWorld cover?
It covers MCP, Search, Terminal, SWE, Web, OS and Android, spanning both text and GUI environments.
Can Qwen-AgentWorld-35B-A3B be deployed locally?
Yes, but it requires serious hardware for long-context inference. Users should lower the context window if they hit memory limits.
What does AgentWorldBench evaluate?
It evaluates predicted environment observations across Format, Factuality, Consistency, Realism and Quality.
Why does this matter to enterprises?
It enables more controllable agent simulation, testing and safety evaluation before agents are exposed to real operational environments.
Related Tools
• SGLang
• vLLM
Sources
• Qwen-AgentWorld Technical Report
• Qwen-AgentWorld-35B-A3B on Hugging Face