Qwen-AgentWorld 가이드: 언어 월드 모델이 AI 에이전트의 학습, 평가, 배포를 바꾸는 방식
개발자와 AI 제품 팀을 위한 Qwen-AgentWorld 실용 개정 가이드로, 언어 월드 모델, 7가지 에이전트 상호작용 도메인, CPT/SFT/RL 학습 파이프라인, AgentWorldBench, 35B-A3B 및 397B-A17B 모델군, SGLang/vLLM 배포, 그리고 이러한 변화가 AI 에이전트 인프라와 평가에 갖는 의미를 다룹니다.

원문 이미지: Qwen-AgentWorld는 텍스트와 GUI 환경을 통합합니다
Qwen-AgentWorld에서 가장 흥미로운 부분은 그것이 또 하나의 더 강력한 AI 에이전트라는 점이 아닙니다. 이는 문제를 한 단계 더 깊은 곳으로 옮깁니다. 에이전트가 환경 안에서 학습해야 한다면, 환경 자체를 언어 모델로 모델링할 수 있을까요?
전통적인 에이전트는 학습과 평가를 위해 실제 브라우저, 터미널, 코드 저장소, 모바일 앱, 데스크톱 환경에 의존합니다. 이는 현실적이지만 비용이 많이 들고, 확장 속도가 느리며, 제어하기 어렵습니다. Qwen-AgentWorld는 언어 월드 모델을 사용해 이러한 환경을 시뮬레이션하므로, 에이전트를 더 제어 가능한 언어 기반 세계에서 학습하고 테스트할 수 있습니다.
이는 Qwen-AgentWorld가 단순한 챗봇도 아니고 단순히 자율 에이전트도 아니라는 뜻입니다. Qwen-AgentWorld는 AI 에이전트를 위한 환경 시뮬레이션 인프라로 이해하는 것이 더 적절합니다.
언어 월드 모델이 중요한 이유
에이전트 작업에서 어려운 부분은 모델이 답할 수 있는지 여부만이 아닙니다. 어려운 부분은 행동 이후에 어떤 일이 일어나는지 예측하는 것입니다. 웹 클릭, 터미널 명령, 코드 수정, MCP 도구 호출, Android 제스처는 모두 환경 상태를 변화시킵니다.
모든 학습 단계가 실제 환경에 의존한다면 비용은 높고 결과를 재현하기도 더 어려워집니다. 언어 월드 모델은 현재 컨텍스트와 에이전트의 행동을 바탕으로 다음 관찰 결과를 예측하려고 합니다.
• 더 낮은 학습 비용: 각 궤적마다 실제 환경을 실행하는 횟수가 줄어듭니다.
• 더 제어된 평가: 교란과 가상의 세계를 안전하게 주입할 수 있습니다.
• 더 깔끔한 전이: 서로 다른 도메인이 상태-행동-다음 상태 모델링의 변형이 됩니다.
일곱 가지 도메인: 텍스트 도구부터 GUI 환경까지
원문 이미지: Qwen-AgentWorld는 MCP, Search, IDE/SWE, Terminal, Web, OS, Android를 포괄합니다
Qwen-AgentWorld는 MCP, Search, Terminal, SWE, Web, OS, Android를 포괄합니다. 처음 네 가지는 텍스트 환경에 더 가깝고, 마지막 세 가지는 GUI 중심 환경입니다.
도메인 | 유형 | 시뮬레이션할 수 있는 것 |
MCP | 텍스트 도구 | 도구 호출, 함수 반환, 서비스 상태 변화 |
Search | 텍스트 환경 | 검색 결과, 스니펫, 순위 및 답변 유출 위험 |
Terminal | 명령줄 | 셸 출력, 파일 시스템 상태, 프로세스 동작 |
SWE | 소프트웨어 엔지니어링 | 코드 수정, 테스트, 패치 및 오류 메시지 |
웹 | GUI | 브라우저 DOM 상태, 양식, 버튼 및 탐색 |
OS | GUI | 데스크톱 창, 파일, 앱 및 시스템 상태 |
Android | GUI | 터치 동작 이후의 모바일 UI 트리와 상태 |
그 가치는 팀이 모든 환경마다 별도의 시뮬레이터를 필요로 하지 않는다는 데 있다. 대신 모델은 여러 도메인에 걸친 상태 전이에 대한 언어 기반 표현을 학습한다.
사후 적응이 아닌 네이티브 월드 모델
“네이티브”라는 단어는 중요하다. Qwen-AgentWorld는 몇 가지 에이전트 프롬프트로 보완한 범용 LLM으로 제시되지 않는다. 환경 모델링은 지속적 사전 학습 단계부터 훈련 목표에 내장되어 있다.
차원 | 사후 LLM 적응 | Qwen-AgentWorld |
훈련 목표 | 먼저 일반 언어, 이후 에이전트 행동 | CPT부터 환경 상태 전이 |
파이프라인 | 대부분 훈련 후 SFT 또는 RL | CPT -> SFT -> RL |
지식 주입 | 프롬프팅 및 데이터 증강 | 환경 동역학을 모델 가중치에 내장 |
범위 | 대개 하나 또는 몇 개의 도메인 | 하나의 모델에 7개 도메인 |
CPT는 환경 동역학을 주입하고, SFT는 다음 상태 예측 추론을 활성화하며, RL은 형식, 사실성, 일관성, 현실감 및 전반적인 품질을 향상시킨다.
모델과 벤치마크: 수치를 신중하게 읽어야 한다
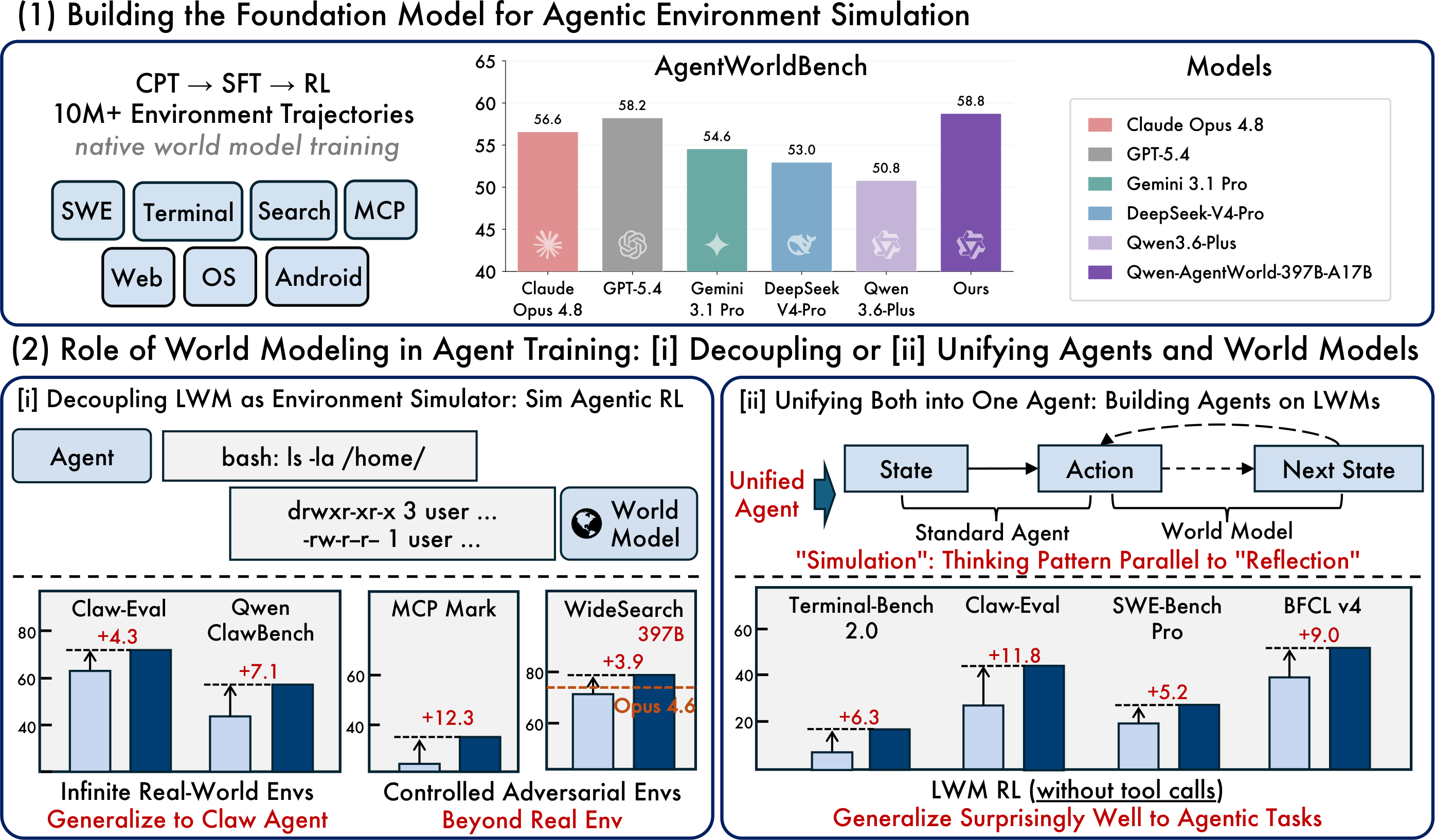
원문 기사 이미지: 파운데이션 모델, 시뮬레이션된 RL 및 통합 에이전트 패러다임
가장 실용적인 공개 릴리스는 기본 컨텍스트 길이가 262K 토큰인 35B 전체 / 3B 활성 MoE 모델인 Qwen-AgentWorld-35B-A3B이다. 연구 플래그십인 Qwen-AgentWorld-397B-A17B는 Qwen이 보고한 더 높은 AgentWorldBench 점수를 달성한다.
항목 | 설명 |
Qwen-AgentWorld-35B-A3B | 개발자가 다운로드, 서빙 및 테스트할 수 있는 공개 모델 가중치 |
Qwen-AgentWorld-397B-A17B | 더 강력한 것으로 보고된 벤치마크 점수를 갖춘 연구용 플래그십 |
AgentWorldBench | 실제 환경 실행에서 얻은 정답 관측값을 포함하는 7개 도메인 벤치마크 |
평가 차원 | 형식, 사실성, 일관성, 현실성 및 품질 |
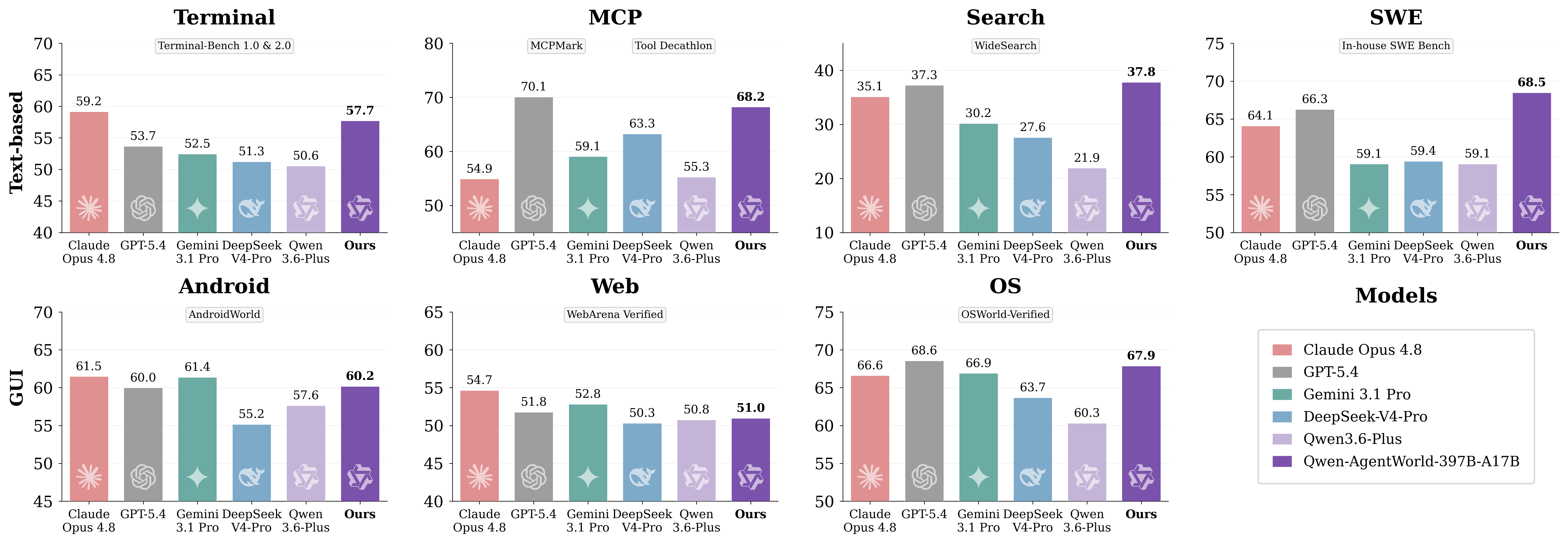
원문 이미지: AgentWorldBench 도메인 수준 결과
핵심은 이 벤치마크를 범용 챗봇 순위로 취급하지 않는 것이다. AgentWorldBench는 환경 시뮬레이션 품질을 측정한다. 개발자에게 실질적인 질문은 이 모델이 더 신뢰할 수 있는 에이전트 학습, 평가 및 회귀 테스트 워크플로를 구축하는 데 도움이 되는지 여부다.
배포: 빠르게 시작할 수 있지만, 하드웨어는 여전히 중요하다
원문은 빠른 배포를 강조한다. GPU, 드라이버, Python 환경 및 추론 프레임워크가 이미 준비되어 있다면 이는 사실이다. 일반 사용자에게 실제 병목은 VRAM, 긴 컨텍스트, 멀티 GPU 서빙이다.
공식 지침은 SGLang, vLLM, Transformers 및 OpenAI 호환 API 호출을 지원한다. 서버 형태로 사용할 경우 SGLang 또는 vLLM이 더 깔끔한 경로다.
# SGLang 예시 pip install sglang python -m sglang.launch_server \ --model-path Qwen/Qwen-AgentWorld-35B-A3B \ --port 8000 \ --tp-size 4 \ --context-length 262144 \ --reasoning-parser qwen3
# vLLM 예시 pip install vllm vllm serve Qwen/Qwen-AgentWorld-35B-A3B \ --port 8000 \ --tensor-parallel-size 4 \ --max-model-len 262144 \ --reasoning-parser qwen3 \ --language-model-only \ --trust-remote-code
실제로 OOM이 발생하면 먼저 컨텍스트 길이를 줄이고, 멀티 GPU 배포를 위한 텐서 병렬 설정을 확인하며, 목표가 작은 개념 증명에 불과하다면 256K 컨텍스트 창을 억지로 사용하지 않는 것이 좋다.
누가 Qwen-AgentWorld에 관심을 가져야 하는가?
• 에이전트 연구자는 월드 모델링, 시뮬레이션 환경 및 에이전트 RL을 연구할 수 있다.
• AI 엔지니어링 팀은 도구, 터미널, 브라우저, 운영체제 및 모바일 환경을 위한 시뮬레이션 테스트를 구축할 수 있다.
• 기업 AI 제품 팀은 에이전트 인프라가 “답변”에서 환경 인식 추론으로 어떻게 이동하고 있는지 이해할 수 있다.
목표가 단순한 글쓰기, 채팅 또는 일반적인 코드 완성이라면 이 모델은 가장 직접적인 선택이 아니다. 그 가치는 더 근본적이다. 즉 에이전트 행동과 환경 변화 사이의 인과관계를 모델링하는 데 있다.
이것이 기업 AI 인프라에 의미하는 바
Qwen-AgentWorld와 같은 프로젝트는 AI 에이전트 인프라가 데모를 넘어 이동하고 있음을 보여준다. 하지만 제품이 더 기술적으로 발전할수록, 그것이 무엇을 하는지, 누구를 위한 것인지, 어떻게 배포되는지, 한계가 무엇인지, 어떤 결과를 가능하게 하는지를 더 명확히 설명해야 한다.
AI 에이전트 제품, 모델 서비스, 개발자 도구 및 기업 AI 인프라의 경우, 기술 커뮤니케이션은 모델 이름과 벤치마크 숫자에서 멈출 수 없다. 팀은 아키텍처, 환경, 평가 방법, 한계 및 실제 사용 사례를 명확히 설명해야 한다.
에이전트 학습 플랫폼이나 모델 배포 서비스를 구축하는 팀에는 짧은 제품 소개뿐만 아니라 아키텍처 노트, 사용 사례, FAQ, 배포 문서, 평가 보고서 및 보안 경계가 필요하다.
최종 요점
Qwen-AgentWorld의 가치는 한 모델이 다른 모델보다 더 높은 점수를 보고한다는 데만 있지 않다. 더 깊은 변화는 에이전트 학습과 평가가 언어 월드 모델을 인프라로 사용할 수 있다는 점이다. 즉 환경을 시뮬레이션하고, 근거 있는 벤치마크를 구축하며, 제어 가능한 교란을 통해 약점을 드러내고, 월드 모델링 지식을 더 어려운 에이전트 과제로 전이할 수 있다.
개발자에게는 연구할 수 있는 강력한 환경 시뮬레이터입니다. 제품 팀에게는 에이전트 인프라의 미래를 제시합니다. 기업 AI 팀에게는 또 다른 점을 강조합니다. 기술이 복잡할수록 명확한 아키텍처 노트, 문서화 및 평가 방법이 더욱 중요해진다는 것입니다.
FAQ
Qwen-AgentWorld는 일반적인 채팅 모델인가요?
아니요. 이는 에이전트 환경을 시뮬레이션하고 작업 후 다음 관찰을 예측하는 언어 세계 모델로 이해하는 것이 더 적절합니다.
Qwen-AgentWorld는 어떤 도메인을 다루나요?
MCP, Search, Terminal, SWE, Web, OS 및 Android를 다루며, 텍스트와 GUI 환경을 모두 포괄합니다.
Qwen-AgentWorld-35B-A3B를 로컬에 배포할 수 있나요?
예, 하지만 긴 컨텍스트 추론을 위해서는 상당한 하드웨어가 필요합니다. 메모리 한계에 도달하면 사용자는 컨텍스트 창을 줄여야 합니다.
AgentWorldBench는 무엇을 평가하나요?
Format, Factuality, Consistency, Realism 및 Quality 전반에서 예측된 환경 관찰을 평가합니다.
이것이 기업에 중요한 이유는 무엇인가요?
에이전트가 실제 운영 환경에 노출되기 전에 보다 제어 가능한 에이전트 시뮬레이션, 테스트 및 안전성 평가를 가능하게 합니다.
관련 도구
• Qwen 블로그
• SGLang
• vLLM
출처
• Hugging Face의 Qwen-AgentWorld-35B-A3B