Qwen-AgentWorldガイド:言語ワールドモデルがAIエージェントのトレーニング、評価、デプロイをどう変えるか
開発者やAIプロダクトチーム向けにQwen-AgentWorldを実践的に書き直したガイド。言語ワールドモデル、7つのエージェント相互作用ドメイン、CPT/SFT/RLトレーニングパイプライン、AgentWorldBench、35B-A3Bおよび397B-A17Bモデルファミリー、SGLang/vLLMによるデプロイ、そしてこの変化がAIエージェントのインフラと評価にもたらす意味を網羅しています。

元記事の画像:Qwen-AgentWorldはテキスト環境とGUI環境を統合する
Qwen-AgentWorldで最も興味深い点は、単にまた別のより強力なAIエージェントであることではありません。問題を一段深い層へと移します。エージェントが環境内で学習する必要があるなら、その環境自体を言語モデルでモデル化できるのか?
従来のエージェントは、トレーニングと評価のために実際のブラウザ、ターミナル、コードリポジトリ、モバイルアプリ、デスクトップ環境に依存しています。それは現実的ではありますが、コストが高く、スケールさせるのが遅く、制御も困難です。Qwen-AgentWorldは言語ワールドモデルを使ってこれらの環境をシミュレートするため、エージェントをより制御しやすい言語ベースの世界でトレーニングおよびテストできます。
つまり、Qwen-AgentWorldは単なるチャットボットでも、単なる自律型エージェントでもありません。むしろ、AIエージェントのための環境シミュレーション基盤として理解するのが適切です。
言語ワールドモデルが重要な理由
エージェントの取り組みにおける難しい部分は、モデルが回答できるかどうかだけではありません。難しいのは、ある行動の後に何が起こるかを予測することです。Webのクリック、ターミナルコマンド、コード編集、MCPツール呼び出し、Androidジェスチャーはいずれも環境の状態を変化させます。
すべてのトレーニングステップが実環境に依存する場合、コストは高くなり、結果の再現も難しくなります。言語ワールドモデルは、現在のコンテキストとエージェントの行動から次の観測を予測しようとします。
• トレーニングコストの低減:各軌跡ごとに実環境を起動する回数を減らせます。
• より制御された評価:摂動や架空の世界を安全に注入できます。
• よりクリーンな転移:異なるドメインが、状態・行動・次状態モデリングのバリエーションになります。
7つのドメイン:テキストツールからGUI環境まで
元記事の画像:Qwen-AgentWorldはMCP、検索、IDE/SWE、ターミナル、Web、OS、Androidをカバーする
Qwen-AgentWorldはMCP、検索、ターミナル、SWE、Web、OS、Androidをカバーしています。最初の4つはテキスト環境に近く、最後の3つはGUI中心の環境です。
ドメイン | 種類 | シミュレートできるもの |
MCP | テキストツール | ツール呼び出し、関数の戻り値、サービス状態の変化 |
検索 | テキスト環境 | 検索結果、スニペット、ランキング、回答漏洩リスク |
ターミナル | コマンドライン | シェル出力、ファイルシステムの状態、プロセスの挙動 |
SWE | ソフトウェアエンジニアリング | コード編集、テスト、パッチ、エラーメッセージ |
Web | GUI | ブラウザのDOM状態、フォーム、ボタン、ナビゲーション |
OS | GUI | デスクトップウィンドウ、ファイル、アプリ、システム状態 |
Android | GUI | タッチ操作後のモバイルUIツリーと状態 |
その価値は、チームが環境ごとに個別のシミュレーターを必要としない点にあります。代わりに、モデルはドメインをまたいだ状態遷移の言語ベースの表現を学習します。
後付けの適応ではない、ネイティブなワールドモデル
「ネイティブ」という言葉は重要です。Qwen-AgentWorldは、いくつかのエージェント用プロンプトを継ぎ足した汎用LLMとして提示されているわけではありません。環境モデリングは、継続的事前学習の段階以降、訓練目的に組み込まれています。
次元 | 後付けのLLM適応 | Qwen-AgentWorld |
訓練目的 | まず一般的な言語、その後にエージェントの振る舞い | CPT以降の環境状態遷移 |
パイプライン | 主に訓練後のSFTまたはRL | CPT -> SFT -> RL |
知識注入 | プロンプト設計とデータ拡張 | 環境ダイナミクスをモデル重みに埋め込む |
カバレッジ | 多くの場合、1つまたは少数のドメイン | 1つのモデルで7つのドメイン |
CPTは環境ダイナミクスを注入し、SFTは次状態予測の推論を活性化し、RLは形式、事実性、一貫性、現実性、全体的な品質を向上させます。
モデルとベンチマーク:数値は慎重に読む
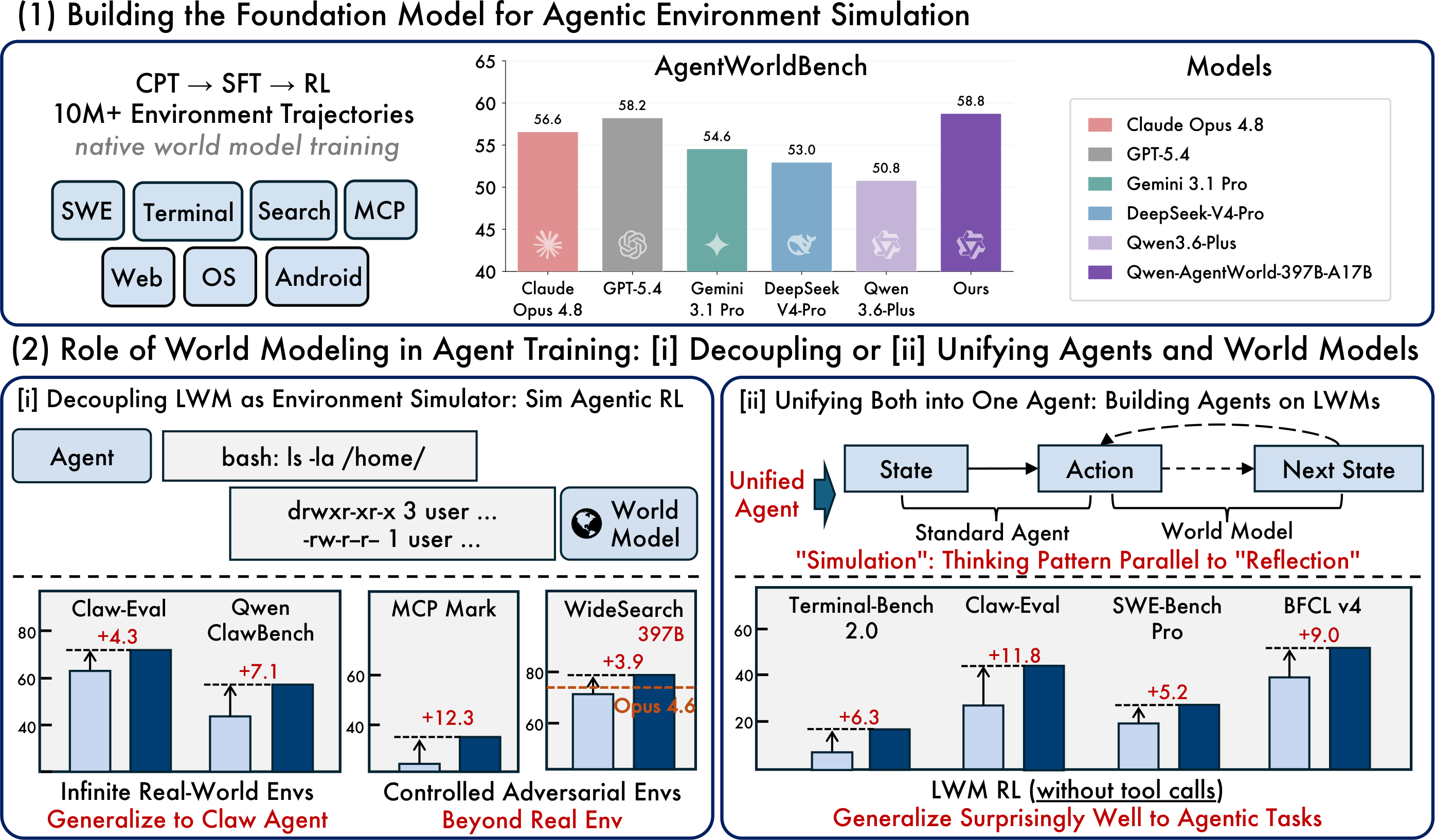
元記事の画像:基盤モデル、シミュレーテッドRL、統一エージェントパラダイム
最も実用的なオープンリリースはQwen-AgentWorld-35B-A3Bで、総パラメータ35B/アクティブ3BのMoEモデルであり、デフォルトのコンテキスト長は262Kトークンです。研究向けのフラッグシップであるQwen-AgentWorld-397B-A17Bは、Qwenが報告したより高いAgentWorldBenchスコアを達成しています。
項目 | 説明 |
Qwen-AgentWorld-35B-A3B | 開発者がダウンロード、提供、テストできるオープンなモデル重み |
Qwen-AgentWorld-397B-A17B | より高いベンチマークスコアが報告されている研究向けフラッグシップ |
AgentWorldBench | 実環境での実行から得られた正解観測を備えた、7ドメインのベンチマーク |
評価次元 | 形式、事実性、一貫性、現実性、品質 |
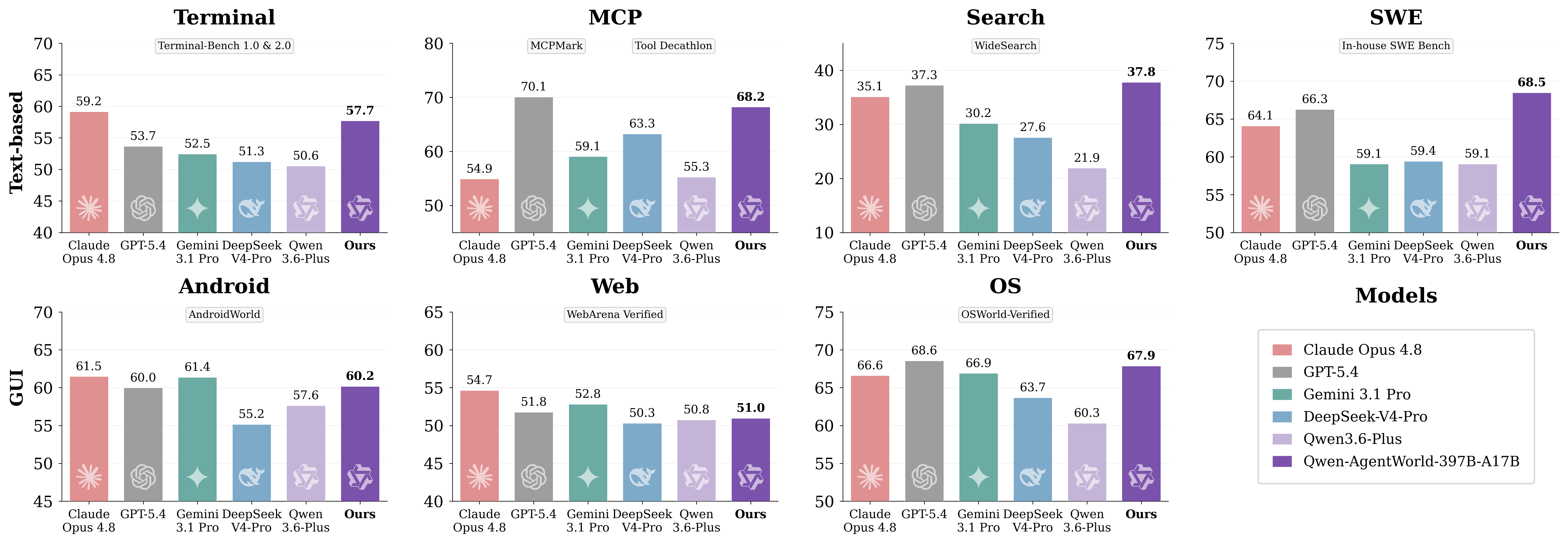
元記事の画像:AgentWorldBenchのドメイン別結果
重要なのは、このベンチマークを汎用チャットボットのランキングとして扱わないことです。AgentWorldBenchは環境シミュレーションの品質を測定します。開発者にとって実践的な問いは、そのモデルがより信頼性の高いエージェントの訓練、評価、回帰テストのワークフロー構築に役立つかどうかです。
デプロイ:すばやく始められるが、ハードウェアは依然として重要
元記事では高速なデプロイが強調されています。GPU、ドライバー、Python環境、推論フレームワークがすでに準備されている場合、それは事実です。一般的なユーザーにとって実際のボトルネックは、VRAM、長いコンテキスト、マルチGPUでのサービングです。
公式手順では、SGLang、vLLM、Transformers、OpenAI互換API呼び出しがサポートされています。サーバー用途では、SGLangまたはvLLMがよりすっきりした方法です。
# SGLangの例 pip install sglang python -m sglang.launch_server \ --model-path Qwen/Qwen-AgentWorld-35B-A3B \ --port 8000 \ --tp-size 4 \ --context-length 262144 \ --reasoning-parser qwen3
# vLLMの例 pip install vllm vllm serve Qwen/Qwen-AgentWorld-35B-A3B \ --port 8000 \ --tensor-parallel-size 4 \ --max-model-len 262144 \ --reasoning-parser qwen3 \ --language-model-only \ --trust-remote-code
実際には、OOMが発生したらまずコンテキスト長を短くし、マルチGPUデプロイではテンソル並列の設定を確認し、目的が小規模な概念実証だけであれば256Kのコンテキストウィンドウを無理に使わないようにします。
Qwen-AgentWorldに注目すべき人は誰か?
• エージェント研究者は、世界モデリング、シミュレーション環境、エージェントRLを研究できます。
• AIエンジニアリングチームは、ツール、ターミナル、ブラウザ、オペレーティングシステム、モバイル環境向けのシミュレーションテストを構築できます。
• 企業向けAIプロダクトチームは、エージェント基盤が「回答」から環境を認識した推論へどのように移行しているかを理解できます。
目的が単純な文章作成、チャット、通常のコード補完であれば、これは最も直接的なモデルではありません。その価値はより基盤的なものであり、エージェントの行動と環境変化の因果関係をモデル化することにあります。
これが企業向けAIインフラに意味すること
Qwen-AgentWorldのようなプロジェクトは、AIエージェント基盤がデモの段階を超えつつあることを示しています。しかし、プロダクトが技術的になればなるほど、それが何をするのか、誰のためのものなのか、どのようにデプロイされるのか、限界は何か、どのような成果を可能にするのかを、より明確に説明する必要があります。
AIエージェント製品、モデルサービス、開発者ツール、企業向けAIインフラでは、技術コミュニケーションをモデル名やベンチマーク数値だけで終わらせることはできません。チームは、アーキテクチャ、環境、評価手法、制限事項、実際のユースケースを明確に説明する必要があります。
エージェント訓練プラットフォームやモデルデプロイサービスを構築するチームには、短い製品紹介だけでなく、アーキテクチャノート、ユースケース、FAQ、デプロイ文書、評価レポート、セキュリティ境界が必要です。
最後の要点
Qwen-AgentWorldの価値は、あるモデルが別のモデルより高いスコアを報告しているということだけではありません。より深い変化は、エージェントの訓練と評価において、言語世界モデルをインフラとして利用できるようになることです。すなわち、環境をシミュレートし、根拠に基づいたベンチマークを構築し、制御可能な摂動を通じて弱点を明らかにし、世界モデリングの知識をより難しいエージェントタスクへ転移できるようになることです。
開発者にとって、それは研究する価値のある強力な環境シミュレーターです。プロダクトチームにとっては、エージェントインフラの未来を示しています。エンタープライズAIチームにとっては、もう一つの点を改めて示しています。すなわち、技術が複雑になればなるほど、明確なアーキテクチャノート、ドキュメント、評価方法がより重要になるということです。
FAQ
Qwen-AgentWorldは通常のチャットモデルですか?
いいえ。これは、エージェント環境をシミュレートし、アクション後の次の観測を予測する言語世界モデルとして理解する方が適切です。
Qwen-AgentWorldはどの領域を対象としていますか?
MCP、Search、Terminal、SWE、Web、OS、Androidを対象としており、テキスト環境とGUI環境の両方にまたがっています。
Qwen-AgentWorld-35B-A3Bはローカルにデプロイできますか?
はい。ただし、長いコンテキストの推論には高性能なハードウェアが必要です。メモリ制限に達した場合は、コンテキストウィンドウを小さくする必要があります。
AgentWorldBenchは何を評価しますか?
Format、Factuality、Consistency、Realism、Qualityの観点から、予測された環境観測を評価します。
なぜこれが企業にとって重要なのですか?
エージェントが実際の運用環境にさらされる前に、より制御しやすいエージェントシミュレーション、テスト、安全性評価を可能にするためです。
関連ツール
• Qwenブログ
• SGLang
• vLLM
出典
• 元のCSDN記事
• Hugging Face上のQwen-AgentWorld-35B-A3B