DeepSeek DSpark 登陆 Apple Silicon:通过 mlx-dspark 加速 Mac 本地大语言模型
本文介绍了 DeepSeek 的 DSpark 推测解码方法如何通过 mlx-dspark 移植到 Apple Silicon,从而让受支持的 Gemma 和 Qwen 模型在本地 Mac 上的推理速度更快。 关键在于,这一移植并不只是追求原始速度。它还通过让目标模型验证生成的 token 来保持输出保真度,并支持采样解码行为。 DFlash 集成提供了另一个有用选项,尤其适用于代码和数学任务,在这些场景中,长块草稿生成能够带来收益。对于开放式聊天,DSpark 可能仍然更适合,因为维持被接受长度更困难。 **对于基于 Mac 的本地 AI 开发,mlx-dspark 为 Apple Silicon 用户提供了一种实用方式,可以在不把所有内容迁移到服务器的情况下测试更快的大语言模型推理。**

DeepSeek DSpark 登陆 Apple Silicon:通过 mlx-dspark 加速 Mac 本地 LLM
引言
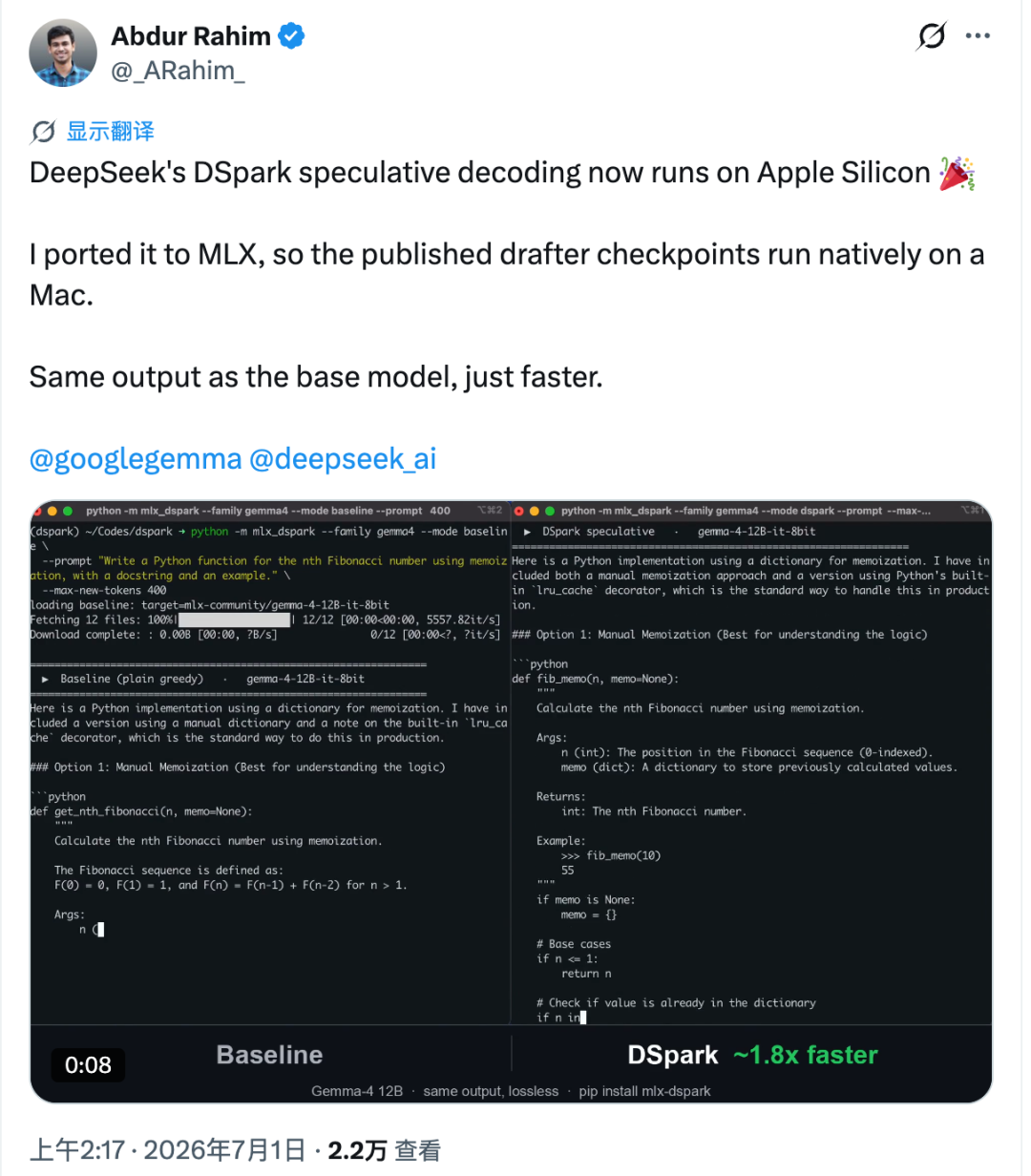
DeepSeek 的 DSpark 开源仅约一周,社区就已将其带到了苹果电脑上。
这个移植项目名为 mlx-dspark。它通过苹果的 MLX 生态,在 Apple Silicon 上原生运行 DSpark 风格的推测性解码,并在 Gemma-4 12B 和 Qwen3-4B 等模型上进行了测试。在报告的 Mac 基准测试中,Gemma-4 12B 的生成速度提升了约 1.6 倍,Qwen3-4B 则提升了约 1.4 倍。
更有意思的不只是速度。该移植项目旨在让生成输出与基础目标模型保持一致,因此加速并不是通过简单改变模型行为来实现的。
来源与图片说明
- 来源文章:DeepSeek 新技术移植苹果芯片!Mac 本地大模型加速 60%
- 页面中的原始来源说明:本文转载自微信 / 量子位。
- 这个 Markdown 版本是基于来源事实和公开项目页面整理的 SEO 友好英文改写版,并非原文逐行完整翻译。
- 来源文章不包含可执行命令块或配置文件。因此,没有删除或修改任何代码块。
- 下方包含的图片是来源文章中与正文相关的截图。二维码、关注提示、评论界面以及装饰性平台元素未作为独立内容收录。
Apple Silicon 现在可以运行 DSpark 风格的本地 LLM 加速
DeepSeek 于 6 月 27 日发布了 DSpark,将其作为一种推测性解码方法。在最初的服务器端场景中,DSpark 被描述为一种可在特定服务条件下将生成速度提升约 60% 到 85% 的方法。
不过一开始,可用实现主要面向数据中心 GPU 环境。它并不是原生的 Apple Silicon 工作流。随着 mlx-dspark 的出现,这一点发生了改变。mlx-dspark 是 Abdur Rahim 为基于 MLX 的 Mac 推理创建的实现。

从高层来看,DSpark 背后的思路很容易理解:
- 一个较小的草稿模型提前提出若干候选 token。
- 更大的目标模型检查这些 token。
- 被接受的 token 会被保留。
- 被拒绝的 token 则通过正常的目标模型路径重新生成。
这就是推测性解码的核心:让成本更低的草稿路径提前猜测,然后让目标模型验证其正确性。
在服务器 GPU 上,验证一组 token 可能相对高效,因为瓶颈通常在于内存移动,而不是纯计算。在这种情况下,多检查几个 token 未必会增加太多成本。
Apple Silicon 的表现则不同。在 Mac 上,每多验证一个 token 都可能带来更明显的延迟。Rahim 测量了这一成本,并估计在 Apple Silicon 上,在测试条件下,这类加速方式的速度上限约为 2.2 倍。
为了让它具备实用性,他将 Hugging Face 上的草稿检查点迁移到 MLX 工作流中,并将其与 Gemma-4 12B 和 Qwen3-4B 目标模型配对。验证流程在 MLX 内部重新构建,草稿权重则被量化为 4-bit。

在报告的 M4 Pro 测试中,与苹果官方 MLX 工具相比:
- Gemma-4 12B 从约 18.4 tok/s 提升到约 30 tok/s,速度提升约 1.6 倍。
- Qwen3-4B 从约 52.9 tok/s 提升到约 73 tok/s,速度提升约 1.4 倍。
对于本地 AI 构建者来说,这是一个有意义的提升。MacBook 仍然不是数据中心推理服务器,但这类优化能让更大的本地模型在开发、测试和个人工作流中变得更可用。
该移植项目也关注高保真输出
许多面向大模型加速的本地移植项目会首先关注贪婪解码。在贪婪解码中,模型在每一步都只是选择概率最高的 token。这会让正确性更容易测试,因为可以逐个 token 对比输出。
mlx-dspark 更进一步,实现了 DSpark 论文中描述的温度采样方法。草稿模型提出 token,目标模型则使用基于概率的规则接受它们。被拒绝的部分会从
剩余分布。
这一点很重要,因为采样正是许多真实应用所采用的方式。聊天界面、创意写作、智能体探索和产品文案生成通常依赖 temperature,而不是严格的贪婪解码。
Rahim 检查了在相同 temperature 设置下,采样流程是否保留目标模型的分布。换句话说,目标并不是生成一个“足够相似”的近似结果。这个移植版本的设计目标是让加速不会改变模型预期的输出行为。
移植过程中也有一些实践经验:
- 如果草稿模型搭配的是基础目标模型,而不是匹配的指令微调目标模型,接受率可能会大幅下降。
- 在报告的测试中,切换到对应的指令微调目标模型后,接受率从约 47% 提高到约 82%。
- 对目标模型使用 bf16 会增加验证成本,其提升接受率的效果并不足以抵消这一点,因此在这套 Mac 工作流中,8-bit 目标模型配置更实用。
- 草稿模型被压缩到 4-bit,并缩小到约 1.8 GB,更容易在本地机器内存中常驻。
其结果是一个本地实现,它不只是简单地运行得更快,还试图保留用户对原始目标模型所期待的行为。
DFlash 也被集成进来,用于加速代码和数学任务
在 mlx-dspark 的帖子引起关注后,DFlash 也加入了讨论。DFlash 背后的作者之一 Jian Chen 询问是否可以在相同的 Mac 设置中测试 DFlash 模型。
DFlash 是 z-lab 提出的另一种推测解码方法。它的设计不同于 DSpark。DFlash 并不是通过更强的依赖处理逐步生成候选 token,而是使用一种块扩散风格的方法,并行地对整块 token 进行去噪。
在测试设置中,Rahim 使用 Jian 的移植脚本,将 z-lab/gemma4-12B-it-DFlash 连接到基于 MLX 的 Gemma-4 目标模型。随后,他在同一台 Mac 上比较了 DFlash 和 DSpark。
对于代码和数学等结构化任务,DFlash 表现非常出色。它的接受长度达到约 5.95 到 6.20,吞吐量达到约 36 tok/s,在报告的设置中约为 2.1×。

这并不意味着 DFlash 总是更好。DFlash 一次会草拟完整的 16 个 token 块,但目标模型并不总是会接受整个块。被接受的 token 数量称为接受长度。
在开放式聊天中,后续 token 更难预测。接受长度可能会保持较低,这意味着完整的 16-token 块并不会转化为真正的速度优势。在这类场景中,DSpark 可能更快,因为它的马尔可夫头被设计用于减少并行 token 草拟中经常出现的“后缀衰减”问题。
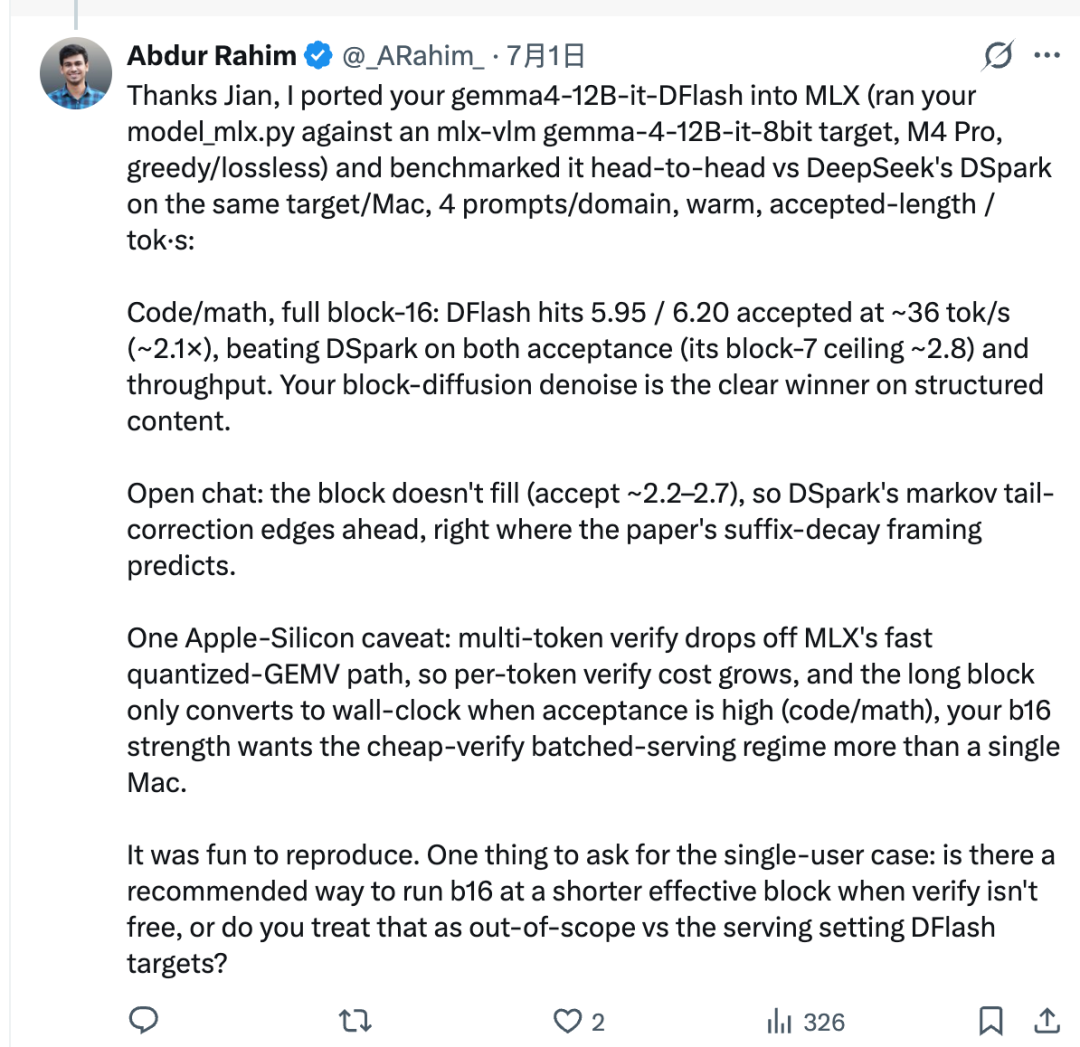
后来的一次 mlx-dspark 更新将 z-lab 的原始 DFlash 路径直接加入了包中。它还新增了一个用于调整有效块长度的参数。这为用户提供了更灵活的选择:
- 对类似聊天的任务使用较短的块。
- 对代码和数学任务使用完整的 16-token 块。
- 在同一个包中比较 DSpark 和 DFlash,而不必在不同项目之间切换。
这使得 mlx-dspark 不再像是一个单一方法的实验,而更像是面向 Apple Silicon 用户的实用本地推理工具包。
为什么这对本地 AI 开发很重要
对于开发者、研究人员和小团队来说,本地 LLM 工作流正变得越来越常见。在本地运行模型可以更好地控制延迟、数据处理、实验和离线工作流。
但本地推理通常有一个令人头疼的限制:速度。即使模型能够装入内存,生成过程也可能让人感觉很慢。
mlx-dspark 的有趣之处在于,它在不要求使用全新目标模型的情况下解决了这个问题。它通过推测解码让现有模型感觉更快,同时仍然允许目标模型验证输出。
对于在 Mac 上构建本地 AI 应用的开发者来说,这可能在以下几种场景中很有用:
- 测试 AI
在迁移到服务器推理之前先测试功能。
2. 运行本地编码助手或文档助手。
3. 比较不同任务类型的解码策略。
4. 构建轻量级的 OpenAI 兼容本地服务。
5. 评估较小的 Mac 配置是否足以支持某个特定原型。
权衡仍然很重要。某种在代码和数学任务上表现良好的方法,未必是开放式对话的最佳选择。某种在 M4 Pro 上表现出色的方法,在较旧的 Apple Silicon 芯片或内存受限的机器上可能会有不同表现。
因此,实际结论并不是“某一种方法在所有场景下都胜出”。而是 Apple Silicon 现在为尝试 DSpark、DFlash 和 MLX 原生推测解码提供了一条更强的路径。
常见问题
什么是 DSpark?
DSpark 是一种与 DeepSeek 的 DeepSpec 项目相关的推测解码方法。它使用草稿模型提前提出 token,然后让目标模型进行验证,旨在在保持输出行为一致的同时加速推理。
什么是 mlx-dspark?
mlx-dspark 是一个社区实现,通过 MLX 将 DSpark 和 DFlash 风格的推测解码带到 Apple Silicon。它让受支持的 Gemma 和 Qwen 目标模型能够在 Mac 上通过草稿模型加速运行。
mlx-dspark 能在本地运行 DeepSeek-V4 吗?
不能。mlx-dspark 项目说明,其本地 Mac 目标是 Gemma 和 Qwen 等稠密模型,而不是 DeepSeek-V4 本身。它使用 DeepSeek 的 DSpark 草稿生成方法,但在 Mac 工作流中实际生成 token 的目标模型是 Gemma 或 Qwen。
DSpark 在 Mac 上能快多少?
在已报告的测试中,Gemma-4 12B 从约 18.4 tok/s 提升到约 30 tok/s,而 Qwen3-4B 从约 52.9 tok/s 提升到约 73 tok/s。实际速度取决于 Mac 芯片、模型、精度、提示类型和解码设置。
什么是 DFlash?
DFlash 是 z-lab 提出的一种块扩散推测解码方法。它并行草拟一组 token,当接受长度较高时,在代码和数学等结构化任务上可能尤其有效。
DSpark 比 DFlash 更好吗?
并不总是如此。DFlash 在代码和数学任务上可能表现更好,而 DSpark 在开放式聊天中可能更强,因为长并行块更难预测。最佳选择取决于目标模型和任务类型。
我需要 Apple Silicon 才能使用 mlx-dspark 吗?
mlx-dspark 是通过 MLX 为 Apple Silicon 设计的,因此 Apple Silicon Mac 是其预期运行环境。它还需要兼容的 Python 环境,以及来自 Hugging Face 或本地路径的受支持模型权重。
推测解码适合生产环境吗?
可以适合,但生产使用需要仔细基准测试。在依赖它之前,你需要检查输出保真度、接受长度、延迟、批处理行为、内存使用、模型兼容性以及特定硬件上的性能。
相关工具
- mlx-dspark:一个社区项目,通过 MLX 在 Apple Silicon 上原生运行 DSpark 和 DFlash 推测解码。
- DeepSpec:DeepSeek 用于训练和评估推测解码草稿模型的全栈代码库。
- MLX:Apple 为在 Apple Silicon 上高效工作而设计的机器学习框架。
- z-lab/gemma4-12B-it-DFlash:用于 Gemma-4 12B 指令微调工作流的 DFlash 草稿模型。
- Hugging Face:本文提到的项目和检查点所使用的模型托管平台。
- DeepSeek Hugging Face Organization:DeepSeek 官方 Hugging Face 组织,用于发布模型和检查点。
相关链接
- BAAI Hub 上的源文章:介绍 mlx-dspark Apple Silicon 移植的原始中文文章。
- Abdur Rahim 的原始 X 帖子:所引用的宣布 DSpark 在 Apple Silicon 上运行的帖子。
- mlx-dspark GitHub 仓库:Apple Silicon 实现的安装、用法、支持模型和基准说明。
- DeepSpec GitHub 仓库:DeepSeek 用于推测解码算法和已发布检查点的官方仓库。
- DSpark 论文 PDF:DeepSpec 仓库中包含的技术论文。
- Hugging Face 上的 DFlash 集合:z-lab 的 DFlash 相关草稿模型集合。
- MLX 文档:Apple MLX 框架的官方文档。
- MLX GitHub 仓库:Apple Silicon 机器学习框架的源代码仓库。
总结
本文解释了 DeepSeek 的 DSpark 推测解码方法如何通过 mlx-dspark 移植到 Apple Silicon,从而让受支持的 Gemma 和 Qwen 模型在本地 Mac 推理中更快。
关键点在于,这次移植不仅仅关注原始速度。它还通过让目标模型验证生成的 token 来保持输出保真度,包括支持采样解码行为。
DFlash 集成又增加了一个有用选项,
尤其是在代码和数学任务中,撰写较长的代码块可能会带来回报。对于开放式聊天,DSpark 可能仍然更合适,因为可接受的长度更难维持。
对于基于 Mac 的本地 AI 开发,mlx-dspark 为 Apple Silicon 用户提供了一种实用方式,让他们无需将所有内容迁移到服务器,就能测试更快的 LLM 推理。