DeepSeek DSpark Comes to Apple Silicon: Mac Local LLM Acceleration with mlx-dspark
This article explains how DeepSeek's DSpark speculative decoding method was ported to Apple Silicon through mlx-dspark, making local Mac inference faster for supported Gemma and Qwen models. The key point is that the port is not only about raw speed. It also focuses on maintaining output fidelity by letting the target model verify generated tokens, including support for sampled decoding behavior. DFlash integration adds another useful option, especially for code and math tasks where long block drafting can pay off. For open-ended chat, DSpark may still be the better fit because accepted length is harder to maintain. **For Mac-based local AI development, mlx-dspark gives Apple Silicon users a practical way to test faster LLM inference without moving everything to a server.**

DeepSeek DSpark Comes to Apple Silicon: Mac Local LLM Acceleration with mlx-dspark
Introduction
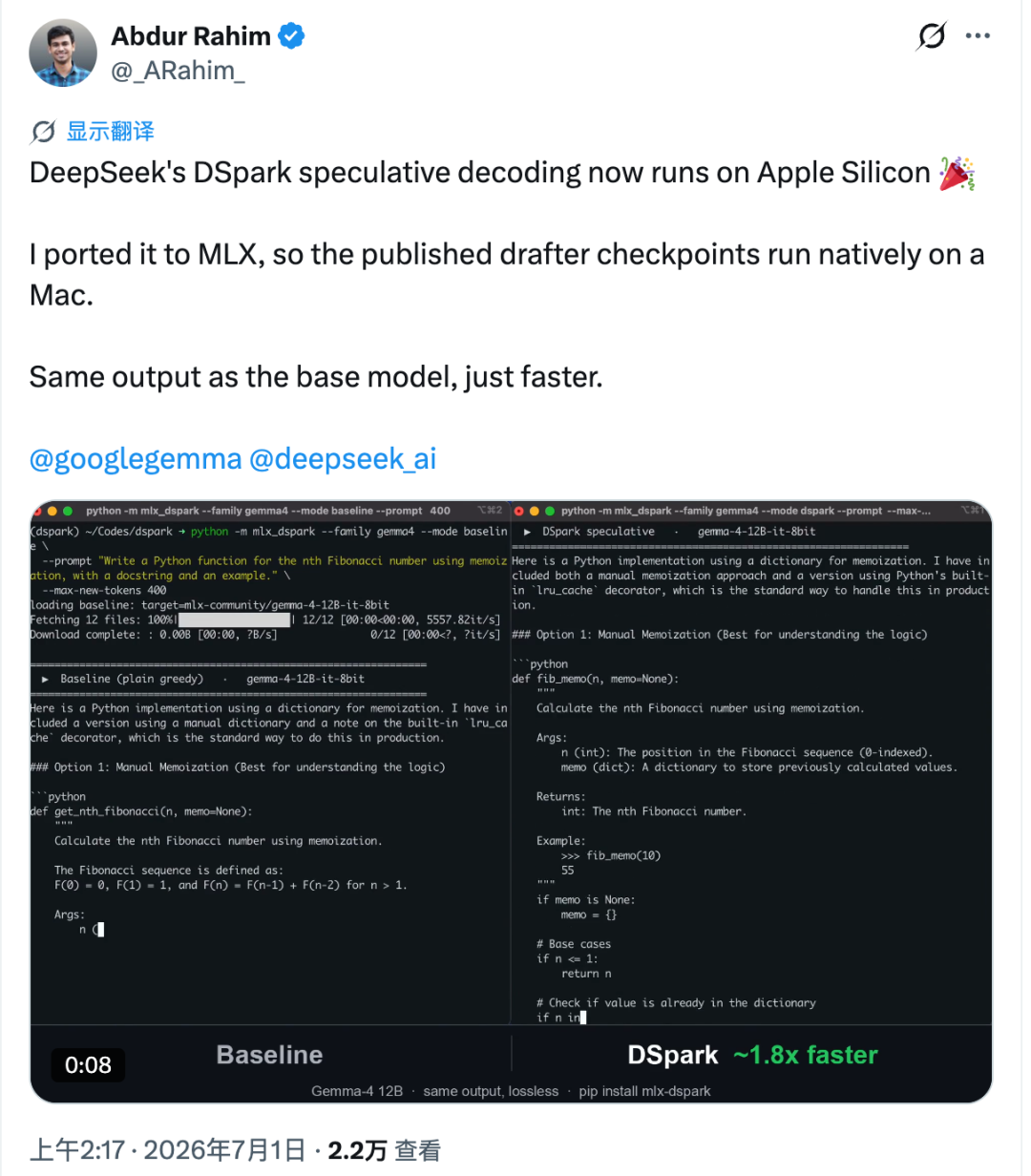
DeepSeek's DSpark had only been open source for about a week before the community brought it to Apple computers.
The port is called mlx-dspark. It runs DSpark-style speculative decoding natively on Apple Silicon through Apple's MLX ecosystem, with tests on models such as Gemma-4 12B and Qwen3-4B. In the reported Mac benchmarks, Gemma-4 12B generation became about 1.6× faster, while Qwen3-4B improved by about 1.4×.
What makes this more interesting is not just the speed. The port aims to keep the generated output aligned with the base target model, so the acceleration is not achieved by simply changing the model's behavior.
Source and Image Notes
- Source article: DeepSeek新技术移植苹果芯片!Mac本地大模型加速60%
- Original source note from the page: the article was republished from WeChat / QbitAI.
- This Markdown version is an SEO-ready English adaptation based on the source facts and public project pages. It is not a line-by-line full translation of the original article.
- The source article did not contain executable command blocks or configuration files. Therefore, no code blocks were removed or altered.
- The images included below are the body-relevant screenshots from the source article. QR codes, follow prompts, comments UI, and decorative platform elements were not included as standalone content.
Apple Silicon Can Now Run DSpark-Style Local LLM Acceleration
DeepSeek released DSpark on June 27 as a speculative decoding approach. In its original server-side setting, DSpark was described as a way to increase generation speed by around 60% to 85% under specific serving conditions.
At first, though, the available implementation focused on data-center GPU environments. It was not a native Apple Silicon workflow. That changed with mlx-dspark, an implementation created by Abdur Rahim for MLX-based inference on Mac.

The idea behind DSpark is easy to understand at a high level:
- A smaller draft model proposes several candidate tokens in advance.
- The larger target model checks those tokens.
- Accepted tokens are kept.
- Rejected tokens are regenerated through the normal target model path.
This is the core of speculative decoding: let a cheaper draft path guess ahead, then let the target model verify correctness.
On server GPUs, verifying a group of tokens can be relatively efficient because the bottleneck is often memory movement rather than pure computation. In that setting, checking a few extra tokens may not add much cost.
Apple Silicon behaves differently. On a Mac, each extra verified token can add more visible latency. Rahim measured this cost and estimated that, on Apple Silicon, the upper speed limit for this style of acceleration is around 2.2× under the tested conditions.
To make it practical, he moved the draft checkpoints from Hugging Face into an MLX workflow and paired them with Gemma-4 12B and Qwen3-4B target models. The verification flow was rebuilt inside MLX, and the draft weights were quantized to 4-bit.

In the reported M4 Pro tests, compared with Apple's official MLX tools:
- Gemma-4 12B increased from about 18.4 tok/s to around 30 tok/s, about 1.6× faster.
- Qwen3-4B increased from about 52.9 tok/s to around 73 tok/s, about 1.4× faster.
For local AI builders, that is a meaningful gain. A MacBook is still not a data-center inference server, but this kind of optimization makes larger local models feel more usable for development, testing, and personal workflows.
The Port Also Focuses on High-Fidelity Output
Many local ports of large-model acceleration focus on greedy decoding first. In greedy decoding, the model simply picks the highest-probability token at each step. That makes correctness easier to test because the output can be compared token by token.
mlx-dspark goes further by implementing the temperature sampling method described in the DSpark paper. The draft model proposes tokens, and the target model accepts them using a probability-based rule. Rejected parts are resampled from the remaining distribution.
This matters because sampling is what many real applications use. Chat interfaces, creative writing, agent exploration, and product copy generation often rely on temperature rather than strict greedy decoding.
Rahim checked that the sampling flow preserves the target model's distribution under the same temperature setting. In other words, the goal is not to produce a “similar enough” approximation. The port is designed so that acceleration does not change the model's intended output behavior.
There were also a few practical lessons during the port:
- If the draft model is paired with a base target model instead of the matching instruction-tuned target, the acceptance rate can drop sharply.
- In the reported test, switching to the corresponding instruction-tuned target increased the acceptance rate from about 47% to about 82%.
- Using bf16 for the target model increased verification cost more than it improved acceptance, so the 8-bit target setup was more practical in this Mac workflow.
- The draft model was compressed to 4-bit and reduced to about 1.8 GB, making it easier to keep in memory on local machines.
The result is a local implementation that does more than simply run faster. It also tries to preserve the behavior that users expect from the original target model.
DFlash Was Also Integrated for Faster Code and Math Tasks
After the mlx-dspark post drew attention, DFlash entered the discussion. Jian Chen, one of the authors behind DFlash, asked whether the DFlash model could be tested in the same Mac setup.
DFlash is another speculative decoding approach from z-lab. Its design differs from DSpark. Instead of generating candidate tokens step by step with stronger dependency handling, DFlash uses a block-diffusion style method to denoise a whole block of tokens in parallel.
In the tested setup, Rahim used Jian's porting script to connect z-lab/gemma4-12B-it-DFlash to the MLX-based Gemma-4 target model. He then compared DFlash and DSpark on the same Mac.
For structured tasks such as code and math, DFlash performed very well. Its accepted length reached around 5.95 to 6.20, and throughput reached about 36 tok/s, roughly 2.1× in the reported setting.

That does not mean DFlash is always better. DFlash drafts a full block of 16 tokens at once, but the target model does not always accept the full block. The number of accepted tokens is called the accepted length.
In open-ended chat, the next tokens are harder to predict. The accepted length may stay lower, which means the full 16-token block does not translate into a real speed advantage. In that kind of setting, DSpark can be faster because its Markov head is designed to reduce the “suffix decay” problem that often appears in parallel token drafting.
A later mlx-dspark update added z-lab's original DFlash path directly into the package. It also added a parameter for adjusting the effective block length. That gives users a more flexible choice:
- Use shorter blocks for chat-like tasks.
- Use the full 16-token block for code and math tasks.
- Compare DSpark and DFlash in the same package instead of switching between separate projects.
This makes mlx-dspark less like a single-method experiment and more like a practical local inference toolkit for Apple Silicon users.
Why This Matters for Local AI Development
Local LLM workflows are becoming more common for developers, researchers, and small teams. Running models locally gives more control over latency, data handling, experiments, and offline workflows.
But local inference often has one painful limitation: speed. Even when a model fits into memory, generation can feel slow.
mlx-dspark is interesting because it attacks that problem without requiring a completely new target model. It uses speculative decoding to make the existing model feel faster while still letting the target model verify the output.
For developers building local AI apps on Mac, this could be useful in several scenarios:
- Testing AI features before moving to server inference.
- Running local coding assistants or document assistants.
- Comparing decoding strategies for different task types.
- Building lightweight OpenAI-compatible local services.
- Evaluating whether a smaller Mac setup is enough for a specific prototype.
The trade-off is still important. A method that works well on code and math may not be the best choice for open conversation. A method that performs well on an M4 Pro may behave differently on older Apple Silicon chips or memory-constrained machines.
So the practical takeaway is not “one method wins everywhere.” It is that Apple Silicon now has a stronger path for experimenting with DSpark, DFlash, and MLX-native speculative decoding.
FAQ
What is DSpark?
DSpark is a speculative decoding method associated with DeepSeek's DeepSpec project. It uses a draft model to propose tokens ahead of time and lets the target model verify them, aiming to speed up inference while preserving output behavior.
What is mlx-dspark?
mlx-dspark is a community implementation that brings DSpark and DFlash-style speculative decoding to Apple Silicon through MLX. It lets supported Gemma and Qwen targets run with draft-model acceleration on Mac.
Does mlx-dspark run DeepSeek-V4 locally?
No. The mlx-dspark project explains that its local Mac targets are dense models such as Gemma and Qwen, not DeepSeek-V4 itself. It uses DeepSeek's DSpark drafter method, but the token-producing target model in the Mac workflow is Gemma or Qwen.
How much faster is DSpark on Mac?
In the reported tests, Gemma-4 12B improved from about 18.4 tok/s to about 30 tok/s, while Qwen3-4B improved from about 52.9 tok/s to about 73 tok/s. Actual speed depends on the Mac chip, model, precision, prompt type, and decoding settings.
What is DFlash?
DFlash is a block-diffusion speculative decoding method from z-lab. It drafts a block of tokens in parallel and can be especially effective on structured tasks such as code and math when the accepted length is high.
Is DSpark better than DFlash?
Not always. DFlash may perform better on code and math tasks, while DSpark can be stronger in open-ended chat where long parallel blocks are harder to predict. The best choice depends on the target model and task type.
Do I need Apple Silicon to use mlx-dspark?
mlx-dspark is designed for Apple Silicon through MLX, so an Apple Silicon Mac is the intended environment. It also requires a compatible Python setup and supported model weights from Hugging Face or local paths.
Is speculative decoding suitable for production?
It can be, but production use requires careful benchmarking. You need to check output fidelity, acceptance length, latency, batching behavior, memory usage, model compatibility, and hardware-specific performance before relying on it.
Related Tools
- mlx-dspark: A community project that runs DSpark and DFlash speculative decoding natively on Apple Silicon through MLX.
- DeepSpec: DeepSeek's full-stack codebase for training and evaluating speculative decoding draft models.
- MLX: Apple's machine learning framework designed for efficient work on Apple Silicon.
- z-lab/gemma4-12B-it-DFlash: A DFlash draft model for Gemma-4 12B instruction-tuned workflows.
- Hugging Face: A model hosting platform used by the projects and checkpoints mentioned in this article.
- DeepSeek Hugging Face Organization: DeepSeek's official Hugging Face organization for model and checkpoint releases.
Related Links
- Source Article on BAAI Hub: The original Chinese article that introduced the mlx-dspark Apple Silicon port.
- Abdur Rahim's Original X Post: The referenced post announcing DSpark running on Apple Silicon.
- mlx-dspark GitHub Repository: Installation, usage, supported models, and benchmark notes for the Apple Silicon implementation.
- DeepSpec GitHub Repository: Official DeepSeek repository for speculative decoding algorithms and released checkpoints.
- DSpark Paper PDF: The technical paper included in the DeepSpec repository.
- DFlash Collection on Hugging Face: z-lab's collection for DFlash-related draft models.
- MLX Documentation: Official documentation for Apple's MLX framework.
- MLX GitHub Repository: Source repository for the Apple Silicon machine learning framework.
Summary
This article explains how DeepSeek's DSpark speculative decoding method was ported to Apple Silicon through mlx-dspark, making local Mac inference faster for supported Gemma and Qwen models.
The key point is that the port is not only about raw speed. It also focuses on maintaining output fidelity by letting the target model verify generated tokens, including support for sampled decoding behavior.
DFlash integration adds another useful option, especially for code and math tasks where long block drafting can pay off. For open-ended chat, DSpark may still be the better fit because accepted length is harder to maintain.
For Mac-based local AI development, mlx-dspark gives Apple Silicon users a practical way to test faster LLM inference without moving everything to a server.