DeepSeek DSpark llega a Apple Silicon: aceleración de LLM locales en Mac con mlx-dspark
Este artículo explica cómo el método de decodificación especulativa DSpark de DeepSeek se adaptó a Apple Silicon mediante mlx-dspark, haciendo más rápida la inferencia local en Mac para los modelos Gemma y Qwen compatibles. El punto clave es que la adaptación no se centra solo en la velocidad bruta. También se enfoca en mantener la fidelidad de la salida al permitir que el modelo objetivo verifique los tokens generados, incluido el soporte para el comportamiento de decodificación con muestreo. La integración de DFlash añade otra opción útil, especialmente para tareas de código y matemáticas, donde la generación preliminar de bloques largos puede resultar beneficiosa. Para chats abiertos, DSpark aún puede ser la opción más adecuada porque mantener la longitud aceptada es más difícil. **Para el desarrollo local de IA en Mac, mlx-dspark ofrece a los usuarios de Apple Silicon una forma práctica de probar una inferencia de LLM más rápida sin trasladarlo todo a un servidor.**

DeepSeek DSpark llega a Apple Silicon: aceleración local de LLM en Mac con mlx-dspark
Introducción
DSpark de DeepSeek llevaba apenas una semana como código abierto cuando la comunidad lo llevó a los ordenadores de Apple.
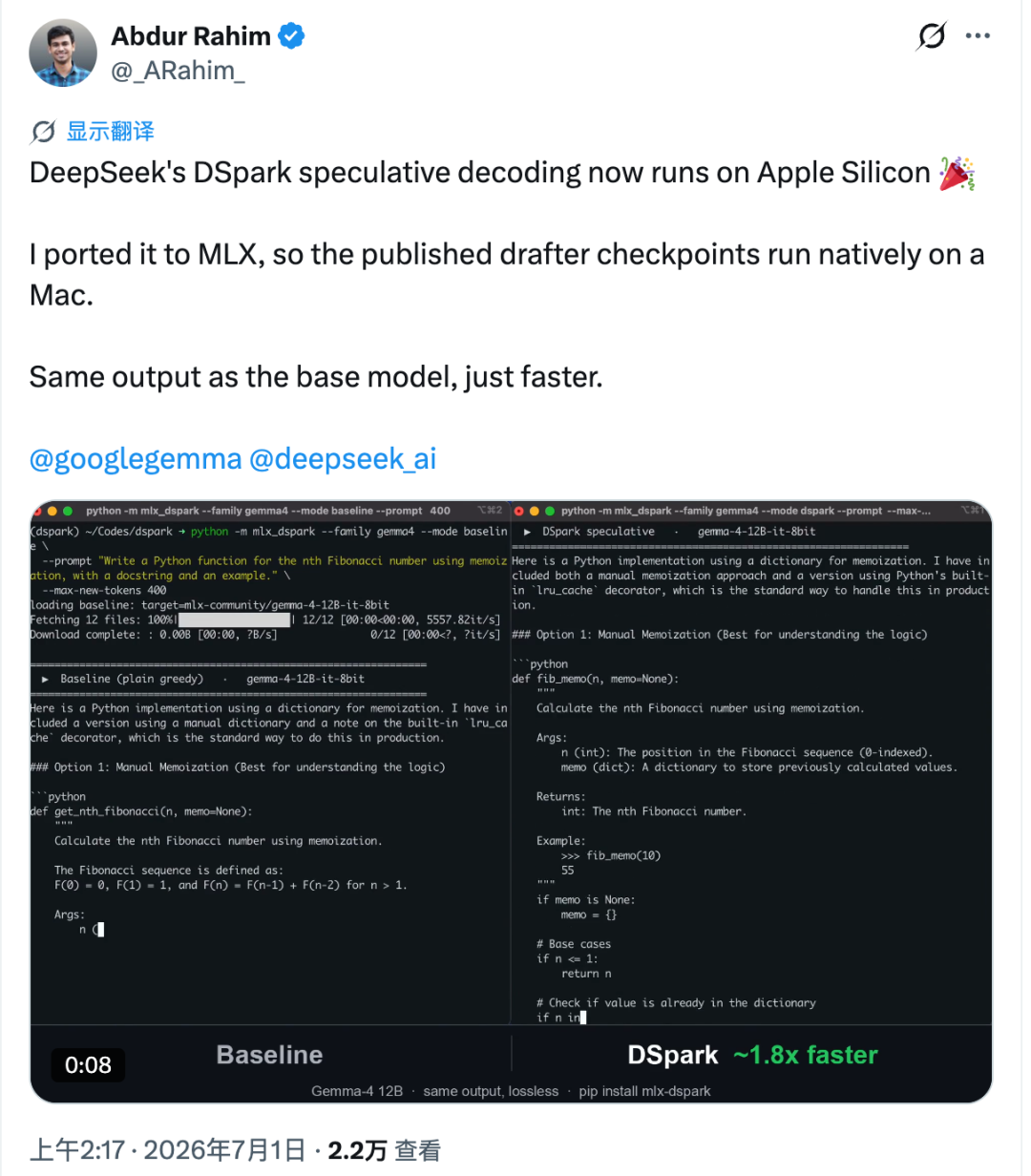
El port se llama mlx-dspark. Ejecuta de forma nativa la decodificación especulativa al estilo DSpark en Apple Silicon mediante el ecosistema MLX de Apple, con pruebas en modelos como Gemma-4 12B y Qwen3-4B. En los benchmarks reportados en Mac, la generación con Gemma-4 12B se volvió aproximadamente 1,6× más rápida, mientras que Qwen3-4B mejoró alrededor de 1,4×.
Lo que hace que esto sea más interesante no es solo la velocidad. El port busca mantener la salida generada alineada con el modelo objetivo base, de modo que la aceleración no se logra simplemente cambiando el comportamiento del modelo.
Fuente y notas sobre las imágenes
- Artículo fuente: DeepSeek新技术移植苹果芯片!Mac本地大模型加速60%
- Nota de la fuente original en la página: el artículo fue republicado desde WeChat / QbitAI.
- Esta versión en Markdown es una adaptación en inglés preparada para SEO basada en los hechos de la fuente y en páginas públicas del proyecto. No es una traducción completa línea por línea del artículo original.
- El artículo fuente no contenía bloques de comandos ejecutables ni archivos de configuración. Por lo tanto, no se eliminaron ni alteraron bloques de código.
- Las imágenes incluidas a continuación son capturas relevantes del cuerpo del artículo fuente. Los códigos QR, las invitaciones a seguir la cuenta, la interfaz de comentarios y los elementos decorativos de la plataforma no se incluyeron como contenido independiente.
Apple Silicon ya puede ejecutar aceleración local de LLM al estilo DSpark
DeepSeek lanzó DSpark el 27 de junio como un enfoque de decodificación especulativa. En su configuración original del lado del servidor, DSpark se describió como una forma de aumentar la velocidad de generación entre aproximadamente un 60% y un 85% bajo condiciones específicas de servicio.
Sin embargo, al principio, la implementación disponible se centraba en entornos de GPU de centros de datos. No era un flujo de trabajo nativo para Apple Silicon. Eso cambió con mlx-dspark, una implementación creada por Abdur Rahim para inferencia basada en MLX en Mac.

La idea detrás de DSpark es fácil de entender a alto nivel:
- Un modelo preliminar más pequeño propone por adelantado varios tokens candidatos.
- El modelo objetivo más grande comprueba esos tokens.
- Los tokens aceptados se conservan.
- Los tokens rechazados se regeneran mediante la ruta normal del modelo objetivo.
Este es el núcleo de la decodificación especulativa: permitir que una ruta preliminar más barata anticipe conjeturas y luego dejar que el modelo objetivo verifique la corrección.
En las GPU de servidor, verificar un grupo de tokens puede ser relativamente eficiente porque el cuello de botella suele estar en el movimiento de memoria más que en el cómputo puro. En ese contexto, comprobar algunos tokens adicionales puede no añadir mucho coste.
Apple Silicon se comporta de forma diferente. En un Mac, cada token adicional verificado puede añadir una latencia más perceptible. Rahim midió este coste y estimó que, en Apple Silicon, el límite superior de velocidad para este estilo de aceleración ronda 2,2× bajo las condiciones probadas.
Para hacerlo práctico, trasladó los checkpoints preliminares de Hugging Face a un flujo de trabajo MLX y los emparejó con los modelos objetivo Gemma-4 12B y Qwen3-4B. El flujo de verificación se reconstruyó dentro de MLX, y los pesos preliminares se cuantizaron a 4 bits.

En las pruebas reportadas con M4 Pro, en comparación con las herramientas oficiales MLX de Apple:
- Gemma-4 12B aumentó de aproximadamente 18,4 tok/s a cerca de 30 tok/s, alrededor de 1,6× más rápido.
- Qwen3-4B aumentó de aproximadamente 52,9 tok/s a cerca de 73 tok/s, alrededor de 1,4× más rápido.
Para quienes construyen IA local, se trata de una mejora significativa. Un MacBook sigue sin ser un servidor de inferencia de centro de datos, pero este tipo de optimización hace que los modelos locales más grandes se sientan más utilizables para desarrollo, pruebas y flujos de trabajo personales.
El port también se centra en una salida de alta fidelidad
Muchos ports locales de aceleración para modelos grandes se centran primero en la decodificación codiciosa. En la decodificación codiciosa, el modelo simplemente elige el token con mayor probabilidad en cada paso. Eso facilita comprobar la corrección, porque la salida puede compararse token por token.
mlx-dspark va más allá al implementar el método de muestreo con temperatura descrito en el artículo de DSpark. El modelo preliminar propone tokens, y el modelo objetivo los acepta mediante una regla basada en probabilidades. Las partes rechazadas se remuestrean desde
la distribución restante.
Esto importa porque el muestreo es lo que utilizan muchas aplicaciones reales. Las interfaces de chat, la escritura creativa, la exploración con agentes y la generación de textos para productos suelen depender de la temperatura, en lugar de una decodificación greedy estricta.
Rahim comprobó que el flujo de muestreo preserva la distribución del modelo objetivo con la misma configuración de temperatura. En otras palabras, el objetivo no es producir una aproximación “lo suficientemente similar”. El port está diseñado para que la aceleración no cambie el comportamiento de salida previsto del modelo.
También hubo algunas lecciones prácticas durante el port:
- Si el modelo borrador se empareja con un modelo objetivo base en lugar del modelo objetivo ajustado por instrucciones correspondiente, la tasa de aceptación puede caer drásticamente.
- En la prueba reportada, cambiar al objetivo ajustado por instrucciones correspondiente aumentó la tasa de aceptación de aproximadamente 47% a aproximadamente 82%.
- Usar bf16 para el modelo objetivo aumentó el coste de verificación más de lo que mejoró la aceptación, por lo que la configuración del objetivo en 8 bits resultó más práctica en este flujo de trabajo en Mac.
- El modelo borrador se comprimió a 4 bits y se redujo a aproximadamente 1,8 GB, lo que facilita mantenerlo en memoria en máquinas locales.
El resultado es una implementación local que hace más que simplemente ejecutarse más rápido. También intenta preservar el comportamiento que los usuarios esperan del modelo objetivo original.
DFlash también se integró para acelerar tareas de código y matemáticas
Después de que la publicación sobre mlx-dspark llamara la atención, DFlash entró en la conversación. Jian Chen, uno de los autores detrás de DFlash, preguntó si el modelo DFlash podía probarse en la misma configuración de Mac.
DFlash es otro enfoque de decodificación especulativa de z-lab. Su diseño difiere de DSpark. En lugar de generar tokens candidatos paso a paso con un manejo más fuerte de las dependencias, DFlash utiliza un método de estilo difusión por bloques para eliminar el ruido de un bloque completo de tokens en paralelo.
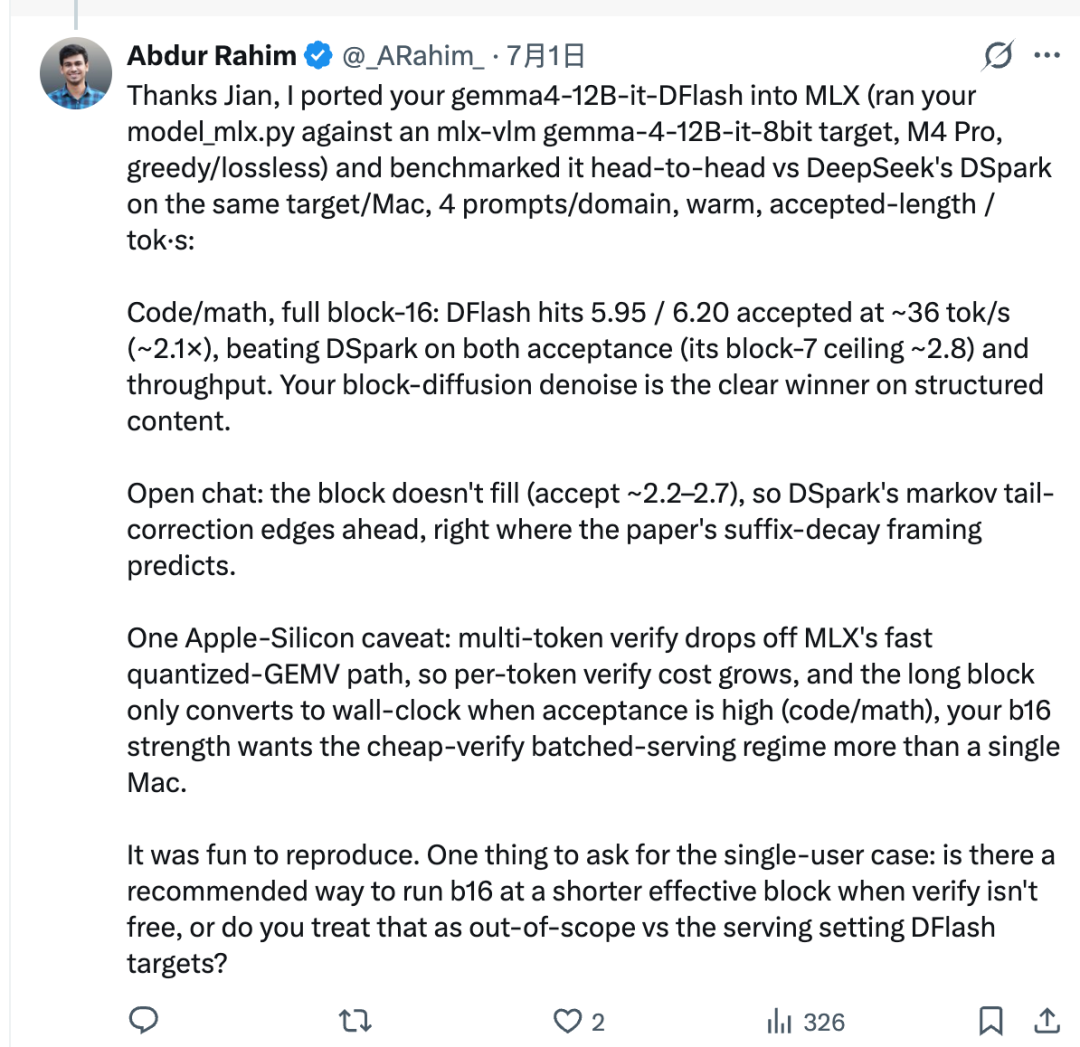
En la configuración probada, Rahim usó el script de portabilidad de Jian para conectar z-lab/gemma4-12B-it-DFlash con el modelo objetivo Gemma-4 basado en MLX. Luego comparó DFlash y DSpark en el mismo Mac.
Para tareas estructuradas como código y matemáticas, DFlash tuvo un rendimiento muy bueno. Su longitud aceptada alcanzó alrededor de 5,95 a 6,20, y el rendimiento llegó a unos 36 tok/s, aproximadamente 2,1× en la configuración reportada.

Eso no significa que DFlash sea siempre mejor. DFlash genera un bloque completo de 16 tokens de una vez, pero el modelo objetivo no siempre acepta el bloque completo. El número de tokens aceptados se denomina longitud aceptada.
En el chat abierto, los siguientes tokens son más difíciles de predecir. La longitud aceptada puede mantenerse más baja, lo que significa que el bloque completo de 16 tokens no se traduce en una ventaja real de velocidad. En ese tipo de configuración, DSpark puede ser más rápido porque su cabeza de Markov está diseñada para reducir el problema de “decaimiento del sufijo” que suele aparecer en la generación paralela de tokens borrador.
Una actualización posterior de mlx-dspark añadió la ruta original de DFlash de z-lab directamente al paquete. También añadió un parámetro para ajustar la longitud efectiva del bloque. Esto ofrece a los usuarios una opción más flexible:
- Usar bloques más cortos para tareas similares al chat.
- Usar el bloque completo de 16 tokens para tareas de código y matemáticas.
- Comparar DSpark y DFlash en el mismo paquete en lugar de cambiar entre proyectos separados.
Esto hace que mlx-dspark se parezca menos a un experimento de un solo método y más a un kit de herramientas práctico de inferencia local para usuarios de Apple Silicon.
Por qué esto importa para el desarrollo de IA local
Los flujos de trabajo con LLM locales son cada vez más comunes entre desarrolladores, investigadores y equipos pequeños. Ejecutar modelos localmente ofrece más control sobre la latencia, el manejo de datos, los experimentos y los flujos de trabajo sin conexión.
Pero la inferencia local suele tener una limitación dolorosa: la velocidad. Incluso cuando un modelo cabe en memoria, la generación puede sentirse lenta.
mlx-dspark es interesante porque aborda ese problema sin requerir un modelo objetivo completamente nuevo. Utiliza decodificación especulativa para hacer que el modelo existente se sienta más rápido, mientras sigue permitiendo que el modelo objetivo verifique la salida.
Para desarrolladores que crean aplicaciones de IA locales en Mac, esto podría ser útil en varios escenarios:
- Probar IA
características antes de pasar a la inferencia en servidor.
2. Ejecutar asistentes de programación o asistentes de documentos locales.
3. Comparar estrategias de decodificación para distintos tipos de tareas.
4. Crear servicios locales ligeros compatibles con OpenAI.
5. Evaluar si una configuración de Mac más pequeña es suficiente para un prototipo específico.
La compensación sigue siendo importante. Un método que funciona bien con código y matemáticas puede no ser la mejor opción para una conversación abierta. Un método que rinde bien en un M4 Pro puede comportarse de forma distinta en chips Apple Silicon más antiguos o en máquinas con memoria limitada.
Por tanto, la conclusión práctica no es que “un método gana en todas partes”. Es que Apple Silicon ahora cuenta con una vía más sólida para experimentar con DSpark, DFlash y decodificación especulativa nativa de MLX.
Preguntas frecuentes
¿Qué es DSpark?
DSpark es un método de decodificación especulativa asociado con el proyecto DeepSpec de DeepSeek. Utiliza un modelo borrador para proponer tokens por adelantado y permite que el modelo objetivo los verifique, con el fin de acelerar la inferencia mientras se preserva el comportamiento de salida.
¿Qué es mlx-dspark?
mlx-dspark es una implementación comunitaria que lleva la decodificación especulativa al estilo DSpark y DFlash a Apple Silicon mediante MLX. Permite que objetivos Gemma y Qwen compatibles se ejecuten con aceleración mediante modelo borrador en Mac.
¿mlx-dspark ejecuta DeepSeek-V4 localmente?
No. El proyecto mlx-dspark explica que sus objetivos locales para Mac son modelos densos como Gemma y Qwen, no DeepSeek-V4 en sí. Utiliza el método de borrador DSpark de DeepSeek, pero el modelo objetivo que produce tokens en el flujo de trabajo de Mac es Gemma o Qwen.
¿Cuánto más rápido es DSpark en Mac?
En las pruebas reportadas, Gemma-4 12B mejoró de aproximadamente 18,4 tok/s a unos 30 tok/s, mientras que Qwen3-4B mejoró de aproximadamente 52,9 tok/s a unos 73 tok/s. La velocidad real depende del chip del Mac, el modelo, la precisión, el tipo de prompt y la configuración de decodificación.
¿Qué es DFlash?
DFlash es un método de decodificación especulativa por difusión en bloques de z-lab. Genera un bloque de tokens en paralelo y puede ser especialmente eficaz en tareas estructuradas como código y matemáticas cuando la longitud aceptada es alta.
¿DSpark es mejor que DFlash?
No siempre. DFlash puede rendir mejor en tareas de código y matemáticas, mientras que DSpark puede ser más sólido en chats abiertos, donde los bloques paralelos largos son más difíciles de predecir. La mejor opción depende del modelo objetivo y del tipo de tarea.
¿Necesito Apple Silicon para usar mlx-dspark?
mlx-dspark está diseñado para Apple Silicon mediante MLX, por lo que un Mac con Apple Silicon es el entorno previsto. También requiere una configuración de Python compatible y pesos de modelos compatibles desde Hugging Face o rutas locales.
¿La decodificación especulativa es adecuada para producción?
Puede serlo, pero el uso en producción requiere una evaluación comparativa cuidadosa. Debes comprobar la fidelidad de salida, la longitud de aceptación, la latencia, el comportamiento por lotes, el uso de memoria, la compatibilidad del modelo y el rendimiento específico del hardware antes de depender de ella.
Herramientas relacionadas
- mlx-dspark: Un proyecto comunitario que ejecuta decodificación especulativa DSpark y DFlash de forma nativa en Apple Silicon mediante MLX.
- DeepSpec: La base de código integral de DeepSeek para entrenar y evaluar modelos borrador de decodificación especulativa.
- MLX: El framework de aprendizaje automático de Apple diseñado para trabajar de forma eficiente en Apple Silicon.
- z-lab/gemma4-12B-it-DFlash: Un modelo borrador DFlash para flujos de trabajo Gemma-4 12B ajustados a instrucciones.
- Hugging Face: Una plataforma de alojamiento de modelos utilizada por los proyectos y checkpoints mencionados en este artículo.
- Organización DeepSeek en Hugging Face: La organización oficial de DeepSeek en Hugging Face para publicaciones de modelos y checkpoints.
Enlaces relacionados
- Artículo fuente en BAAI Hub: El artículo original en chino que presentó la adaptación de mlx-dspark a Apple Silicon.
- Publicación original de Abdur Rahim en X: La publicación referenciada que anunciaba DSpark ejecutándose en Apple Silicon.
- Repositorio de mlx-dspark en GitHub: Instalación, uso, modelos compatibles y notas de benchmarks para la implementación en Apple Silicon.
- Repositorio de DeepSpec en GitHub: Repositorio oficial de DeepSeek para algoritmos de decodificación especulativa y checkpoints publicados.
- PDF del artículo de DSpark: El artículo técnico incluido en el repositorio DeepSpec.
- Colección DFlash en Hugging Face: La colección de z-lab para modelos borrador relacionados con DFlash.
- Documentación de MLX: Documentación oficial del framework MLX de Apple.
- Repositorio de MLX en GitHub: Repositorio fuente del framework de aprendizaje automático para Apple Silicon.
Resumen
Este artículo explica cómo el método de decodificación especulativa DSpark de DeepSeek se adaptó a Apple Silicon mediante mlx-dspark, haciendo que la inferencia local en Mac sea más rápida para los modelos Gemma y Qwen compatibles.
El punto clave es que la adaptación no se trata solo de velocidad bruta. También se centra en mantener la fidelidad de salida al permitir que el modelo objetivo verifique los tokens generados, incluido el soporte para el comportamiento de decodificación muestreada.
La integración de DFlash añade otra opción útil,
especialmente para tareas de programación y matemáticas, donde redactar bloques largos puede dar buenos resultados. Para chats abiertos, DSpark aún puede ser la opción más adecuada, porque mantener una longitud aceptada es más difícil.
Para el desarrollo local de IA en Mac, mlx-dspark ofrece a los usuarios de Apple Silicon una forma práctica de probar una inferencia de LLM más rápida sin trasladarlo todo a un servidor.