DeepSeek DSpark kommt auf Apple Silicon: Lokale LLM-Beschleunigung auf dem Mac mit mlx-dspark
Dieser Artikel erklärt, wie DeepSeeks spekulatives Decoding-Verfahren DSpark über mlx-dspark auf Apple Silicon portiert wurde und dadurch lokale Inferenz auf dem Mac für unterstützte Gemma- und Qwen-Modelle schneller macht. Der entscheidende Punkt ist, dass es bei der Portierung nicht nur um reine Geschwindigkeit geht. Sie konzentriert sich auch darauf, die Ausgabetreue zu erhalten, indem das Zielmodell die generierten Tokens verifiziert, einschließlich Unterstützung für Sampling-basiertes Decoding-Verhalten. Die DFlash-Integration bietet eine weitere nützliche Option, insbesondere für Code- und Mathematikaufgaben, bei denen sich das Entwerfen langer Blöcke auszahlen kann. Für offene Chats ist DSpark möglicherweise weiterhin die bessere Wahl, da es schwieriger ist, eine hohe akzeptierte Länge aufrechtzuerhalten. **Für lokale KI-Entwicklung auf dem Mac bietet mlx-dspark Apple-Silicon-Nutzern eine praktische Möglichkeit, schnellere LLM-Inferenz zu testen, ohne alles auf einen Server verlagern zu müssen.**

DeepSeek DSpark kommt auf Apple Silicon: lokale LLM-Beschleunigung auf dem Mac mit mlx-dspark
Einführung
DeepSeeks DSpark war erst etwa eine Woche lang Open Source, bevor die Community es auf Apple-Computer brachte.
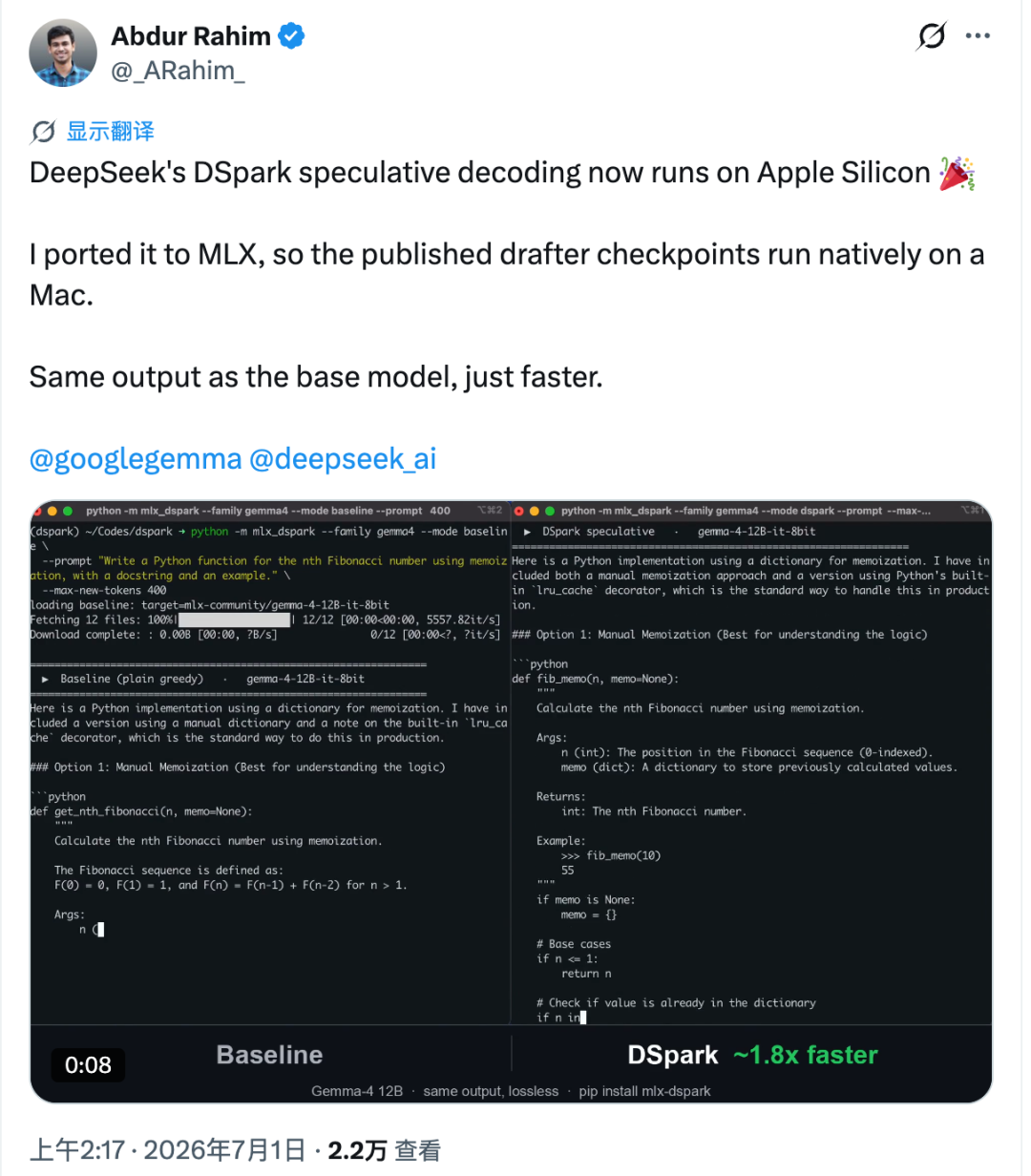
Die Portierung heißt mlx-dspark. Sie führt spekulatives Decoding im DSpark-Stil nativ auf Apple Silicon über Apples MLX-Ökosystem aus, mit Tests auf Modellen wie Gemma-4 12B und Qwen3-4B. In den gemeldeten Mac-Benchmarks wurde die Generierung mit Gemma-4 12B etwa 1,6× schneller, während Qwen3-4B sich um etwa 1,4× verbesserte.
Interessant ist dabei nicht nur die Geschwindigkeit. Die Portierung zielt darauf ab, die generierte Ausgabe mit dem zugrunde liegenden Zielmodell in Einklang zu halten, sodass die Beschleunigung nicht einfach durch eine Veränderung des Modellverhaltens erreicht wird.
Quellen- und Bildhinweise
- Quellartikel: DeepSeek新技术移植苹果芯片!Mac本地大模型加速60%
- Ursprünglicher Quellenhinweis auf der Seite: Der Artikel wurde von WeChat / QbitAI erneut veröffentlicht.
- Diese Markdown-Version ist eine SEO-fertige englische Adaption auf Basis der Fakten aus der Quelle und öffentlichen Projektseiten. Sie ist keine vollständige Zeile-für-Zeile-Übersetzung des Originalartikels.
- Der Quellartikel enthielt keine ausführbaren Befehlsblöcke oder Konfigurationsdateien. Daher wurden keine Codeblöcke entfernt oder verändert.
- Die unten enthaltenen Bilder sind inhaltlich relevante Screenshots aus dem Quellartikel. QR-Codes, Aufforderungen zum Folgen, Kommentar-UI und dekorative Plattformelemente wurden nicht als eigenständige Inhalte aufgenommen.
Apple Silicon kann jetzt lokale LLM-Beschleunigung im DSpark-Stil ausführen
DeepSeek veröffentlichte DSpark am 27. Juni als Ansatz für spekulatives Decoding. In seinem ursprünglichen serverseitigen Einsatzszenario wurde DSpark als Methode beschrieben, mit der sich die Generierungsgeschwindigkeit unter bestimmten Serving-Bedingungen um etwa 60 % bis 85 % steigern lässt.
Zunächst konzentrierte sich die verfügbare Implementierung jedoch auf GPU-Umgebungen in Rechenzentren. Es handelte sich nicht um einen nativen Apple-Silicon-Workflow. Das änderte sich mit mlx-dspark, einer von Abdur Rahim entwickelten Implementierung für MLX-basierte Inferenz auf dem Mac.

Die Idee hinter DSpark ist auf hoher Ebene leicht verständlich:
- Ein kleineres Draft-Modell schlägt im Voraus mehrere Kandidaten-Tokens vor.
- Das größere Zielmodell überprüft diese Tokens.
- Akzeptierte Tokens werden beibehalten.
- Abgelehnte Tokens werden über den normalen Pfad des Zielmodells neu generiert.
Das ist der Kern des spekulativen Decodings: Ein günstigerer Draft-Pfad rät voraus, anschließend überprüft das Zielmodell die Korrektheit.
Auf Server-GPUs kann die Verifizierung einer Gruppe von Tokens relativ effizient sein, weil der Engpass häufig eher in der Speicherbewegung als in reiner Rechenleistung liegt. In diesem Szenario verursacht die Überprüfung einiger zusätzlicher Tokens möglicherweise nur geringe Mehrkosten.
Apple Silicon verhält sich anders. Auf einem Mac kann jedes zusätzlich verifizierte Token eine deutlichere Latenz verursachen. Rahim hat diese Kosten gemessen und geschätzt, dass die obere Geschwindigkeitsgrenze für diese Art der Beschleunigung auf Apple Silicon unter den getesteten Bedingungen bei etwa 2,2× liegt.
Um dies praktisch nutzbar zu machen, überführte er die Draft-Checkpoints von Hugging Face in einen MLX-Workflow und kombinierte sie mit den Zielmodellen Gemma-4 12B und Qwen3-4B. Der Verifizierungsablauf wurde innerhalb von MLX neu aufgebaut, und die Draft-Gewichte wurden auf 4 Bit quantisiert.

In den gemeldeten Tests auf dem M4 Pro ergaben sich im Vergleich zu Apples offiziellen MLX-Tools folgende Werte:
- Gemma-4 12B stieg von etwa 18,4 tok/s auf rund 30 tok/s, also etwa 1,6× schneller.
- Qwen3-4B stieg von etwa 52,9 tok/s auf rund 73 tok/s, also etwa 1,4× schneller.
Für Entwickler lokaler KI-Anwendungen ist das ein bedeutender Gewinn. Ein MacBook ist nach wie vor kein Inferenzserver im Rechenzentrum, aber diese Art von Optimierung sorgt dafür, dass größere lokale Modelle für Entwicklung, Tests und persönliche Workflows deutlich praktikabler wirken.
Die Portierung legt außerdem Wert auf hochgetreue Ausgabe
Viele lokale Portierungen zur Beschleunigung großer Modelle konzentrieren sich zunächst auf Greedy Decoding. Beim Greedy Decoding wählt das Modell in jedem Schritt einfach das Token mit der höchsten Wahrscheinlichkeit aus. Das macht die Korrektheit leichter überprüfbar, weil die Ausgabe Token für Token verglichen werden kann.
mlx-dspark geht einen Schritt weiter, indem es die im DSpark-Paper beschriebene Temperature-Sampling-Methode implementiert. Das Draft-Modell schlägt Tokens vor, und das Zielmodell akzeptiert sie anhand einer wahrscheinlichkeitsbasierten Regel. Abgelehnte Teile werden erneut gesampelt aus
die verbleibende Verteilung.
Das ist wichtig, weil Sampling in vielen realen Anwendungen genutzt wird. Chat-Oberflächen, kreatives Schreiben, Agenten-Exploration und die Erstellung von Produkttexten setzen häufig auf Temperature statt auf strikt gieriges Decoding.
Rahim überprüfte, dass der Sampling-Ablauf die Verteilung des Zielmodells bei derselben Temperature-Einstellung beibehält. Anders gesagt: Das Ziel ist nicht, eine „ähnlich genug“ wirkende Annäherung zu erzeugen. Der Port ist so konzipiert, dass die Beschleunigung das beabsichtigte Ausgabeverhalten des Modells nicht verändert.
Während des Ports gab es außerdem einige praktische Erkenntnisse:
- Wenn das Draft-Modell mit einem Basis-Zielmodell statt mit dem passenden instruction-getunten Zielmodell kombiniert wird, kann die Akzeptanzrate stark sinken.
- Im berichteten Test erhöhte der Wechsel zum entsprechenden instruction-getunten Zielmodell die Akzeptanzrate von etwa 47 % auf etwa 82 %.
- Die Verwendung von bf16 für das Zielmodell erhöhte die Verifikationskosten stärker, als sie die Akzeptanz verbesserte, daher war das 8-Bit-Ziel-Setup in diesem Mac-Workflow praktischer.
- Das Draft-Modell wurde auf 4 Bit komprimiert und auf etwa 1,8 GB reduziert, wodurch es auf lokalen Rechnern leichter im Speicher gehalten werden kann.
Das Ergebnis ist eine lokale Implementierung, die mehr tut, als einfach nur schneller zu laufen. Sie versucht außerdem, das Verhalten beizubehalten, das Nutzer vom ursprünglichen Zielmodell erwarten.
DFlash wurde ebenfalls für schnellere Code- und Mathematikaufgaben integriert
Nachdem der mlx-dspark-Beitrag Aufmerksamkeit erregt hatte, kam DFlash in die Diskussion. Jian Chen, einer der Autoren hinter DFlash, fragte, ob das DFlash-Modell im selben Mac-Setup getestet werden könne.
DFlash ist ein weiterer Ansatz für spekulatives Decoding von z-lab. Sein Design unterscheidet sich von DSpark. Anstatt Kandidaten-Token Schritt für Schritt mit stärkerer Abhängigkeitsbehandlung zu erzeugen, verwendet DFlash ein blockdiffusionsartiges Verfahren, um einen ganzen Token-Block parallel zu entrauschen.
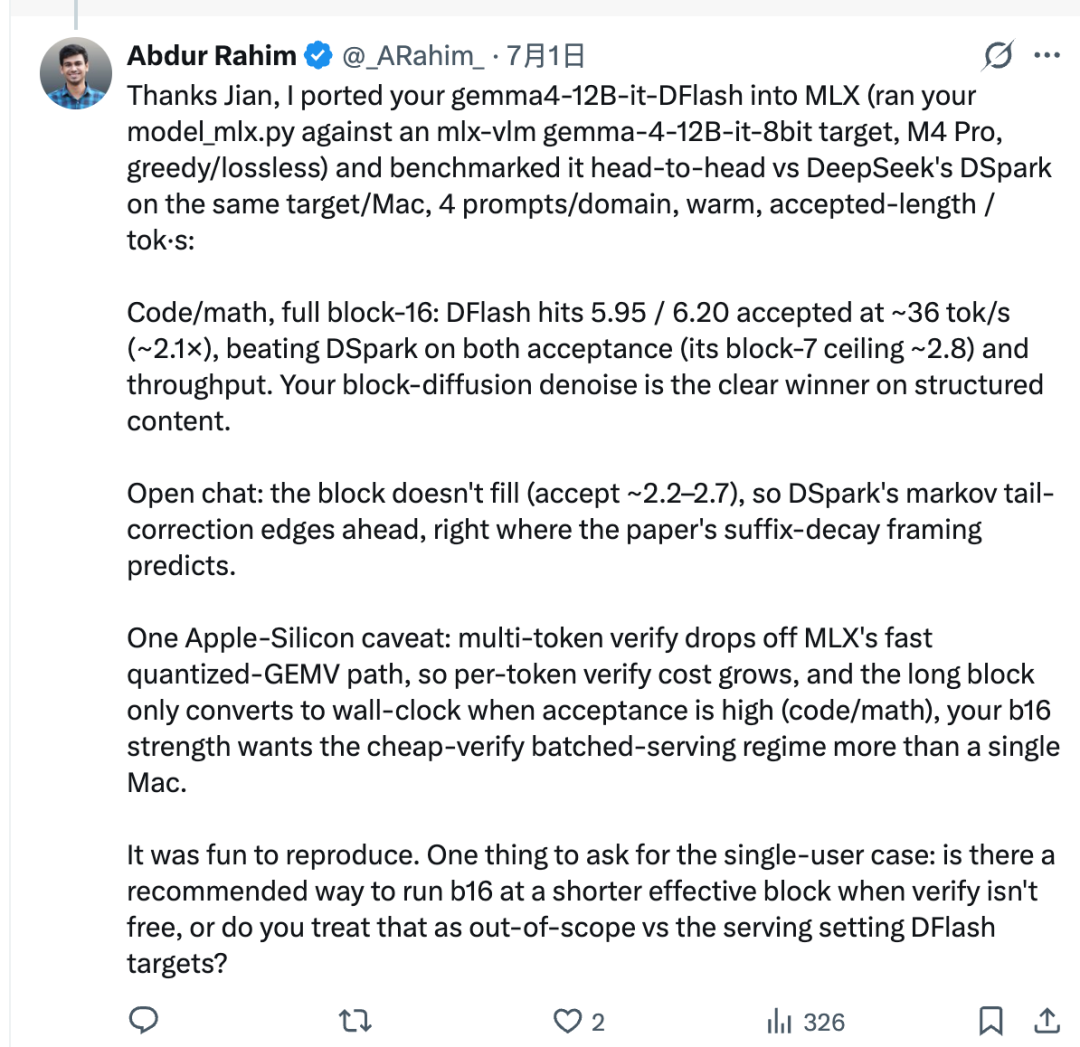
Im getesteten Setup nutzte Rahim Jians Portierungsskript, um z-lab/gemma4-12B-it-DFlash mit dem MLX-basierten Gemma-4-Zielmodell zu verbinden. Anschließend verglich er DFlash und DSpark auf demselben Mac.
Bei strukturierten Aufgaben wie Code und Mathematik schnitt DFlash sehr gut ab. Die akzeptierte Länge erreichte etwa 5,95 bis 6,20, und der Durchsatz lag bei etwa 36 tok/s, ungefähr 2,1× im berichteten Setup.

Das bedeutet jedoch nicht, dass DFlash immer besser ist. DFlash entwirft einen vollständigen Block von 16 Token auf einmal, aber das Zielmodell akzeptiert nicht immer den gesamten Block. Die Anzahl der akzeptierten Token wird als akzeptierte Länge bezeichnet.
In offenen Chats sind die nächsten Token schwieriger vorherzusagen. Die akzeptierte Länge kann niedriger bleiben, was bedeutet, dass der vollständige 16-Token-Block nicht in einen echten Geschwindigkeitsvorteil übersetzt wird. In einer solchen Umgebung kann DSpark schneller sein, weil sein Markov-Head darauf ausgelegt ist, das Problem des „Suffix Decay“ zu reduzieren, das bei parallelem Token-Drafting häufig auftritt.
Ein späteres mlx-dspark-Update fügte den ursprünglichen DFlash-Pfad von z-lab direkt in das Paket ein. Außerdem wurde ein Parameter zur Anpassung der effektiven Blocklänge ergänzt. Das gibt Nutzern eine flexiblere Wahl:
- Kürzere Blöcke für chatähnliche Aufgaben verwenden.
- Den vollständigen 16-Token-Block für Code- und Mathematikaufgaben verwenden.
- DSpark und DFlash im selben Paket vergleichen, statt zwischen getrennten Projekten zu wechseln.
Dadurch wirkt mlx-dspark weniger wie ein Experiment mit einer einzelnen Methode und stärker wie ein praktisches lokales Inferenz-Toolkit für Apple-Silicon-Nutzer.
Warum das für lokale KI-Entwicklung wichtig ist
Lokale LLM-Workflows werden für Entwickler, Forschende und kleine Teams immer häufiger. Modelle lokal auszuführen bietet mehr Kontrolle über Latenz, Datenverarbeitung, Experimente und Offline-Workflows.
Doch lokale Inferenz hat oft eine schmerzhafte Einschränkung: Geschwindigkeit. Selbst wenn ein Modell in den Speicher passt, kann die Generierung langsam wirken.
mlx-dspark ist interessant, weil es dieses Problem angeht, ohne ein vollständig neues Zielmodell zu erfordern. Es nutzt spekulatives Decoding, um das vorhandene Modell schneller wirken zu lassen, während das Zielmodell die Ausgabe weiterhin verifizieren kann.
Für Entwickler, die lokale KI-Apps auf dem Mac bauen, könnte das in mehreren Szenarien nützlich sein:
- Testen von KI
Funktionen, bevor sie zur Server-Inferenz übergehen.
2. Lokale Coding-Assistenten oder Dokumentenassistenten ausführen.
3. Decoding-Strategien für verschiedene Aufgabentypen vergleichen.
4. Leichtgewichtige lokale Dienste erstellen, die mit OpenAI kompatibel sind.
5. Bewerten, ob ein kleineres Mac-Setup für einen bestimmten Prototyp ausreicht.
Der Zielkonflikt bleibt wichtig. Eine Methode, die bei Code und Mathematik gut funktioniert, ist möglicherweise nicht die beste Wahl für offene Gespräche. Eine Methode, die auf einem M4 Pro gut abschneidet, kann sich auf älteren Apple-Silicon-Chips oder auf Rechnern mit begrenztem Arbeitsspeicher anders verhalten.
Die praktische Schlussfolgerung lautet also nicht: „Eine Methode gewinnt überall.“ Vielmehr bietet Apple Silicon nun einen stärkeren Weg, um mit DSpark, DFlash und MLX-nativem spekulativem Decoding zu experimentieren.
FAQ
Was ist DSpark?
DSpark ist eine Methode für spekulatives Decoding, die mit DeepSeeks DeepSpec-Projekt verbunden ist. Sie verwendet ein Draft-Modell, um Tokens im Voraus vorzuschlagen, und lässt das Zielmodell diese überprüfen, mit dem Ziel, die Inferenz zu beschleunigen und gleichzeitig das Ausgabeverhalten beizubehalten.
Was ist mlx-dspark?
mlx-dspark ist eine Community-Implementierung, die DSpark und spekulatives Decoding im DFlash-Stil über MLX auf Apple Silicon bringt. Sie ermöglicht unterstützten Gemma- und Qwen-Zielmodellen, auf dem Mac mit Draft-Modell-Beschleunigung zu laufen.
Läuft DeepSeek-V4 lokal mit mlx-dspark?
Nein. Das mlx-dspark-Projekt erklärt, dass seine lokalen Mac-Zielmodelle dichte Modelle wie Gemma und Qwen sind, nicht DeepSeek-V4 selbst. Es verwendet DeepSeeks DSpark-Drafter-Methode, aber das Token erzeugende Zielmodell im Mac-Workflow ist Gemma oder Qwen.
Wie viel schneller ist DSpark auf dem Mac?
In den berichteten Tests verbesserte sich Gemma-4 12B von etwa 18,4 Tok/s auf etwa 30 Tok/s, während Qwen3-4B von etwa 52,9 Tok/s auf etwa 73 Tok/s zulegte. Die tatsächliche Geschwindigkeit hängt vom Mac-Chip, dem Modell, der Präzision, dem Prompt-Typ und den Decoding-Einstellungen ab.
Was ist DFlash?
DFlash ist eine blockdiffusionsbasierte Methode für spekulatives Decoding von z-lab. Sie entwirft einen Block von Tokens parallel und kann besonders bei strukturierten Aufgaben wie Code und Mathematik effektiv sein, wenn die akzeptierte Länge hoch ist.
Ist DSpark besser als DFlash?
Nicht immer. DFlash kann bei Code- und Mathematikaufgaben besser abschneiden, während DSpark in offenen Chats stärker sein kann, bei denen lange parallele Blöcke schwieriger vorherzusagen sind. Die beste Wahl hängt vom Zielmodell und vom Aufgabentyp ab.
Brauche ich Apple Silicon, um mlx-dspark zu verwenden?
mlx-dspark ist über MLX für Apple Silicon konzipiert, daher ist ein Apple-Silicon-Mac die vorgesehene Umgebung. Außerdem sind eine kompatible Python-Umgebung und unterstützte Modellgewichte von Hugging Face oder aus lokalen Pfaden erforderlich.
Ist spekulatives Decoding für den Produktionseinsatz geeignet?
Das kann es sein, aber der Produktionseinsatz erfordert sorgfältiges Benchmarking. Sie müssen Ausgabetreue, Akzeptanzlänge, Latenz, Batching-Verhalten, Speichernutzung, Modellkompatibilität und hardwarespezifische Leistung prüfen, bevor Sie sich darauf verlassen.
Verwandte Tools
- mlx-dspark: Ein Community-Projekt, das spekulatives DSpark- und DFlash-Decoding nativ über MLX auf Apple Silicon ausführt.
- DeepSpec: DeepSeeks Full-Stack-Codebasis zum Trainieren und Evaluieren von Draft-Modellen für spekulatives Decoding.
- MLX: Apples Machine-Learning-Framework, das für effizientes Arbeiten auf Apple Silicon entwickelt wurde.
- z-lab/gemma4-12B-it-DFlash: Ein DFlash-Draft-Modell für instruction-tuned Workflows mit Gemma-4 12B.
- Hugging Face: Eine Plattform zum Hosten von Modellen, die von den in diesem Artikel erwähnten Projekten und Checkpoints genutzt wird.
- DeepSeek Hugging Face Organization: DeepSeeks offizielle Hugging-Face-Organisation für Modell- und Checkpoint-Veröffentlichungen.
Verwandte Links
- Quellartikel auf BAAI Hub: Der ursprüngliche chinesische Artikel, der den Apple-Silicon-Port von mlx-dspark vorstellte.
- Originaler X-Beitrag von Abdur Rahim: Der referenzierte Beitrag, der DSpark auf Apple Silicon ankündigte.
- mlx-dspark GitHub-Repository: Installation, Nutzung, unterstützte Modelle und Benchmark-Hinweise zur Apple-Silicon-Implementierung.
- DeepSpec GitHub-Repository: Offizielles DeepSeek-Repository für Algorithmen des spekulativen Decodings und veröffentlichte Checkpoints.
- DSpark Paper PDF: Das technische Paper im DeepSpec-Repository.
- DFlash Collection auf Hugging Face: Die Sammlung von z-lab für DFlash-bezogene Draft-Modelle.
- MLX-Dokumentation: Offizielle Dokumentation für Apples MLX-Framework.
- MLX GitHub-Repository: Quellrepository für das Machine-Learning-Framework für Apple Silicon.
Zusammenfassung
Dieser Artikel erklärt, wie DeepSeeks spekulative Decoding-Methode DSpark über mlx-dspark auf Apple Silicon portiert wurde und dadurch die lokale Mac-Inferenz für unterstützte Gemma- und Qwen-Modelle schneller macht.
Der entscheidende Punkt ist, dass es bei dem Port nicht nur um reine Geschwindigkeit geht. Er konzentriert sich auch darauf, die Ausgabetreue zu erhalten, indem das Zielmodell die generierten Tokens überprüft, einschließlich Unterstützung für Sample-Decoding-Verhalten.
Die DFlash-Integration fügt eine weitere nützliche Option hinzu,
insbesondere bei Code- und Mathematikaufgaben, bei denen sich das Ausarbeiten langer Blöcke lohnen kann. Für offene Chats ist DSpark möglicherweise weiterhin die bessere Wahl, da es schwieriger ist, eine akzeptierte Länge beizubehalten.
Für lokale KI-Entwicklung auf dem Mac bietet mlx-dspark Nutzern von Apple Silicon eine praktische Möglichkeit, schnellere LLM-Inferenz zu testen, ohne alles auf einen Server verlagern zu müssen.