DeepSeek DSparkがApple Siliconに対応:mlx-dsparkによるMacローカルLLM推論の高速化
この記事では、DeepSeekのDSpark投機的デコーディング手法がmlx-dsparkを通じてApple Siliconに移植され、対応するGemmaおよびQwenモデルでローカルMac推論を高速化する仕組みを解説します。 重要なのは、この移植が単なる処理速度の向上だけを目的としているわけではない点です。ターゲットモデルに生成されたトークンを検証させることで、サンプリングを用いたデコーディング動作への対応も含め、出力の忠実性を維持することにも重点を置いています。 DFlashとの統合により、特に長いブロックのドラフト生成が効果を発揮するコードや数学タスクにおいて、もう一つの有用な選択肢が加わります。一方で、オープンエンドなチャットでは受理される長さを維持するのが難しいため、DSparkのほうが依然として適している場合があります。 **MacベースのローカルAI開発において、mlx-dsparkはApple Siliconユーザーに、すべてをサーバーへ移行することなく、より高速なLLM推論を試せる実用的な手段を提供します。**

DeepSeek DSparkがApple Siliconに登場:mlx-dsparkによるMacローカルLLM高速化
はじめに
DeepSeekのDSparkがオープンソース化されてから、わずか約1週間でコミュニティはそれをAppleコンピュータ上に移植しました。
この移植版は mlx-dspark と呼ばれています。AppleのMLXエコシステムを通じて、Apple Silicon上でDSparkスタイルの投機的デコーディングをネイティブに実行でき、Gemma-4 12B や Qwen3-4B などのモデルでテストされています。報告されたMacでのベンチマークでは、Gemma-4 12Bの生成速度は約 1.6倍、Qwen3-4Bは約 1.4倍 に向上しました。
さらに興味深いのは、単なる速度向上だけではありません。この移植版は、生成される出力をベースとなるターゲットモデルと一致させることを目指しており、モデルの挙動を単純に変えることで高速化を実現しているわけではありません。
出典と画像に関する注記
- 出典記事:DeepSeek新技术移植苹果芯片!Mac本地大模型加速60%
- 元ページの出典注記:この記事はWeChat / QbitAIから転載されたものです。
- このMarkdown版は、出典の事実情報と公開プロジェクトページに基づく、SEO向けの英語版アダプテーションです。元記事を一行ずつ完全に翻訳したものではありません。
- 出典記事には、実行可能なコマンドブロックや設定ファイルは含まれていませんでした。そのため、コードブロックの削除や変更は行っていません。
- 以下に含まれる画像は、出典記事本文に関連するスクリーンショットです。QRコード、フォロー促進表示、コメントUI、装飾的なプラットフォーム要素は、単独のコンテンツとしては含めていません。
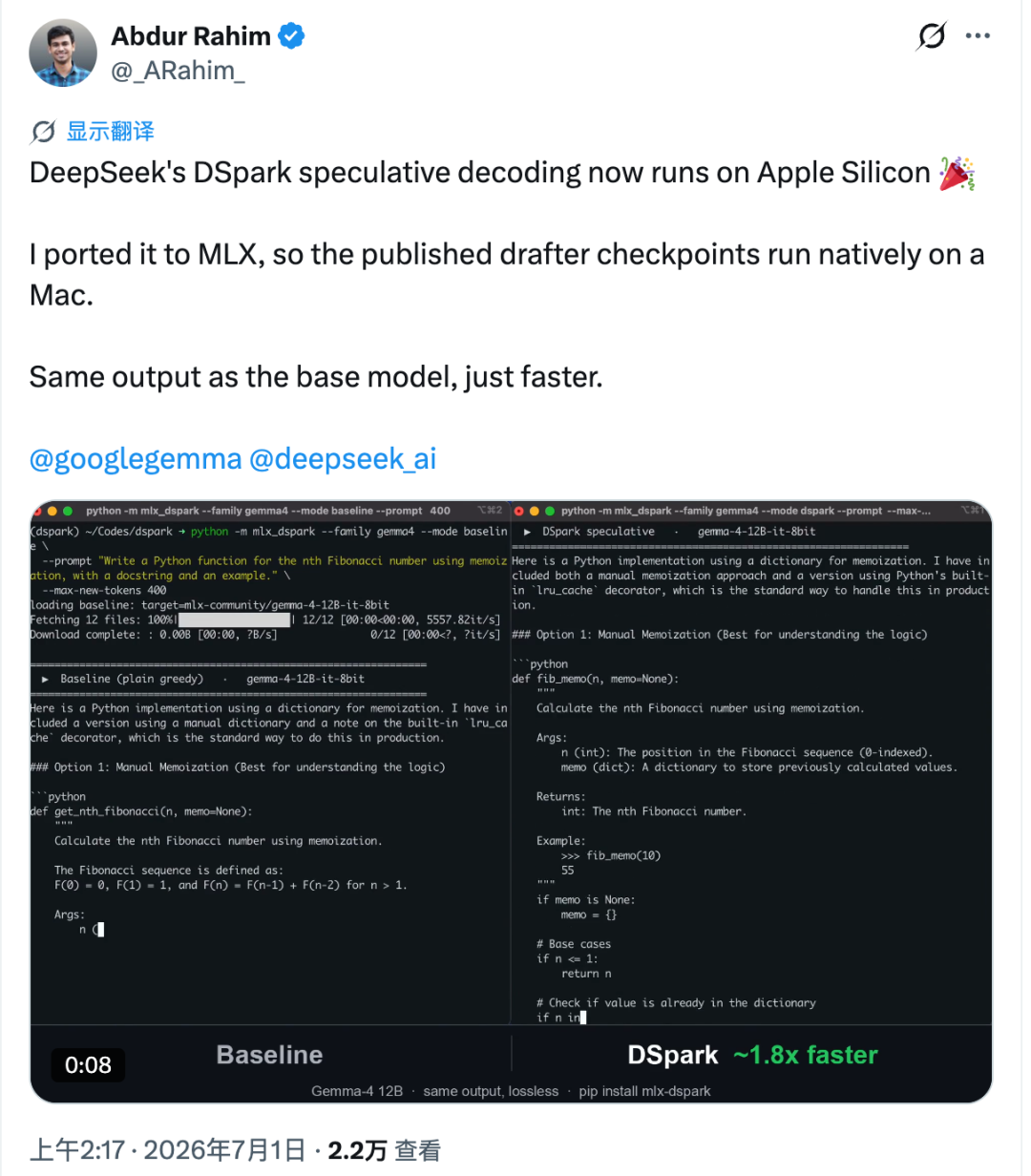
Apple SiliconでDSparkスタイルのローカルLLM高速化が可能に
DeepSeekは6月27日、投機的デコーディング手法としてDSparkを公開しました。元のサーバー側の環境では、DSparkは特定のサービング条件下で生成速度を約 60%〜85% 向上させる方法として説明されていました。
しかし当初、利用可能な実装はデータセンター向けGPU環境に焦点を当てたものでした。Apple Silicon向けのネイティブなワークフローではありませんでした。これを変えたのが、Abdur Rahimによって作成されたMac上のMLXベース推論向け実装である mlx-dspark です。

DSparkの背後にある考え方は、高いレベルでは簡単に理解できます。
- 小さなドラフトモデルが、複数の候補トークンを先に提案します。
- 大きなターゲットモデルが、それらのトークンを検証します。
- 受理されたトークンは保持されます。
- 拒否されたトークンは、通常のターゲットモデルの経路で再生成されます。
これが投機的デコーディングの核心です。低コストなドラフト経路に先読みをさせ、その後ターゲットモデルに正しさを検証させます。
サーバーGPUでは、ボトルネックが純粋な計算よりもメモリ移動であることが多いため、トークンのまとまりを検証する処理は比較的効率的に行えます。そのような環境では、追加でいくつかのトークンをチェックしても、コストはそれほど増えない場合があります。
Apple Siliconでは挙動が異なります。Macでは、検証するトークンが1つ増えるごとに、より目に見えるレイテンシが発生する可能性があります。Rahimはこのコストを測定し、Apple Silicon上では、テスト条件下におけるこのスタイルの高速化の上限は約 2.2倍 だと推定しました。
実用化するために、彼はドラフトチェックポイントをHugging FaceからMLXワークフローへ移し、Gemma-4 12BおよびQwen3-4Bのターゲットモデルと組み合わせました。検証フローはMLX内で再構築され、ドラフト重みは4ビットに量子化されました。

報告されたM4 Proでのテストでは、Apple公式のMLXツールと比較して次の結果が示されています。
- Gemma-4 12B は約 18.4 tok/s から約 30 tok/s に向上し、約 1.6倍高速 になりました。
- Qwen3-4B は約 52.9 tok/s から約 73 tok/s に向上し、約 1.4倍高速 になりました。
ローカルAIを構築する開発者にとって、これは意味のある改善です。MacBookは依然としてデータセンターの推論サーバーではありませんが、この種の最適化により、より大きなローカルモデルを開発、テスト、個人のワークフローでより実用的に感じられるようになります。
この移植版は高忠実度な出力にも重点を置いている
大規模モデル高速化のローカル移植の多くは、まず貪欲デコーディングに焦点を当てます。貪欲デコーディングでは、モデルは各ステップで最も確率の高いトークンを単純に選択します。これにより、出力をトークンごとに比較できるため、正しさをテストしやすくなります。
mlx-dsparkはさらに進んで、DSpark論文で説明されている温度付きサンプリング手法を実装しています。ドラフトモデルがトークンを提案し、ターゲットモデルが確率ベースのルールを用いてそれらを受理します。拒否された部分は再サンプリングされます。
残りの分布。
これが重要なのは、サンプリングが多くの実際のアプリケーションで使われているからです。チャットインターフェース、創作文章、エージェントの探索、商品コピー生成では、厳密な貪欲デコーディングではなく、temperature に依存することがよくあります。
Rahim は、同じ temperature 設定のもとで、サンプリングフローがターゲットモデルの分布を保持していることを確認しました。言い換えると、目標は「十分に似た」近似を生成することではありません。この移植は、高速化によってモデル本来の出力挙動が変わらないように設計されています。
移植の過程では、いくつかの実践的な教訓もありました。
- ドラフトモデルを、対応する instruction-tuned ターゲットではなくベースのターゲットモデルと組み合わせると、受理率が急激に低下する可能性がある。
- 報告されたテストでは、対応する instruction-tuned ターゲットに切り替えることで、受理率が約 47% から約 82% に上昇した。
- ターゲットモデルに bf16 を使うと、受理率の改善よりも検証コストの増加のほうが大きかったため、この Mac ワークフローでは 8-bit ターゲット構成のほうが実用的だった。
- ドラフトモデルは 4-bit に圧縮され、約 1.8 GB まで小さくなったため、ローカルマシンのメモリに保持しやすくなった。
その結果、単に高速に動作するだけではないローカル実装が生まれました。元のターゲットモデルに対してユーザーが期待する挙動を保つことも目指しています。
DFlash も統合され、コード・数学タスクが高速化
mlx-dspark の投稿が注目を集めたあと、DFlash も議論に加わりました。DFlash の作者の一人である Jian Chen は、DFlash モデルを同じ Mac 環境でテストできるかどうかを尋ねました。
DFlash は、z-lab による別の投機的デコーディング手法です。その設計は DSpark とは異なります。候補トークンを依存関係をより強く扱いながら逐次生成するのではなく、DFlash はブロック拡散型の手法を使い、トークンのブロック全体を並列にノイズ除去します。
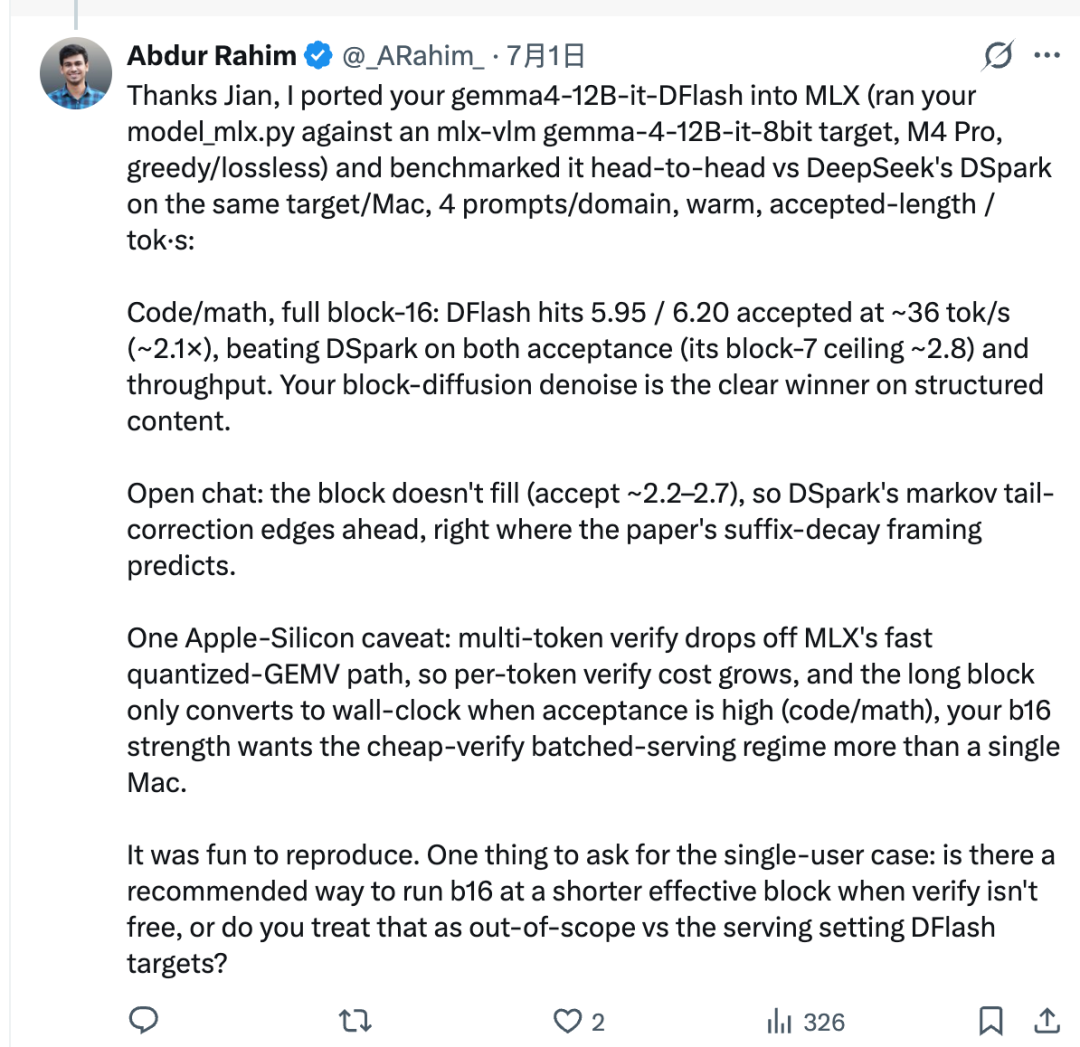
テストされた構成では、Rahim は Jian の移植スクリプトを使って z-lab/gemma4-12B-it-DFlash を MLX ベースの Gemma-4 ターゲットモデルに接続しました。そのうえで、同じ Mac 上で DFlash と DSpark を比較しました。
コードや数学のような構造化タスクでは、DFlash は非常に優れた性能を示しました。受理長は約 5.95〜6.20 に達し、スループットは約 36 tok/s、報告された設定ではおよそ 2.1倍 でした。

ただし、これは DFlash が常に優れているという意味ではありません。DFlash は一度に 16 トークンのブロック全体をドラフトしますが、ターゲットモデルが常にそのブロック全体を受理するわけではありません。受理されたトークン数は 受理長 と呼ばれます。
オープンエンドなチャットでは、次のトークンの予測がより難しくなります。受理長が低いままになる可能性があり、その場合、16 トークンの完全なブロックは実際の速度上の利点にはつながりません。このような設定では、DSpark のほうが速くなることがあります。これは、DSpark のマルコフヘッドが、並列トークンドラフトでよく現れる「サフィックス減衰」問題を低減するように設計されているためです。
その後の mlx-dspark のアップデートでは、z-lab のオリジナル DFlash パスがパッケージに直接追加されました。また、有効ブロック長を調整するためのパラメータも追加されました。これにより、ユーザーはより柔軟に選択できるようになりました。
- チャットのようなタスクでは短いブロックを使う。
- コードや数学タスクでは 16 トークンの完全なブロックを使う。
- 別々のプロジェクトを切り替えるのではなく、同じパッケージ内で DSpark と DFlash を比較する。
これにより、mlx-dspark は単一手法の実験というより、Apple Silicon ユーザー向けの実用的なローカル推論ツールキットに近づきました。
これがローカル AI 開発にとって重要な理由
ローカル LLM ワークフローは、開発者、研究者、小規模チームの間でますます一般的になっています。モデルをローカルで実行すると、レイテンシ、データの扱い、実験、オフラインワークフローをより細かく制御できます。
しかし、ローカル推論にはしばしば厄介な制約があります。それは速度です。モデルがメモリに収まる場合でも、生成は遅く感じられることがあります。
mlx-dspark が興味深いのは、まったく新しいターゲットモデルを必要とせずにこの問題に取り組んでいる点です。投機的デコーディングを使って既存のモデルをより高速に感じられるようにしつつ、ターゲットモデルが出力を検証できるようにしています。
Mac 上でローカル AI アプリを構築する開発者にとって、これはいくつかの場面で有用になり得ます。
- AI のテスト
サーバー推論へ移行する前の機能。
2. ローカルのコーディングアシスタントやドキュメントアシスタントを実行すること。
3. タスクの種類ごとにデコード戦略を比較すること。
4. 軽量な OpenAI 互換のローカルサービスを構築すること。
5. 特定のプロトタイプに対して、より小規模な Mac 環境で十分かどうかを評価すること。
それでもトレードオフは重要です。コードや数学でうまく機能する方法が、自由な会話に最適とは限りません。M4 Pro で良好に動作する方法が、古い Apple Silicon チップやメモリ制約のあるマシンでは異なる挙動を示す場合もあります。
したがって実践的な結論は、「1つの方法があらゆる場面で勝つ」ということではありません。Apple Silicon では現在、DSpark、DFlash、そして MLX ネイティブの投機的デコードを試すためのより強力な道筋が整った、ということです。
FAQ
DSpark とは何ですか?
DSpark は、DeepSeek の DeepSpec プロジェクトに関連する投機的デコード手法です。ドラフトモデルを使ってトークンを先に提案し、ターゲットモデルにそれらを検証させることで、出力の挙動を維持しながら推論を高速化することを目指します。
mlx-dspark とは何ですか?
mlx-dspark は、MLX を通じて DSpark および DFlash 形式の投機的デコードを Apple Silicon にもたらすコミュニティ実装です。対応する Gemma および Qwen のターゲットモデルを、Mac 上でドラフトモデルによる高速化付きで実行できます。
mlx-dspark は DeepSeek-V4 をローカルで実行できますか?
いいえ。mlx-dspark プロジェクトでは、ローカル Mac 向けのターゲットは Gemma や Qwen などの密なモデルであり、DeepSeek-V4 自体ではないと説明されています。DeepSeek の DSpark ドラフト手法を使用しますが、Mac のワークフローで実際にトークンを生成するターゲットモデルは Gemma または Qwen です。
Mac 上で DSpark はどのくらい高速ですか?
報告されたテストでは、Gemma-4 12B は約 18.4 tok/s から約 30 tok/s に向上し、Qwen3-4B は約 52.9 tok/s から約 73 tok/s に向上しました。実際の速度は、Mac のチップ、モデル、精度、プロンプトの種類、デコード設定によって異なります。
DFlash とは何ですか?
DFlash は、z-lab によるブロック拡散型の投機的デコード手法です。トークンのブロックを並列にドラフト生成し、受理される長さが長い場合、コードや数学のような構造化タスクで特に効果を発揮することがあります。
DSpark は DFlash より優れていますか?
常にそうとは限りません。DFlash はコードや数学タスクでより優れた性能を示す場合があり、一方で DSpark は長い並列ブロックの予測が難しい自由形式のチャットでより強みを発揮することがあります。最適な選択は、ターゲットモデルとタスクの種類によって異なります。
mlx-dspark を使うには Apple Silicon が必要ですか?
mlx-dspark は MLX を通じて Apple Silicon 向けに設計されているため、Apple Silicon 搭載 Mac が想定環境です。また、互換性のある Python 環境と、Hugging Face またはローカルパスにある対応モデルの重みも必要です。
投機的デコードは本番環境に適していますか?
適している場合もありますが、本番利用には慎重なベンチマークが必要です。実際に依存する前に、出力の忠実性、受理長、レイテンシ、バッチ処理の挙動、メモリ使用量、モデル互換性、ハードウェア固有の性能を確認する必要があります。
関連ツール
- mlx-dspark: MLX を通じて Apple Silicon 上で DSpark と DFlash の投機的デコードをネイティブに実行するコミュニティプロジェクト。
- DeepSpec: 投機的デコード用ドラフトモデルの学習と評価を行うための DeepSeek のフルスタックコードベース。
- MLX: Apple Silicon 上で効率的に作業するために設計された Apple の機械学習フレームワーク。
- z-lab/gemma4-12B-it-DFlash: Gemma-4 12B の命令チューニング済みワークフロー向け DFlash ドラフトモデル。
- Hugging Face: この記事で言及されているプロジェクトやチェックポイントで使用されるモデルホスティングプラットフォーム。
- DeepSeek Hugging Face Organization: モデルおよびチェックポイントのリリースを行う DeepSeek の公式 Hugging Face 組織。
関連リンク
- BAAI Hub の元記事: mlx-dspark の Apple Silicon 移植を紹介した元の中国語記事。
- Abdur Rahim の元の X 投稿: Apple Silicon 上で DSpark が動作することを発表した参照元の投稿。
- mlx-dspark GitHub リポジトリ: Apple Silicon 実装のインストール、使用方法、対応モデル、ベンチマークメモ。
- DeepSpec GitHub リポジトリ: 投機的デコードアルゴリズムと公開チェックポイントのための DeepSeek 公式リポジトリ。
- DSpark 論文 PDF: DeepSpec リポジトリに含まれる技術論文。
- Hugging Face の DFlash コレクション: DFlash 関連ドラフトモデルのための z-lab のコレクション。
- MLX ドキュメント: Apple の MLX フレームワークの公式ドキュメント。
- MLX GitHub リポジトリ: Apple Silicon 向け機械学習フレームワークのソースリポジトリ。
まとめ
この記事では、DeepSeek の DSpark 投機的デコード手法が mlx-dspark を通じて Apple Silicon に移植され、対応する Gemma および Qwen モデルのローカル Mac 推論が高速化された仕組みを説明しました。
重要な点は、この移植が単なる生の速度向上だけを目的としているわけではないことです。サンプリング付きデコードの挙動への対応を含め、生成されたトークンをターゲットモデルに検証させることで、出力の忠実性を維持することにも重点を置いています。
DFlash の統合により、もう1つの有用な選択肢が追加されます。
特にコードや数学のタスクでは、長いブロックを下書きすることが効果を発揮する場合があります。自由度の高いチャットでは、許容される長さを維持するのが難しいため、DSpark のほうが依然として適しているかもしれません。
Mac ベースのローカル AI 開発において、mlx-dspark は Apple Silicon ユーザーに、すべてをサーバーへ移行することなく、より高速な LLM 推論を試せる実用的な手段を提供します。