DeepSeek DSpark arriva su Apple Silicon: accelerazione degli LLM locali su Mac con mlx-dspark
Questo articolo spiega come il metodo di decodifica speculativa DSpark di DeepSeek sia stato portato su Apple Silicon tramite mlx-dspark, rendendo più veloce l’inferenza locale su Mac per i modelli Gemma e Qwen supportati. Il punto chiave è che il porting non riguarda solo la velocità pura. Si concentra anche sul mantenimento della fedeltà dell’output, consentendo al modello target di verificare i token generati, incluso il supporto per il comportamento di decodifica campionata. L’integrazione di DFlash aggiunge un’altra opzione utile, soprattutto per attività di programmazione e matematica in cui la generazione di blocchi lunghi può dare buoni risultati. Per le chat aperte, DSpark può comunque essere la scelta più adatta, perché è più difficile mantenere una lunghezza accettata stabile. **Per lo sviluppo di IA locale su Mac, mlx-dspark offre agli utenti Apple Silicon un modo pratico per testare un’inferenza LLM più veloce senza spostare tutto su un server.**

DeepSeek DSpark arriva su Apple Silicon: accelerazione locale degli LLM su Mac con mlx-dspark
Introduzione
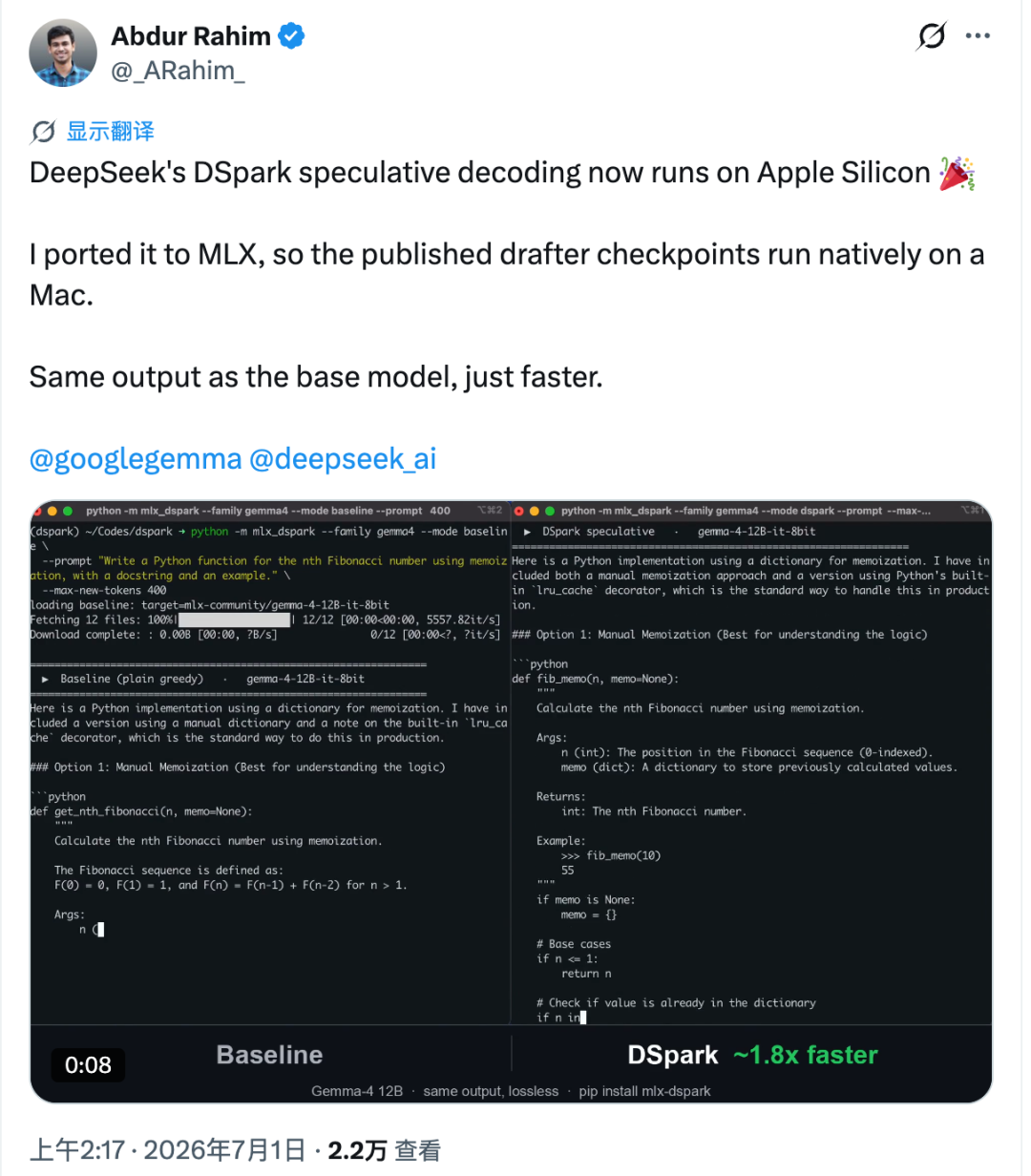
DSpark di DeepSeek era open source da circa una settimana quando la community lo ha portato sui computer Apple.
Il porting si chiama mlx-dspark. Esegue nativamente su Apple Silicon la decodifica speculativa in stile DSpark tramite l’ecosistema MLX di Apple, con test su modelli come Gemma-4 12B e Qwen3-4B. Nei benchmark Mac riportati, la generazione con Gemma-4 12B è diventata circa 1,6× più veloce, mentre Qwen3-4B è migliorato di circa 1,4×.
Ciò che rende la cosa ancora più interessante non è solo la velocità. Il porting mira a mantenere l’output generato allineato al modello target di base, quindi l’accelerazione non viene ottenuta semplicemente cambiando il comportamento del modello.
Note su fonte e immagini
- Articolo fonte: DeepSeek新技术移植苹果芯片!Mac本地大模型加速60%
- Nota sulla fonte originale dalla pagina: l’articolo è stato ripubblicato da WeChat / QbitAI.
- Questa versione Markdown è un adattamento in inglese pronto per la SEO basato sui fatti della fonte e sulle pagine pubbliche del progetto. Non è una traduzione completa riga per riga dell’articolo originale.
- L’articolo fonte non conteneva blocchi di comandi eseguibili o file di configurazione. Pertanto, nessun blocco di codice è stato rimosso o modificato.
- Le immagini incluse di seguito sono gli screenshot rilevanti per il corpo del testo tratti dall’articolo fonte. Codici QR, inviti a seguire, interfacce dei commenti ed elementi decorativi della piattaforma non sono stati inclusi come contenuti autonomi.
Apple Silicon ora può eseguire l’accelerazione locale degli LLM in stile DSpark
DeepSeek ha rilasciato DSpark il 27 giugno come approccio di decodifica speculativa. Nella sua configurazione originale lato server, DSpark è stato descritto come un modo per aumentare la velocità di generazione di circa 60%-85% in specifiche condizioni di serving.
All’inizio, però, l’implementazione disponibile era focalizzata su ambienti GPU da data center. Non era un workflow nativo per Apple Silicon. Questo è cambiato con mlx-dspark, un’implementazione creata da Abdur Rahim per l’inferenza basata su MLX su Mac.

L’idea alla base di DSpark è facile da comprendere a grandi linee:
- Un modello draft più piccolo propone in anticipo diversi token candidati.
- Il modello target più grande controlla quei token.
- I token accettati vengono mantenuti.
- I token rifiutati vengono rigenerati tramite il normale percorso del modello target.
Questo è il nucleo della decodifica speculativa: lasciare che un percorso draft meno costoso anticipi delle ipotesi, quindi lasciare che il modello target verifichi la correttezza.
Sulle GPU server, verificare un gruppo di token può essere relativamente efficiente perché il collo di bottiglia è spesso il movimento della memoria più che il calcolo puro. In tale scenario, controllare qualche token extra potrebbe non aggiungere molto costo.
Apple Silicon si comporta diversamente. Su un Mac, ogni token verificato in più può aggiungere una latenza più visibile. Rahim ha misurato questo costo e ha stimato che, su Apple Silicon, il limite superiore di velocità per questo tipo di accelerazione sia di circa 2,2× nelle condizioni testate.
Per renderlo pratico, ha spostato i checkpoint draft da Hugging Face in un workflow MLX e li ha abbinati ai modelli target Gemma-4 12B e Qwen3-4B. Il flusso di verifica è stato ricostruito all’interno di MLX e i pesi draft sono stati quantizzati a 4 bit.

Nei test riportati su M4 Pro, rispetto agli strumenti MLX ufficiali di Apple:
- Gemma-4 12B è passato da circa 18,4 tok/s a circa 30 tok/s, cioè circa 1,6× più veloce.
- Qwen3-4B è passato da circa 52,9 tok/s a circa 73 tok/s, cioè circa 1,4× più veloce.
Per chi costruisce AI in locale, è un guadagno significativo. Un MacBook non è ancora un server di inferenza da data center, ma questo tipo di ottimizzazione rende i modelli locali più grandi più utilizzabili per sviluppo, test e workflow personali.
Il porting punta anche a un output ad alta fedeltà
Molti porting locali dell’accelerazione dei grandi modelli si concentrano prima sulla decodifica greedy. Nella decodifica greedy, il modello sceglie semplicemente il token con la probabilità più alta a ogni passaggio. Questo rende più facile testare la correttezza, perché l’output può essere confrontato token per token.
mlx-dspark va oltre implementando il metodo di campionamento con temperatura descritto nel paper di DSpark. Il modello draft propone token e il modello target li accetta usando una regola basata sulla probabilità. Le parti rifiutate vengono ricampionate da
la distribuzione rimanente.
Questo è importante perché il campionamento è ciò che molte applicazioni reali utilizzano. Interfacce di chat, scrittura creativa, esplorazione tramite agenti e generazione di testi per prodotti spesso si basano sulla temperatura anziché su una rigorosa decodifica greedy.
Rahim ha verificato che il flusso di campionamento preservi la distribuzione del modello target con la stessa impostazione di temperatura. In altre parole, l’obiettivo non è produrre un’approssimazione “abbastanza simile”. Il porting è progettato in modo che l’accelerazione non modifichi il comportamento di output previsto del modello.
Durante il porting sono emerse anche alcune lezioni pratiche:
- Se il modello draft viene abbinato a un modello target di base invece che al corrispondente target instruction-tuned, il tasso di accettazione può calare bruscamente.
- Nel test riportato, il passaggio al corrispondente target instruction-tuned ha aumentato il tasso di accettazione da circa 47% a circa 82%.
- L’uso di bf16 per il modello target ha aumentato il costo di verifica più di quanto abbia migliorato l’accettazione, quindi la configurazione target a 8 bit è risultata più pratica in questo workflow su Mac.
- Il modello draft è stato compresso a 4 bit e ridotto a circa 1,8 GB, rendendolo più facile da mantenere in memoria su macchine locali.
Il risultato è un’implementazione locale che fa più che semplicemente funzionare più velocemente. Cerca anche di preservare il comportamento che gli utenti si aspettano dal modello target originale.
DFlash è stato integrato anche per attività di codice e matematica più veloci
Dopo che il post su mlx-dspark ha attirato attenzione, DFlash è entrato nella discussione. Jian Chen, uno degli autori dietro DFlash, ha chiesto se il modello DFlash potesse essere testato nella stessa configurazione Mac.
DFlash è un altro approccio di decodifica speculativa di z-lab. Il suo design differisce da DSpark. Invece di generare token candidati passo dopo passo con una gestione più forte delle dipendenze, DFlash utilizza un metodo in stile diffusione a blocchi per denoising di un intero blocco di token in parallelo.
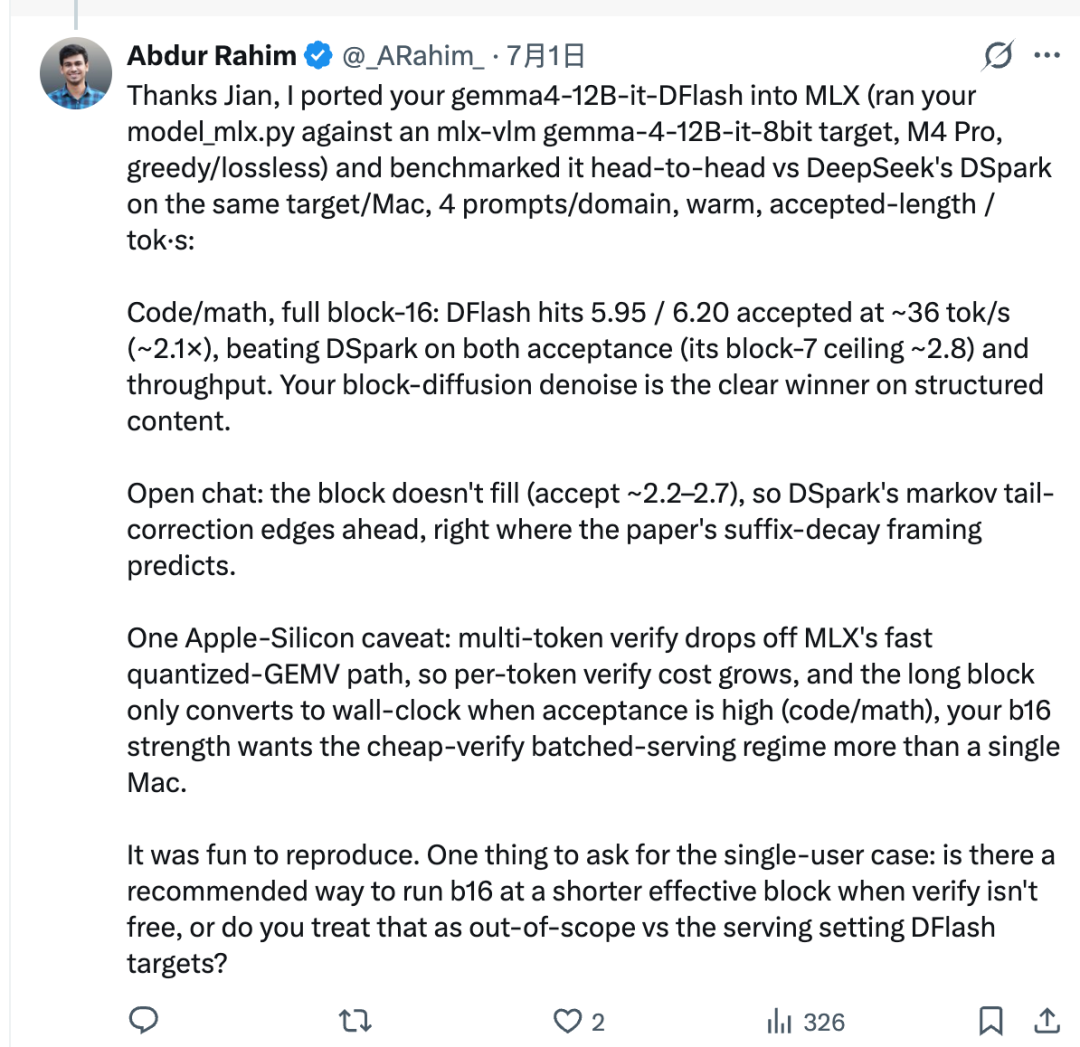
Nella configurazione testata, Rahim ha usato lo script di porting di Jian per collegare z-lab/gemma4-12B-it-DFlash al modello target Gemma-4 basato su MLX. Ha poi confrontato DFlash e DSpark sullo stesso Mac.
Per attività strutturate come codice e matematica, DFlash ha ottenuto ottimi risultati. La sua lunghezza accettata ha raggiunto circa 5,95–6,20, e il throughput ha raggiunto circa 36 tok/s, circa 2,1× nella configurazione riportata.

Questo non significa che DFlash sia sempre migliore. DFlash abbozza un blocco completo di 16 token alla volta, ma il modello target non accetta sempre l’intero blocco. Il numero di token accettati è chiamato lunghezza accettata.
Nelle chat aperte, i token successivi sono più difficili da prevedere. La lunghezza accettata può restare più bassa, il che significa che il blocco completo da 16 token non si traduce in un reale vantaggio di velocità. In quel tipo di scenario, DSpark può essere più veloce perché la sua testa di Markov è progettata per ridurre il problema del “decadimento del suffisso” che spesso compare nella generazione parallela di token draft.
Un aggiornamento successivo di mlx-dspark ha aggiunto direttamente nel pacchetto il percorso DFlash originale di z-lab. Ha anche aggiunto un parametro per regolare la lunghezza effettiva del blocco. Questo offre agli utenti una scelta più flessibile:
- Usare blocchi più brevi per attività simili alla chat.
- Usare il blocco completo da 16 token per attività di codice e matematica.
- Confrontare DSpark e DFlash nello stesso pacchetto invece di passare tra progetti separati.
Questo rende mlx-dspark meno simile a un esperimento basato su un singolo metodo e più simile a un toolkit pratico di inferenza locale per utenti Apple Silicon.
Perché questo è importante per lo sviluppo di IA locale
I workflow locali con LLM stanno diventando sempre più comuni per sviluppatori, ricercatori e piccoli team. Eseguire modelli localmente offre maggiore controllo su latenza, gestione dei dati, esperimenti e workflow offline.
Ma l’inferenza locale ha spesso una limitazione dolorosa: la velocità. Anche quando un modello entra in memoria, la generazione può sembrare lenta.
mlx-dspark è interessante perché affronta questo problema senza richiedere un modello target completamente nuovo. Usa la decodifica speculativa per far sembrare più veloce il modello esistente, consentendo comunque al modello target di verificare l’output.
Per gli sviluppatori che creano app di IA locali su Mac, questo potrebbe essere utile in diversi scenari:
- Testare app di IA
funzionalità prima di passare all’inferenza su server.
2. Esecuzione di assistenti locali per la programmazione o per i documenti.
3. Confronto tra strategie di decodifica per diversi tipi di attività.
4. Creazione di servizi locali leggeri compatibili con OpenAI.
5. Valutazione del fatto che una configurazione Mac più piccola sia sufficiente per uno specifico prototipo.
Il compromesso resta importante. Un metodo che funziona bene su codice e matematica potrebbe non essere la scelta migliore per conversazioni aperte. Un metodo che offre buone prestazioni su un M4 Pro potrebbe comportarsi diversamente su chip Apple Silicon più vecchi o su macchine con memoria limitata.
Quindi la conclusione pratica non è “un metodo vince ovunque”. È che Apple Silicon ora offre un percorso più solido per sperimentare con DSpark, DFlash e la decodifica speculativa nativa per MLX.
FAQ
Che cos’è DSpark?
DSpark è un metodo di decodifica speculativa associato al progetto DeepSpec di DeepSeek. Utilizza un modello draft per proporre token in anticipo e consente al modello target di verificarli, con l’obiettivo di accelerare l’inferenza preservando il comportamento dell’output.
Che cos’è mlx-dspark?
mlx-dspark è un’implementazione della community che porta la decodifica speculativa in stile DSpark e DFlash su Apple Silicon tramite MLX. Consente ai target Gemma e Qwen supportati di funzionare su Mac con accelerazione tramite modello draft.
mlx-dspark esegue DeepSeek-V4 localmente?
No. Il progetto mlx-dspark spiega che i suoi target locali su Mac sono modelli densi come Gemma e Qwen, non DeepSeek-V4 stesso. Utilizza il metodo drafter DSpark di DeepSeek, ma nel flusso di lavoro su Mac il modello target che produce i token è Gemma o Qwen.
Quanto è più veloce DSpark su Mac?
Nei test riportati, Gemma-4 12B è passato da circa 18,4 tok/s a circa 30 tok/s, mentre Qwen3-4B è passato da circa 52,9 tok/s a circa 73 tok/s. La velocità effettiva dipende dal chip del Mac, dal modello, dalla precisione, dal tipo di prompt e dalle impostazioni di decodifica.
Che cos’è DFlash?
DFlash è un metodo di decodifica speculativa a diffusione per blocchi sviluppato da z-lab. Genera in bozza un blocco di token in parallelo e può essere particolarmente efficace su attività strutturate come codice e matematica quando la lunghezza accettata è elevata.
DSpark è migliore di DFlash?
Non sempre. DFlash può offrire prestazioni migliori su attività di codice e matematica, mentre DSpark può essere più forte nelle chat aperte, dove i blocchi paralleli lunghi sono più difficili da prevedere. La scelta migliore dipende dal modello target e dal tipo di attività.
Ho bisogno di Apple Silicon per usare mlx-dspark?
mlx-dspark è progettato per Apple Silicon tramite MLX, quindi un Mac con Apple Silicon è l’ambiente previsto. Richiede inoltre una configurazione Python compatibile e pesi dei modelli supportati da Hugging Face o da percorsi locali.
La decodifica speculativa è adatta alla produzione?
Può esserlo, ma l’uso in produzione richiede benchmark accurati. Prima di farvi affidamento, è necessario verificare fedeltà dell’output, lunghezza di accettazione, latenza, comportamento del batching, uso della memoria, compatibilità dei modelli e prestazioni specifiche dell’hardware.
Strumenti correlati
- mlx-dspark: un progetto della community che esegue la decodifica speculativa DSpark e DFlash in modo nativo su Apple Silicon tramite MLX.
- DeepSpec: il codebase full-stack di DeepSeek per addestrare e valutare modelli draft di decodifica speculativa.
- MLX: il framework di machine learning di Apple progettato per lavorare in modo efficiente su Apple Silicon.
- z-lab/gemma4-12B-it-DFlash: un modello draft DFlash per flussi di lavoro Gemma-4 12B ottimizzati per istruzioni.
- Hugging Face: una piattaforma di hosting di modelli utilizzata dai progetti e dai checkpoint menzionati in questo articolo.
- Organizzazione DeepSeek su Hugging Face: l’organizzazione ufficiale di DeepSeek su Hugging Face per il rilascio di modelli e checkpoint.
Link correlati
- Articolo sorgente su BAAI Hub: l’articolo originale in cinese che ha introdotto il porting di mlx-dspark su Apple Silicon.
- Post originale di Abdur Rahim su X: il post citato che annunciava DSpark in esecuzione su Apple Silicon.
- Repository GitHub mlx-dspark: installazione, utilizzo, modelli supportati e note sui benchmark per l’implementazione Apple Silicon.
- Repository GitHub DeepSpec: repository ufficiale di DeepSeek per algoritmi di decodifica speculativa e checkpoint rilasciati.
- PDF del paper DSpark: il paper tecnico incluso nel repository DeepSpec.
- Collezione DFlash su Hugging Face: la collezione di z-lab per modelli draft relativi a DFlash.
- Documentazione MLX: documentazione ufficiale del framework MLX di Apple.
- Repository GitHub MLX: repository sorgente del framework di machine learning per Apple Silicon.
Riepilogo
Questo articolo spiega come il metodo di decodifica speculativa DSpark di DeepSeek sia stato portato su Apple Silicon tramite mlx-dspark, rendendo più veloce l’inferenza locale su Mac per i modelli Gemma e Qwen supportati.
Il punto chiave è che il porting non riguarda solo la velocità pura. Si concentra anche sul mantenimento della fedeltà dell’output, consentendo al modello target di verificare i token generati, incluso il supporto per il comportamento di decodifica campionata.
L’integrazione di DFlash aggiunge un’altra opzione utile,
soprattutto per attività di programmazione e matematica, dove la stesura di blocchi lunghi può dare buoni risultati. Per le chat aperte, DSpark potrebbe comunque essere la scelta più adatta, perché mantenere una lunghezza accettata è più difficile.
Per lo sviluppo locale di IA su Mac, mlx-dspark offre agli utenti Apple Silicon un modo pratico per testare un’inferenza LLM più rapida senza dover spostare tutto su un server.