DeepSeek DSpark arrive sur Apple Silicon : accélération des LLM locaux sur Mac avec mlx-dspark
Cet article explique comment la méthode de décodage spéculatif DSpark de DeepSeek a été portée sur Apple Silicon grâce à mlx-dspark, rendant l’inférence locale sur Mac plus rapide pour les modèles Gemma et Qwen pris en charge. Le point essentiel est que ce portage ne concerne pas seulement la vitesse brute. Il met aussi l’accent sur le maintien de la fidélité des sorties en permettant au modèle cible de vérifier les tokens générés, avec notamment la prise en charge du comportement de décodage par échantillonnage. L’intégration de DFlash ajoute une autre option utile, en particulier pour les tâches de code et de mathématiques où la génération de longs blocs préliminaires peut s’avérer rentable. Pour les conversations ouvertes, DSpark peut toutefois rester plus adapté, car il est plus difficile de maintenir une longueur acceptée. **Pour le développement d’IA locale sur Mac, mlx-dspark offre aux utilisateurs d’Apple Silicon un moyen pratique de tester une inférence LLM plus rapide sans tout déplacer vers un serveur.**

DeepSeek DSpark arrive sur Apple Silicon : accélération locale des LLM sur Mac avec mlx-dspark
Introduction
DSpark de DeepSeek n’était open source que depuis environ une semaine lorsque la communauté l’a porté sur les ordinateurs Apple.
Ce portage s’appelle mlx-dspark. Il exécute nativement le décodage spéculatif de type DSpark sur Apple Silicon via l’écosystème MLX d’Apple, avec des tests sur des modèles tels que Gemma-4 12B et Qwen3-4B. Dans les benchmarks Mac rapportés, la génération avec Gemma-4 12B est devenue environ 1,6× plus rapide, tandis que Qwen3-4B s’est amélioré d’environ 1,4×.
Ce qui rend cela encore plus intéressant, ce n’est pas seulement la vitesse. Le portage vise à maintenir la sortie générée alignée avec le modèle cible de base, de sorte que l’accélération ne soit pas obtenue en modifiant simplement le comportement du modèle.
Source et notes sur les images
- Article source : DeepSeek新技术移植苹果芯片!Mac本地大模型加速60%
- Note de source originale figurant sur la page : l’article a été republié depuis WeChat / QbitAI.
- Cette version Markdown est une adaptation en anglais prête pour le SEO, basée sur les faits de la source et les pages publiques du projet. Il ne s’agit pas d’une traduction intégrale ligne par ligne de l’article original.
- L’article source ne contenait pas de blocs de commandes exécutables ni de fichiers de configuration. Par conséquent, aucun bloc de code n’a été supprimé ou modifié.
- Les images incluses ci-dessous sont les captures d’écran pertinentes du corps de l’article source. Les QR codes, invites d’abonnement, interfaces de commentaires et éléments décoratifs de plateforme n’ont pas été inclus comme contenu autonome.
Apple Silicon peut désormais exécuter une accélération locale de LLM de type DSpark
DeepSeek a publié DSpark le 27 juin comme approche de décodage spéculatif. Dans son contexte serveur initial, DSpark était décrit comme un moyen d’augmenter la vitesse de génération d’environ 60 % à 85 % dans des conditions de service spécifiques.
Au départ, cependant, l’implémentation disponible se concentrait sur les environnements GPU de centres de données. Il ne s’agissait pas d’un workflow natif pour Apple Silicon. Cela a changé avec mlx-dspark, une implémentation créée par Abdur Rahim pour l’inférence sur Mac basée sur MLX.

L’idée derrière DSpark est facile à comprendre à haut niveau :
- Un modèle draft plus petit propose à l’avance plusieurs jetons candidats.
- Le modèle cible plus grand vérifie ces jetons.
- Les jetons acceptés sont conservés.
- Les jetons rejetés sont régénérés via le chemin normal du modèle cible.
C’est le principe du décodage spéculatif : laisser un chemin draft moins coûteux anticiper, puis laisser le modèle cible vérifier la justesse.
Sur les GPU de serveur, la vérification d’un groupe de jetons peut être relativement efficace, car le goulot d’étranglement est souvent le déplacement de mémoire plutôt que le calcul pur. Dans ce contexte, vérifier quelques jetons supplémentaires peut ne pas ajouter beaucoup de coût.
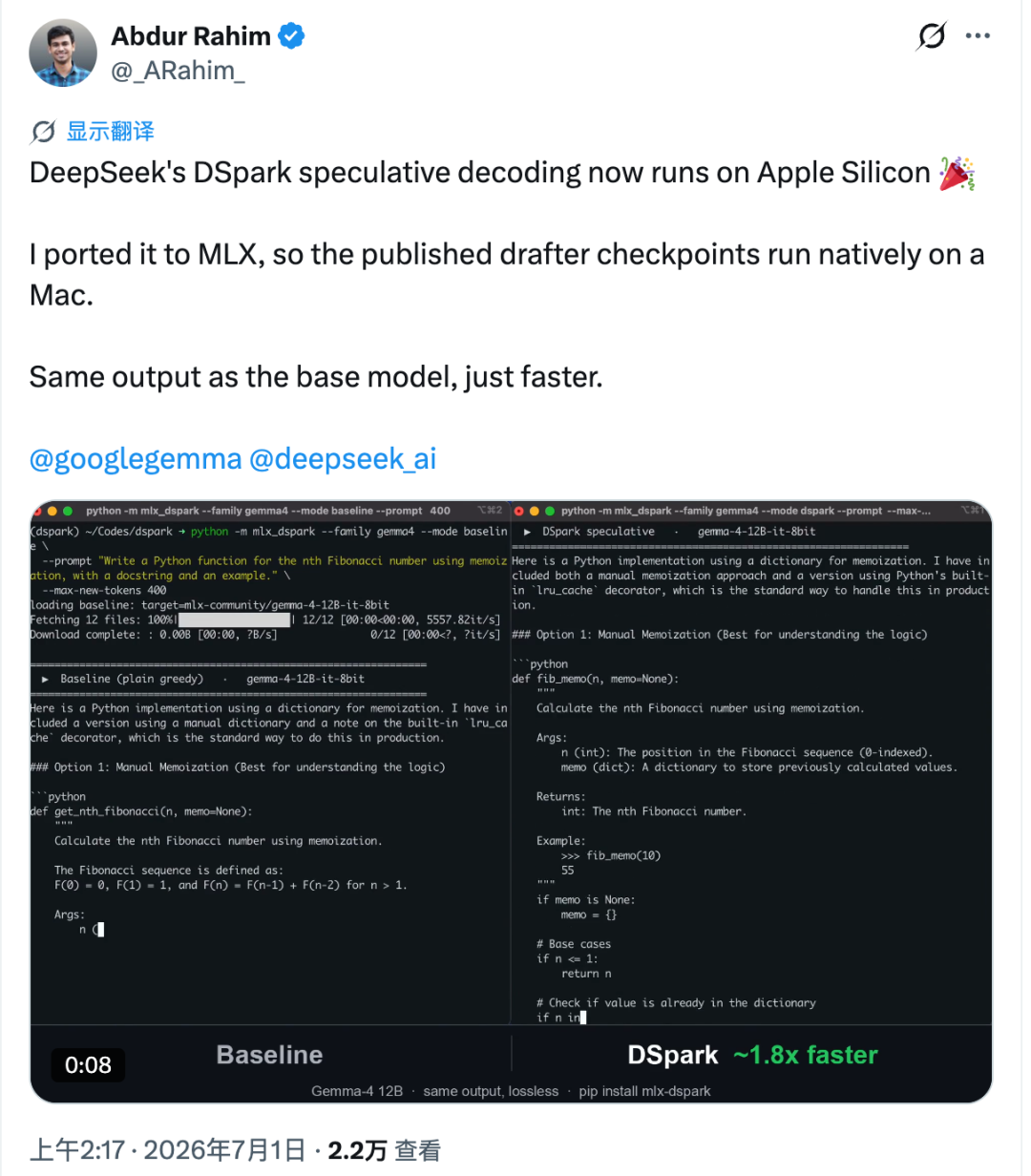
Apple Silicon se comporte différemment. Sur un Mac, chaque jeton vérifié supplémentaire peut ajouter une latence plus visible. Rahim a mesuré ce coût et estimé que, sur Apple Silicon, la limite supérieure de vitesse pour ce type d’accélération est d’environ 2,2× dans les conditions testées.
Pour rendre cela pratique, il a déplacé les checkpoints draft de Hugging Face vers un workflow MLX et les a associés aux modèles cibles Gemma-4 12B et Qwen3-4B. Le flux de vérification a été reconstruit dans MLX, et les poids draft ont été quantifiés en 4 bits.

Dans les tests rapportés sur M4 Pro, par rapport aux outils MLX officiels d’Apple :
- Gemma-4 12B est passé d’environ 18,4 tok/s à près de 30 tok/s, soit environ 1,6× plus rapide.
- Qwen3-4B est passé d’environ 52,9 tok/s à près de 73 tok/s, soit environ 1,4× plus rapide.
Pour les développeurs d’IA locale, c’est un gain significatif. Un MacBook n’est toujours pas un serveur d’inférence de centre de données, mais ce type d’optimisation rend les modèles locaux plus grands plus utilisables pour le développement, les tests et les workflows personnels.
Le portage met également l’accent sur une sortie haute fidélité
De nombreux portages locaux d’accélération de grands modèles se concentrent d’abord sur le décodage glouton. Dans le décodage glouton, le modèle choisit simplement le jeton ayant la probabilité la plus élevée à chaque étape. Cela rend la justesse plus facile à tester, car la sortie peut être comparée jeton par jeton.
mlx-dspark va plus loin en implémentant la méthode d’échantillonnage avec température décrite dans l’article DSpark. Le modèle draft propose des jetons, et le modèle cible les accepte selon une règle basée sur les probabilités. Les parties rejetées sont rééchantillonnées à partir de
la distribution restante.
C’est important, car l’échantillonnage est ce qu’utilisent de nombreuses applications réelles. Les interfaces de chat, l’écriture créative, l’exploration par agents et la génération de textes marketing s’appuient souvent sur la température plutôt que sur un décodage glouton strict.
Rahim a vérifié que le flux d’échantillonnage préserve la distribution du modèle cible avec le même réglage de température. Autrement dit, l’objectif n’est pas de produire une approximation « suffisamment similaire ». Le portage est conçu de sorte que l’accélération ne modifie pas le comportement de sortie attendu du modèle.
Quelques enseignements pratiques ont également été tirés pendant le portage :
- Si le modèle de brouillon est associé à un modèle cible de base au lieu du modèle cible instruction-tuned correspondant, le taux d’acceptation peut chuter fortement.
- Dans le test rapporté, le passage au modèle cible instruction-tuned correspondant a fait passer le taux d’acceptation d’environ 47 % à environ 82 %.
- L’utilisation de bf16 pour le modèle cible a davantage augmenté le coût de vérification qu’elle n’a amélioré l’acceptation ; la configuration cible en 8 bits était donc plus pratique dans ce flux de travail sur Mac.
- Le modèle de brouillon a été compressé en 4 bits et réduit à environ 1,8 Go, ce qui le rend plus facile à maintenir en mémoire sur des machines locales.
Le résultat est une implémentation locale qui ne se contente pas de fonctionner plus vite. Elle cherche aussi à préserver le comportement que les utilisateurs attendent du modèle cible d’origine.
DFlash a également été intégré pour accélérer les tâches de code et de mathématiques
Après que la publication sur mlx-dspark a attiré l’attention, DFlash est entré dans la discussion. Jian Chen, l’un des auteurs derrière DFlash, a demandé si le modèle DFlash pouvait être testé dans la même configuration Mac.
DFlash est une autre approche de décodage spéculatif issue de z-lab. Sa conception diffère de celle de DSpark. Au lieu de générer les tokens candidats étape par étape avec une meilleure gestion des dépendances, DFlash utilise une méthode de type diffusion par blocs pour débruiter un bloc entier de tokens en parallèle.
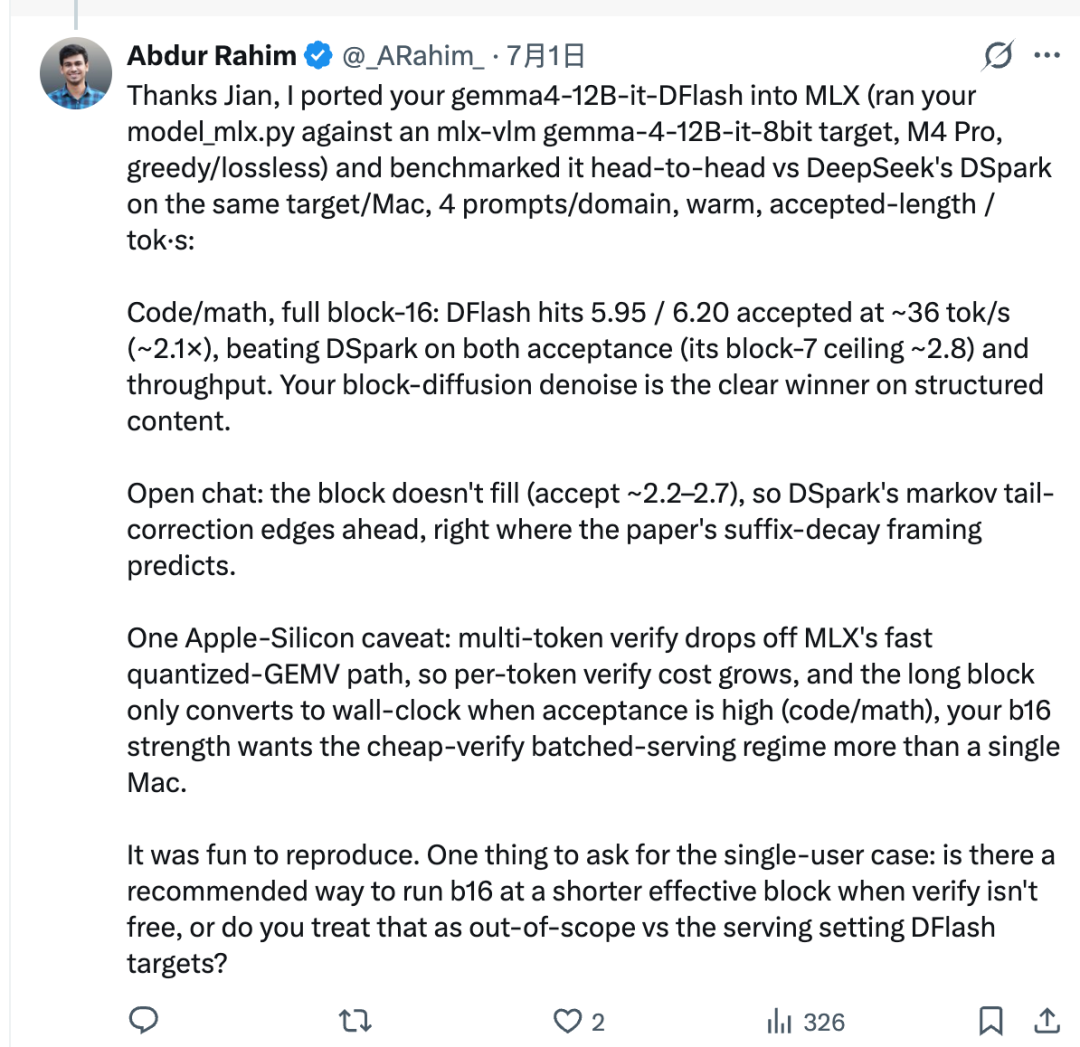
Dans la configuration testée, Rahim a utilisé le script de portage de Jian pour connecter z-lab/gemma4-12B-it-DFlash au modèle cible Gemma-4 basé sur MLX. Il a ensuite comparé DFlash et DSpark sur le même Mac.
Pour les tâches structurées telles que le code et les mathématiques, DFlash a très bien fonctionné. Sa longueur acceptée a atteint environ 5,95 à 6,20, et le débit a atteint environ 36 tok/s, soit environ 2,1× dans la configuration rapportée.

Cela ne signifie pas que DFlash est toujours meilleur. DFlash propose un bloc complet de 16 tokens à la fois, mais le modèle cible n’accepte pas toujours l’intégralité du bloc. Le nombre de tokens acceptés est appelé la longueur acceptée.
Dans le chat ouvert, les tokens suivants sont plus difficiles à prédire. La longueur acceptée peut rester plus faible, ce qui signifie que le bloc complet de 16 tokens ne se traduit pas par un véritable avantage de vitesse. Dans ce type de contexte, DSpark peut être plus rapide, car sa tête de Markov est conçue pour réduire le problème de « dégradation du suffixe » qui apparaît souvent dans la génération parallèle de tokens de brouillon.
Une mise à jour ultérieure de mlx-dspark a ajouté directement au package le chemin DFlash original de z-lab. Elle a également ajouté un paramètre permettant d’ajuster la longueur effective du bloc. Cela offre aux utilisateurs un choix plus flexible :
- Utiliser des blocs plus courts pour les tâches de type chat.
- Utiliser le bloc complet de 16 tokens pour les tâches de code et de mathématiques.
- Comparer DSpark et DFlash dans le même package au lieu de passer d’un projet séparé à l’autre.
Cela rend mlx-dspark moins semblable à une expérimentation reposant sur une seule méthode, et davantage à une boîte à outils pratique d’inférence locale pour les utilisateurs d’Apple Silicon.
Pourquoi cela compte pour le développement local de l’IA
Les flux de travail LLM locaux deviennent de plus en plus courants pour les développeurs, les chercheurs et les petites équipes. Exécuter des modèles localement offre un meilleur contrôle sur la latence, la gestion des données, les expériences et les flux de travail hors ligne.
Mais l’inférence locale présente souvent une limitation pénible : la vitesse. Même lorsqu’un modèle tient en mémoire, la génération peut sembler lente.
mlx-dspark est intéressant parce qu’il s’attaque à ce problème sans nécessiter un modèle cible entièrement nouveau. Il utilise le décodage spéculatif pour donner l’impression que le modèle existant est plus rapide, tout en laissant le modèle cible vérifier la sortie.
Pour les développeurs qui créent des applications d’IA locales sur Mac, cela pourrait être utile dans plusieurs scénarios :
- Tester l’IA
fonctionnalités avant de passer à l’inférence côté serveur.
2. Exécuter des assistants locaux de codage ou de documentation.
3. Comparer les stratégies de décodage pour différents types de tâches.
4. Créer des services locaux légers compatibles avec OpenAI.
5. Évaluer si une configuration Mac plus modeste suffit pour un prototype précis.
Le compromis reste important. Une méthode qui fonctionne bien pour le code et les mathématiques n’est pas forcément le meilleur choix pour une conversation ouverte. Une méthode performante sur un M4 Pro peut se comporter différemment sur d’anciennes puces Apple Silicon ou sur des machines limitées en mémoire.
Ainsi, la conclusion pratique n’est pas « une méthode gagne partout ». Elle est plutôt qu’Apple Silicon dispose désormais d’une voie plus solide pour expérimenter DSpark, DFlash et le décodage spéculatif natif MLX.
FAQ
Qu’est-ce que DSpark ?
DSpark est une méthode de décodage spéculatif associée au projet DeepSpec de DeepSeek. Elle utilise un modèle brouillon pour proposer des jetons à l’avance, puis laisse le modèle cible les vérifier, afin d’accélérer l’inférence tout en préservant le comportement de sortie.
Qu’est-ce que mlx-dspark ?
mlx-dspark est une implémentation communautaire qui apporte le décodage spéculatif de type DSpark et DFlash à Apple Silicon via MLX. Elle permet aux modèles cibles Gemma et Qwen pris en charge de fonctionner avec une accélération par modèle brouillon sur Mac.
mlx-dspark exécute-t-il DeepSeek-V4 localement ?
Non. Le projet mlx-dspark explique que ses modèles cibles locaux sur Mac sont des modèles denses tels que Gemma et Qwen, et non DeepSeek-V4 lui-même. Il utilise la méthode de brouillon DSpark de DeepSeek, mais le modèle cible qui produit les jetons dans le flux de travail Mac est Gemma ou Qwen.
À quel point DSpark est-il plus rapide sur Mac ?
Dans les tests rapportés, Gemma-4 12B est passé d’environ 18,4 tok/s à environ 30 tok/s, tandis que Qwen3-4B est passé d’environ 52,9 tok/s à environ 73 tok/s. La vitesse réelle dépend de la puce du Mac, du modèle, de la précision, du type de prompt et des paramètres de décodage.
Qu’est-ce que DFlash ?
DFlash est une méthode de décodage spéculatif par diffusion de blocs développée par z-lab. Elle génère en brouillon un bloc de jetons en parallèle et peut être particulièrement efficace sur des tâches structurées comme le code et les mathématiques lorsque la longueur acceptée est élevée.
DSpark est-il meilleur que DFlash ?
Pas toujours. DFlash peut être plus performant sur les tâches de code et de mathématiques, tandis que DSpark peut être plus solide dans les discussions ouvertes, où les longs blocs parallèles sont plus difficiles à prédire. Le meilleur choix dépend du modèle cible et du type de tâche.
Faut-il Apple Silicon pour utiliser mlx-dspark ?
mlx-dspark est conçu pour Apple Silicon via MLX ; un Mac Apple Silicon est donc l’environnement prévu. Il nécessite également une configuration Python compatible et des poids de modèles pris en charge provenant de Hugging Face ou de chemins locaux.
Le décodage spéculatif convient-il à la production ?
Il peut convenir, mais une utilisation en production exige une évaluation minutieuse. Vous devez vérifier la fidélité des sorties, la longueur d’acceptation, la latence, le comportement en traitement par lots, l’utilisation mémoire, la compatibilité des modèles et les performances propres au matériel avant de vous y fier.
Outils associés
- mlx-dspark : un projet communautaire qui exécute nativement le décodage spéculatif DSpark et DFlash sur Apple Silicon via MLX.
- DeepSpec : la base de code complète de DeepSeek pour l’entraînement et l’évaluation de modèles brouillons de décodage spéculatif.
- MLX : le framework d’apprentissage automatique d’Apple conçu pour un travail efficace sur Apple Silicon.
- z-lab/gemma4-12B-it-DFlash : un modèle brouillon DFlash pour les flux de travail Gemma-4 12B ajustés par instructions.
- Hugging Face : une plateforme d’hébergement de modèles utilisée par les projets et points de contrôle mentionnés dans cet article.
- Organisation DeepSeek sur Hugging Face : l’organisation officielle de DeepSeek sur Hugging Face pour les publications de modèles et de points de contrôle.
Liens associés
- Article source sur BAAI Hub : l’article chinois original qui a présenté le portage de mlx-dspark sur Apple Silicon.
- Publication X originale d’Abdur Rahim : la publication citée annonçant l’exécution de DSpark sur Apple Silicon.
- Dépôt GitHub mlx-dspark : installation, utilisation, modèles pris en charge et notes de benchmark pour l’implémentation Apple Silicon.
- Dépôt GitHub DeepSpec : dépôt officiel de DeepSeek pour les algorithmes de décodage spéculatif et les points de contrôle publiés.
- PDF de l’article DSpark : l’article technique inclus dans le dépôt DeepSpec.
- Collection DFlash sur Hugging Face : la collection de z-lab consacrée aux modèles brouillons liés à DFlash.
- Documentation MLX : documentation officielle du framework MLX d’Apple.
- Dépôt GitHub MLX : dépôt source du framework d’apprentissage automatique pour Apple Silicon.
Résumé
Cet article explique comment la méthode de décodage spéculatif DSpark de DeepSeek a été portée sur Apple Silicon via mlx-dspark, rendant l’inférence locale sur Mac plus rapide pour les modèles Gemma et Qwen pris en charge.
Le point clé est que ce portage ne concerne pas uniquement la vitesse brute. Il vise également à maintenir la fidélité des sorties en laissant le modèle cible vérifier les jetons générés, avec notamment la prise en charge du comportement de décodage échantillonné.
L’intégration de DFlash ajoute une autre option utile,
en particulier pour les tâches de code et de mathématiques, où la rédaction de longs blocs peut s’avérer payante. Pour les discussions ouvertes, DSpark peut toutefois rester le meilleur choix, car il est plus difficile de maintenir une longueur acceptable.
Pour le développement local d’IA sur Mac, mlx-dspark offre aux utilisateurs d’Apple Silicon un moyen pratique de tester une inférence LLM plus rapide sans tout déplacer vers un serveur.