وصول DeepSeek DSpark إلى Apple Silicon: تسريع نماذج اللغة الكبيرة محليًا على Mac باستخدام mlx-dspark
تشرح هذه المقالة كيف نُقلت طريقة فك الترميز التخميني DSpark من DeepSeek إلى Apple Silicon عبر mlx-dspark، مما يجعل الاستدلال المحلي على Mac أسرع لنماذج Gemma وQwen المدعومة. النقطة الأساسية هي أن هذا النقل لا يتعلق بالسرعة الخام فقط. فهو يركز أيضًا على الحفاظ على دقة المخرجات من خلال السماح للنموذج الهدف بالتحقق من الرموز المُولَّدة، بما في ذلك دعم سلوك فك الترميز القائم على أخذ العينات. يضيف تكامل DFlash خيارًا مفيدًا آخر، خصوصًا لمهام البرمجة والرياضيات حيث يمكن أن يكون لصياغة الكتل الطويلة مردود واضح. أما في المحادثات المفتوحة، فقد يظل DSpark الخيار الأنسب لأن الحفاظ على طول المقاطع المقبولة يكون أصعب. **بالنسبة لتطوير الذكاء الاصطناعي المحلي على أجهزة Mac، يمنح mlx-dspark مستخدمي Apple Silicon طريقة عملية لاختبار استدلال أسرع لنماذج اللغة الكبيرة دون نقل كل شيء إلى خادم.**

وصول DeepSeek DSpark إلى Apple Silicon: تسريع نماذج LLM المحلية على Mac باستخدام mlx-dspark
المقدمة
لم يمضِ سوى نحو أسبوع على فتح مصدر DSpark من DeepSeek حتى نقله المجتمع إلى حواسيب Apple.
يحمل هذا النقل اسم mlx-dspark. وهو يشغّل فك الترميز التخميني بأسلوب DSpark محليًا على Apple Silicon عبر منظومة MLX من Apple، مع اختبارات على نماذج مثل Gemma-4 12B وQwen3-4B. وفي اختبارات الأداء المعلنة على Mac، أصبح توليد Gemma-4 12B أسرع بنحو 1.6×، بينما تحسّن Qwen3-4B بنحو 1.4×.
ما يجعل الأمر أكثر إثارة للاهتمام ليس السرعة فقط. فهذا النقل يهدف إلى إبقاء المخرجات المُولّدة متوافقة مع نموذج الهدف الأساسي، بحيث لا يتحقق التسريع بمجرد تغيير سلوك النموذج.
ملاحظات حول المصدر والصور
- المقال المصدر: تقنية DeepSeek الجديدة تُنقل إلى شرائح Apple! تسريع نماذج الذكاء الاصطناعي الكبيرة المحلية على Mac بنسبة 60%
- ملاحظة المصدر الأصلية من الصفحة: أُعيد نشر المقال من WeChat / QbitAI.
- هذه النسخة بصيغة Markdown هي تكييف إنجليزي جاهز لتحسين محركات البحث، مبني على حقائق المصدر وصفحات المشروع العامة. وهي ليست ترجمة كاملة سطرًا بسطر للمقال الأصلي.
- لم يتضمن المقال المصدر كتل أوامر قابلة للتنفيذ أو ملفات إعداد. لذلك لم تتم إزالة أي كتل برمجية أو تعديلها.
- الصور المدرجة أدناه هي لقطات الشاشة ذات الصلة بمحتوى المقال من المصدر. لم تُدرج رموز QR، أو دعوات المتابعة، أو واجهة التعليقات، أو عناصر المنصة الزخرفية كمحتوى مستقل.
يمكن لـ Apple Silicon الآن تشغيل تسريع LLM المحلي بأسلوب DSpark
أطلقت DeepSeek تقنية DSpark في 27 يونيو باعتبارها نهجًا لفك الترميز التخميني. وفي بيئتها الأصلية من جهة الخادم، وُصفت DSpark بأنها طريقة لزيادة سرعة التوليد بنحو 60% إلى 85% في ظل ظروف خدمة محددة.
لكن التنفيذ المتاح في البداية كان يركز على بيئات وحدات GPU في مراكز البيانات. ولم يكن سير عمل محليًا أصيلًا على Apple Silicon. وقد تغيّر ذلك مع mlx-dspark، وهو تنفيذ أنشأه Abdur Rahim للاستدلال المعتمد على MLX على أجهزة Mac.

الفكرة وراء DSpark سهلة الفهم على مستوى عام:
- يقترح نموذج مسودة أصغر عدة رموز مرشحة مسبقًا.
- يتحقق نموذج الهدف الأكبر من تلك الرموز.
- تُحفظ الرموز المقبولة.
- تُعاد توليد الرموز المرفوضة عبر المسار العادي لنموذج الهدف.
هذا هو جوهر فك الترميز التخميني: دع مسار مسودة أقل تكلفة يتنبأ مسبقًا، ثم دع نموذج الهدف يتحقق من الصحة.
على وحدات GPU في الخوادم، يمكن أن يكون التحقق من مجموعة من الرموز فعالًا نسبيًا لأن عنق الزجاجة غالبًا ما يكون حركة الذاكرة لا الحسابات الخالصة. وفي هذه الحالة، قد لا يضيف التحقق من بضعة رموز إضافية تكلفة كبيرة.
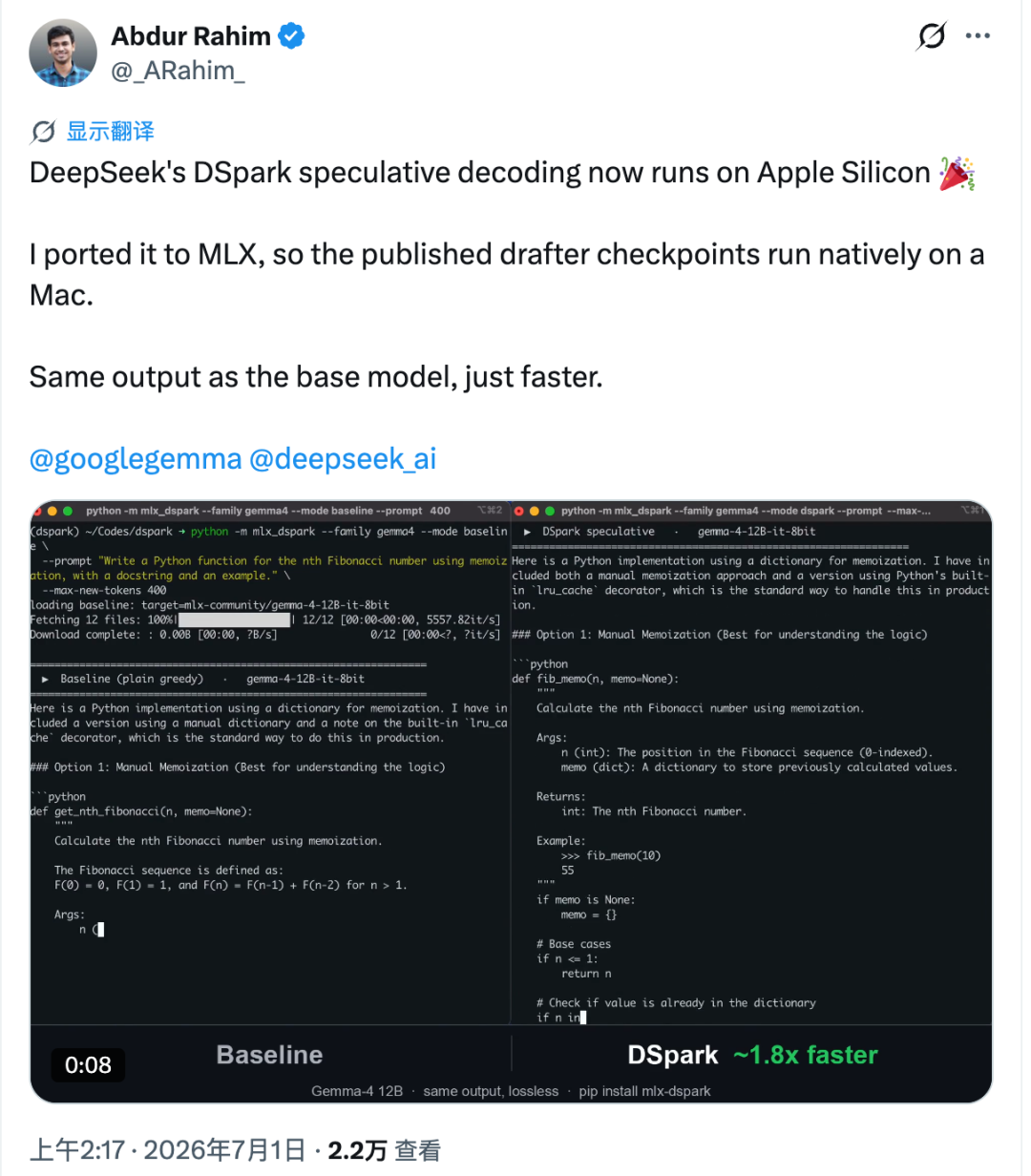
يتصرف Apple Silicon بطريقة مختلفة. فعلى جهاز Mac، يمكن أن يضيف كل رمز إضافي يتم التحقق منه زمن تأخير أكثر وضوحًا. قاس Rahim هذه التكلفة وقدّر أن الحد الأعلى للسرعة في هذا الأسلوب من التسريع على Apple Silicon يبلغ نحو 2.2× في ظل ظروف الاختبار.
ولجعله عمليًا، نقل نقاط تحقق المسودة من Hugging Face إلى سير عمل MLX، وربطها بنموذجي الهدف Gemma-4 12B وQwen3-4B. وأُعيد بناء مسار التحقق داخل MLX، كما تم تكميم أوزان المسودة إلى 4 بت.

في اختبارات M4 Pro المعلنة، وبالمقارنة مع أدوات MLX الرسمية من Apple:
- ارتفع أداء Gemma-4 12B من نحو 18.4 رمزًا/ثانية إلى حوالي 30 رمزًا/ثانية، أي أسرع بنحو 1.6×.
- ارتفع أداء Qwen3-4B من نحو 52.9 رمزًا/ثانية إلى حوالي 73 رمزًا/ثانية، أي أسرع بنحو 1.4×.
بالنسبة إلى مطوري الذكاء الاصطناعي المحلي، يُعد ذلك مكسبًا مهمًا. لا يزال MacBook ليس خادم استدلال في مركز بيانات، لكن هذا النوع من التحسين يجعل النماذج المحلية الأكبر حجمًا أكثر قابلية للاستخدام في التطوير والاختبار وسير العمل الشخصي.
يركز هذا النقل أيضًا على مخرجات عالية الدقة
تركز العديد من عمليات النقل المحلية لتسريع النماذج الكبيرة أولًا على فك الترميز الجشع. في فك الترميز الجشع، يختار النموذج ببساطة الرمز الأعلى احتمالًا في كل خطوة. وهذا يجعل اختبار الصحة أسهل لأن المخرجات يمكن مقارنتها رمزًا برمز.
يمضي mlx-dspark أبعد من ذلك عبر تنفيذ طريقة أخذ العينات بدرجة الحرارة الموصوفة في ورقة DSpark. يقترح نموذج المسودة رموزًا، ويقبلها نموذج الهدف باستخدام قاعدة قائمة على الاحتمالات. وتُعاد أخذ العينات للأجزاء المرفوضة من
التوزيع المتبقي.
هذا مهم لأن أخذ العينات هو ما تستخدمه كثير من التطبيقات الواقعية. فواجهات الدردشة، والكتابة الإبداعية، واستكشاف الوكلاء، وتوليد النصوص التسويقية للمنتجات تعتمد غالبًا على درجة الحرارة بدلًا من فك الترميز الجشع الصارم.
تحقق رحيم من أن مسار أخذ العينات يحافظ على توزيع النموذج الهدف عند إعداد درجة الحرارة نفسه. وبعبارة أخرى، ليس الهدف إنتاج تقريب «مشابه بما يكفي». فقد صُمم النقل بحيث لا يغيّر التسريع السلوك الإخراجي المقصود للنموذج.
كانت هناك أيضًا بعض الدروس العملية أثناء عملية النقل:
- إذا اقترن نموذج المسودة بنموذج هدف أساسي بدلًا من نموذج الهدف المطابق المضبوط بالتعليمات، فقد ينخفض معدل القبول بشكل حاد.
- في الاختبار المُبلّغ عنه، أدى الانتقال إلى نموذج الهدف المطابق المضبوط بالتعليمات إلى زيادة معدل القبول من نحو 47% إلى نحو 82%.
- استخدام bf16 للنموذج الهدف زاد تكلفة التحقق أكثر مما حسّن القبول، لذلك كان إعداد الهدف ذي 8 بت أكثر عملية في سير العمل هذا على أجهزة Mac.
- تم ضغط نموذج المسودة إلى 4 بت وتقليصه إلى نحو 1.8 غيغابايت، مما سهّل إبقاءه في الذاكرة على الأجهزة المحلية.
والنتيجة هي تنفيذ محلي لا يكتفي بالعمل بسرعة أكبر، بل يحاول أيضًا الحفاظ على السلوك الذي يتوقعه المستخدمون من النموذج الهدف الأصلي.
تم دمج DFlash أيضًا لتسريع مهام البرمجة والرياضيات
بعد أن لفت منشور mlx-dspark الانتباه، دخل DFlash النقاش. سأل جيان تشن، أحد المؤلفين وراء DFlash، عمّا إذا كان بالإمكان اختبار نموذج DFlash ضمن إعداد Mac نفسه.
DFlash هو نهج آخر لفك الترميز التخميني من z-lab. يختلف تصميمه عن DSpark. فبدلًا من توليد الرموز المرشحة خطوة بخطوة مع معالجة أقوى للاعتماديات، يستخدم DFlash أسلوبًا شبيهًا بالانتشار الكتلي لإزالة الضوضاء عن كتلة كاملة من الرموز بالتوازي.
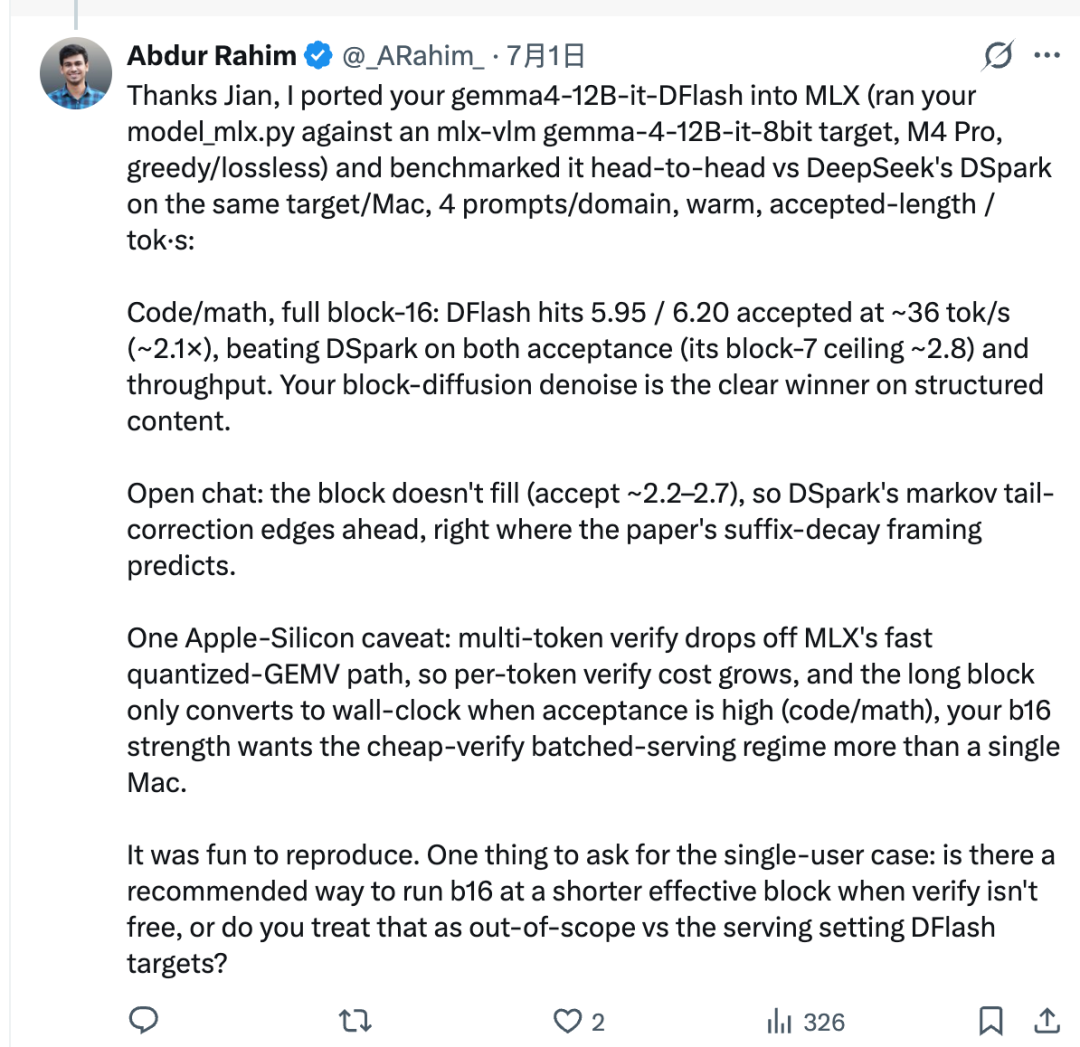
في الإعداد الذي تم اختباره، استخدم رحيم سكربت النقل الخاص بجيان لربط z-lab/gemma4-12B-it-DFlash بنموذج Gemma-4 الهدف المعتمد على MLX. ثم قارن بين DFlash وDSpark على جهاز Mac نفسه.
في المهام المنظمة مثل البرمجة والرياضيات، حقق DFlash أداءً جيدًا جدًا. فقد وصل طول القبول إلى نحو 5.95 إلى 6.20، وبلغت الإنتاجية نحو 36 رمزًا/ثانية، أي حوالي 2.1× في الإعداد المُبلّغ عنه.

هذا لا يعني أن DFlash أفضل دائمًا. فـ DFlash يصوغ كتلة كاملة من 16 رمزًا دفعة واحدة، لكن النموذج الهدف لا يقبل دائمًا الكتلة كاملة. ويُسمى عدد الرموز المقبولة طول القبول.
في الدردشة المفتوحة، تكون الرموز التالية أصعب في التنبؤ. وقد يبقى طول القبول أقل، مما يعني أن الكتلة الكاملة المكونة من 16 رمزًا لا تتحول إلى أفضلية سرعة حقيقية. في هذا النوع من الإعدادات، يمكن أن يكون DSpark أسرع لأن رأس ماركوف لديه مصمم لتقليل مشكلة «تدهور اللاحقة» التي تظهر كثيرًا في صياغة الرموز بالتوازي.
أضاف تحديث لاحق لـ mlx-dspark المسار الأصلي لـ DFlash من z-lab مباشرةً إلى الحزمة. كما أضاف معلمة لضبط طول الكتلة الفعلي. وهذا يمنح المستخدمين خيارًا أكثر مرونة:
- استخدام كتل أقصر للمهام الشبيهة بالدردشة.
- استخدام الكتلة الكاملة المكونة من 16 رمزًا لمهام البرمجة والرياضيات.
- مقارنة DSpark وDFlash ضمن الحزمة نفسها بدلًا من التنقل بين مشاريع منفصلة.
وهذا يجعل mlx-dspark أقل شبهًا بتجربة أحادية المنهج، وأكثر شبهًا بعدة أدوات عملية للاستدلال المحلي لمستخدمي Apple Silicon.
لماذا يهم هذا لتطوير الذكاء الاصطناعي المحلي
أصبحت سير عمل نماذج اللغة الكبيرة المحلية أكثر شيوعًا بين المطورين والباحثين والفرق الصغيرة. وتشغيل النماذج محليًا يمنح تحكمًا أكبر في زمن الاستجابة، ومعالجة البيانات، والتجارب، وسير العمل دون اتصال.
لكن الاستدلال المحلي غالبًا ما يواجه قيدًا مؤلمًا واحدًا: السرعة. فحتى عندما يكون النموذج مناسبًا للذاكرة، قد يبدو التوليد بطيئًا.
يُعد mlx-dspark مثيرًا للاهتمام لأنه يعالج هذه المشكلة من دون الحاجة إلى نموذج هدف جديد تمامًا. فهو يستخدم فك الترميز التخميني لجعل النموذج الحالي يبدو أسرع، مع الاستمرار في السماح للنموذج الهدف بالتحقق من المخرجات.
بالنسبة للمطورين الذين يبنون تطبيقات ذكاء اصطناعي محلية على Mac، قد يكون هذا مفيدًا في عدة سيناريوهات:
- اختبار الذكاء الاصطناعي
الميزات قبل الانتقال إلى الاستدلال على الخادم.
2. تشغيل مساعدي البرمجة المحليين أو مساعدي المستندات المحليين.
3. مقارنة استراتيجيات فك الترميز لأنواع مختلفة من المهام.
4. بناء خدمات محلية خفيفة متوافقة مع OpenAI.
5. تقييم ما إذا كان إعداد Mac أصغر يكفي لنموذج أولي محدد.
لا تزال المقايضة مهمة. فالطريقة التي تعمل جيدًا مع البرمجة والرياضيات قد لا تكون الخيار الأفضل للمحادثة المفتوحة. والطريقة التي تؤدي أداءً جيدًا على M4 Pro قد تتصرف بشكل مختلف على شرائح Apple Silicon الأقدم أو الأجهزة ذات الذاكرة المحدودة.
لذلك، الخلاصة العملية ليست أن «طريقة واحدة تفوز في كل مكان». بل إن Apple Silicon أصبح يوفر الآن مسارًا أقوى للتجريب باستخدام DSpark وDFlash وفك الترميز التخميني الأصلي في MLX.
الأسئلة الشائعة
ما هو DSpark؟
DSpark هو أسلوب لفك الترميز التخميني مرتبط بمشروع DeepSpec من DeepSeek. يستخدم نموذجًا مسودّة لاقتراح الرموز مسبقًا، ثم يتيح للنموذج الهدف التحقق منها، بهدف تسريع الاستدلال مع الحفاظ على سلوك المخرجات.
ما هو mlx-dspark؟
mlx-dspark هو تنفيذ مجتمعي يجلب أساليب فك الترميز التخميني من نمط DSpark وDFlash إلى Apple Silicon عبر MLX. وهو يتيح لأهداف Gemma وQwen المدعومة العمل بتسريع نموذج المسودّة على Mac.
هل يشغّل mlx-dspark نموذج DeepSeek-V4 محليًا؟
لا. يوضح مشروع mlx-dspark أن الأهداف المحلية على Mac هي نماذج كثيفة مثل Gemma وQwen، وليست DeepSeek-V4 نفسه. فهو يستخدم طريقة نموذج المسودّة DSpark من DeepSeek، لكن النموذج الهدف الذي ينتج الرموز في سير عمل Mac هو Gemma أو Qwen.
ما مدى سرعة DSpark على Mac؟
في الاختبارات المعلنة، تحسّن Gemma-4 12B من نحو 18.4 رمز/ثانية إلى نحو 30 رمز/ثانية، بينما تحسّن Qwen3-4B من نحو 52.9 رمز/ثانية إلى نحو 73 رمز/ثانية. تعتمد السرعة الفعلية على شريحة Mac، والنموذج، والدقة، ونوع الموجه، وإعدادات فك الترميز.
ما هو DFlash؟
DFlash هو أسلوب لفك الترميز التخميني بالانتشار الكتلي من z-lab. ينشئ مسودّة لكتلة من الرموز بالتوازي، ويمكن أن يكون فعالًا بشكل خاص في المهام المنظمة مثل البرمجة والرياضيات عندما يكون طول القبول مرتفعًا.
هل DSpark أفضل من DFlash؟
ليس دائمًا. قد يحقق DFlash أداءً أفضل في مهام البرمجة والرياضيات، بينما يمكن أن يكون DSpark أقوى في الدردشة المفتوحة حيث يصعب توقع الكتل المتوازية الطويلة. يعتمد الخيار الأفضل على النموذج الهدف ونوع المهمة.
هل أحتاج إلى Apple Silicon لاستخدام mlx-dspark؟
صُمم mlx-dspark للعمل على Apple Silicon عبر MLX، لذا فإن جهاز Mac يعمل بـ Apple Silicon هو البيئة المقصودة. كما يتطلب إعداد Python متوافقًا وأوزان نماذج مدعومة من Hugging Face أو من مسارات محلية.
هل فك الترميز التخميني مناسب للإنتاج؟
يمكن أن يكون مناسبًا، لكن استخدامه في الإنتاج يتطلب قياس أداء دقيقًا. يجب التحقق من أمانة المخرجات، وطول القبول، وزمن الاستجابة، وسلوك التجميع، واستخدام الذاكرة، وتوافق النماذج، والأداء الخاص بالأجهزة قبل الاعتماد عليه.
أدوات ذات صلة
- mlx-dspark: مشروع مجتمعي يشغّل فك الترميز التخميني بأسلوبي DSpark وDFlash محليًا على Apple Silicon عبر MLX.
- DeepSpec: قاعدة التعليمات البرمجية الكاملة من DeepSeek لتدريب وتقييم نماذج المسودّة لفك الترميز التخميني.
- MLX: إطار تعلم الآلة من Apple المصمم للعمل بكفاءة على Apple Silicon.
- z-lab/gemma4-12B-it-DFlash: نموذج مسودّة DFlash لسير عمل Gemma-4 12B المضبوط للتعليمات.
- Hugging Face: منصة لاستضافة النماذج تستخدمها المشاريع ونقاط التحقق المذكورة في هذه المقالة.
- منظمة DeepSeek على Hugging Face: المنظمة الرسمية لـ DeepSeek على Hugging Face لإصدارات النماذج ونقاط التحقق.
روابط ذات صلة
- المقالة المصدرية على BAAI Hub: المقالة الصينية الأصلية التي قدمت نقل mlx-dspark إلى Apple Silicon.
- منشور Abdur Rahim الأصلي على X: المنشور المشار إليه الذي أعلن تشغيل DSpark على Apple Silicon.
- مستودع mlx-dspark على GitHub: التثبيت، والاستخدام، والنماذج المدعومة، وملاحظات قياس الأداء لتنفيذ Apple Silicon.
- مستودع DeepSpec على GitHub: مستودع DeepSeek الرسمي لخوارزميات فك الترميز التخميني ونقاط التحقق المنشورة.
- ملف بحث DSpark بصيغة PDF: الورقة التقنية المضمنة في مستودع DeepSpec.
- مجموعة DFlash على Hugging Face: مجموعة z-lab لنماذج المسودّة ذات الصلة بـ DFlash.
- توثيق MLX: التوثيق الرسمي لإطار MLX من Apple.
- مستودع MLX على GitHub: مستودع المصدر لإطار تعلم الآلة على Apple Silicon.
الملخص
تشرح هذه المقالة كيف تم نقل أسلوب فك الترميز التخميني DSpark من DeepSeek إلى Apple Silicon عبر mlx-dspark، مما يجعل الاستدلال المحلي على Mac أسرع لنماذج Gemma وQwen المدعومة.
النقطة الأساسية هي أن هذا النقل لا يتعلق بالسرعة الخام فقط. فهو يركز أيضًا على الحفاظ على أمانة المخرجات من خلال السماح للنموذج الهدف بالتحقق من الرموز المولدة، بما في ذلك دعم سلوك فك الترميز بالعينة.
ويضيف تكامل DFlash خيارًا مفيدًا آخر،
خصوصًا في مهام البرمجة والرياضيات حيث قد تكون صياغة الكتل الطويلة مجدية. أما في المحادثات المفتوحة، فقد يظل DSpark الخيار الأنسب لأن الحفاظ على طول مقبول يكون أصعب.
بالنسبة إلى تطوير الذكاء الاصطناعي المحلي على أجهزة Mac، يوفّر mlx-dspark لمستخدمي Apple Silicon طريقة عملية لاختبار استدلال نماذج اللغة الكبيرة بسرعة أكبر من دون نقل كل شيء إلى خادم.