Atualização Semanal de Modelos de IA da HyperAI: Irodori-TTS, SAM-Audio, MatAnyone 2, PrismAudio e mais
Esta atualização semanal reúne um conjunto útil de novas demonstrações de IA e recursos de modelos, especialmente nas áreas de geração de áudio, reconhecimento de fala, processamento de vídeo, compreensão de imagens e OCR para documentos longos. As entradas mais práticas são o Irodori-TTS para geração de voz em japonês, o SAM-Audio para separação de sons baseada em prompts, o MatAnyone 2 para recorte limpo em vídeos, o Unlimited-OCR para documentos longos e o Nemotron 3.5 ASR para reconhecimento de fala em streaming. **No geral, este resumo é útil para leitores que querem descobrir rapidamente quais novos modelos de IA valem a pena testar, o que cada um faz e onde experimentá-los.**

Atualização semanal de modelos de IA da HyperAI: Irodori-TTS, SAM-Audio, MatAnyone 2, PrismAudio e mais
Introdução
A atualização desta semana da HyperAI concentra-se em uma combinação robusta de modelos de áudio, vídeo, compreensão de imagens, OCR e reconhecimento de fala. O projeto em destaque é o Irodori-TTS-500M-v3, um modelo aberto japonês de texto para fala que combina geração de fala de alta fidelidade a 48 kHz, clonagem de voz zero-shot e controle refinado de estilo por meio de anotações com emojis.
A atualização também inclui ferramentas para separação de áudio baseada em prompts, matting de vídeo, simulação de mundo 4D, geração de áudio a partir de vídeo, OCR de documentos, segmentação no dispositivo, edição expressiva de áudio e ASR em streaming de baixa latência. Abaixo está uma versão revisada e pronta para publicação do resumo semanal original, com as capturas de tela úteis preservadas em seu contexto original.
Nota sobre a fonte
Este artigo é baseado na atualização semanal do BAAI Hub / HyperAI publicada em A página original informa que a fonte do artigo é o WeChat e que as imagens podem ser removidas caso haja preocupações com direitos autorais.
QR codes, pôsteres promocionais, imagens de convite para grupos e banners de recomendações não relacionados foram removidos intencionalmente. Os links das imagens de DiaMoE-TTS e DreamOmni2 foram mantidos em suas posições originais, mas as solicitações de pré-visualização expiraram durante a verificação; por isso, eles são mencionados aqui em vez de serem tratados como capturas de tela totalmente verificadas.
Visão geral da atualização semanal da HyperAI
De 27 de junho a 3 de julho, a HyperAI atualizou vários recursos públicos em seu site oficial:
- 12 tutoriais públicos selecionados
- 5 verbetes populares da enciclopédia de IA
- 4 prazos de conferências de IA em julho
O tema principal desta semana é a experimentação prática. A maioria das entradas não se limita à descrição de artigos científicos; elas oferecem demos online ou notebooks executáveis para que os usuários possam testar rapidamente o comportamento dos modelos.
Tutoriais públicos selecionados
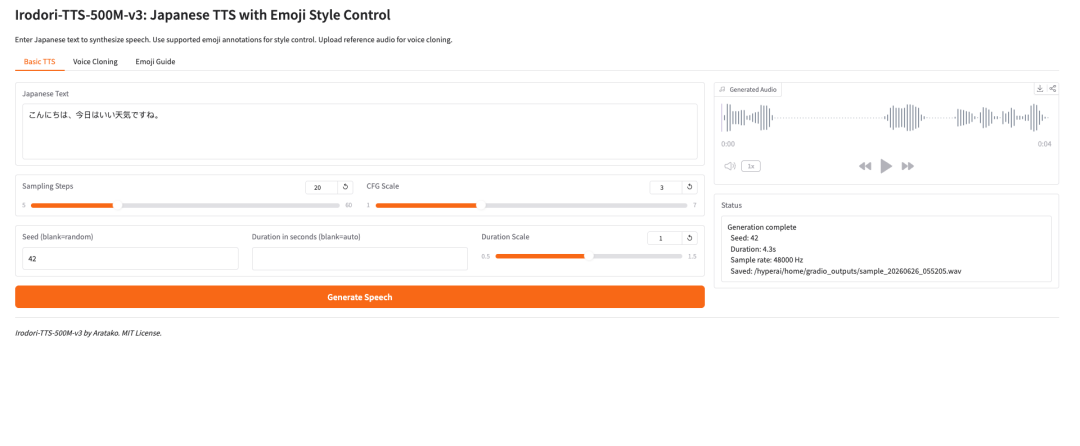
1. Irodori-TTS-500M-v3: TTS em japonês com controle de estilo por emoji
O Irodori-TTS é um projeto open-source japonês de texto para fala lançado pelo desenvolvedor Aratako em 2026. O modelo em destaque, Irodori-TTS-500M-v3, foi desenvolvido para síntese de fala em japonês, clonagem de voz zero-shot e controle de estilo vocal guiado por emojis.
O modelo é construído em torno de uma arquitetura Rectified Flow Diffusion Transformer (RF-DiT) e gera fala em um espaço latente contínuo DACVAE. No uso prático, o ponto mais interessante é que ele consegue clonar uma voz-alvo a partir de apenas um pequeno clipe de referência, geralmente de cerca de 3 a 10 segundos, sem ajuste fino adicional.
Ele também oferece suporte a controle de estilo por meio de anotações com emojis. Isso torna o modelo mais flexível do que um sistema TTS básico: os usuários podem orientar tom, emoção, ritmo e expressões não verbais sutis de uma forma mais leve.
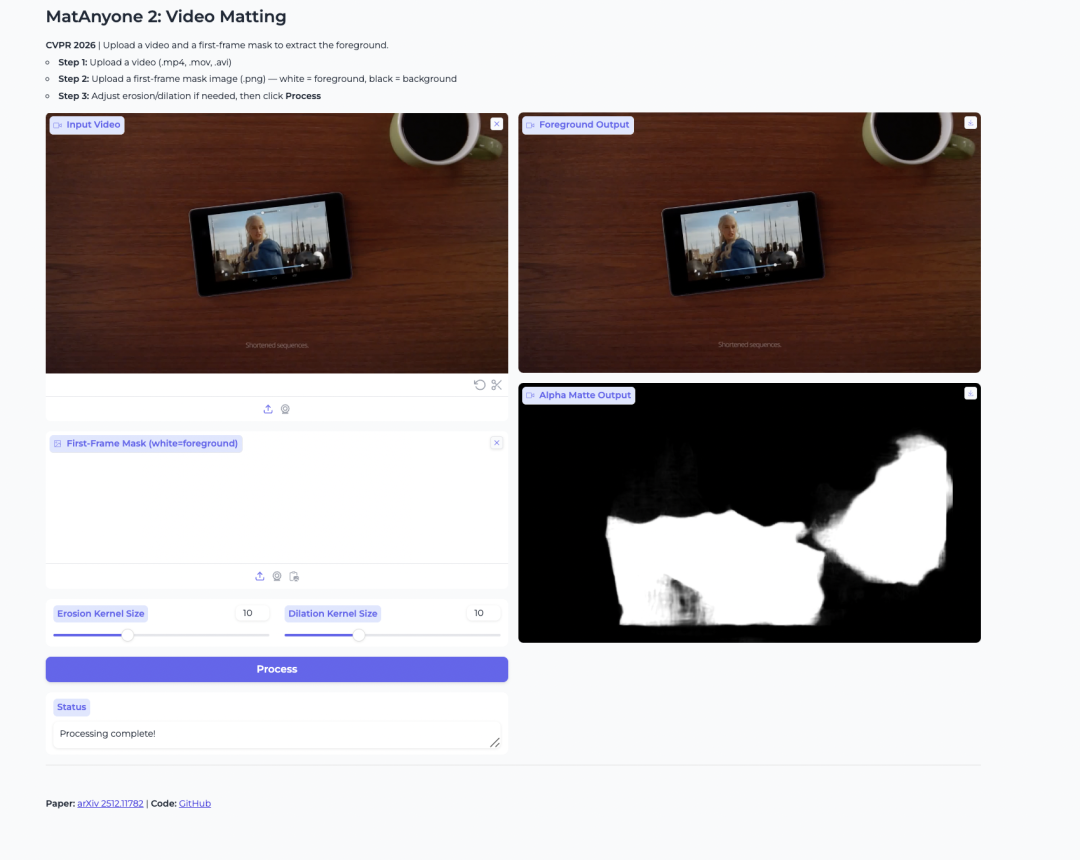
2. MatAnyone 2: matting de vídeo para extração de primeiro plano
MatAnyone 2 é um modelo de matting de vídeo lançado pelo NTU S-Lab e pela SenseTime. Ele foi criado para extrair primeiros planos humanos e gerar alpha mattes a partir de vídeos.
O modelo melhora a estabilidade usando um avaliador de qualidade aprendido. Isso ajuda a reduzir artefatos de borda e a preservar detalhes como cabelo, bordas semitransparentes e contornos do primeiro plano. Ele também é útil quando o usuário deseja isolar uma pessoa específica em um vídeo com várias pessoas.
Demo online:
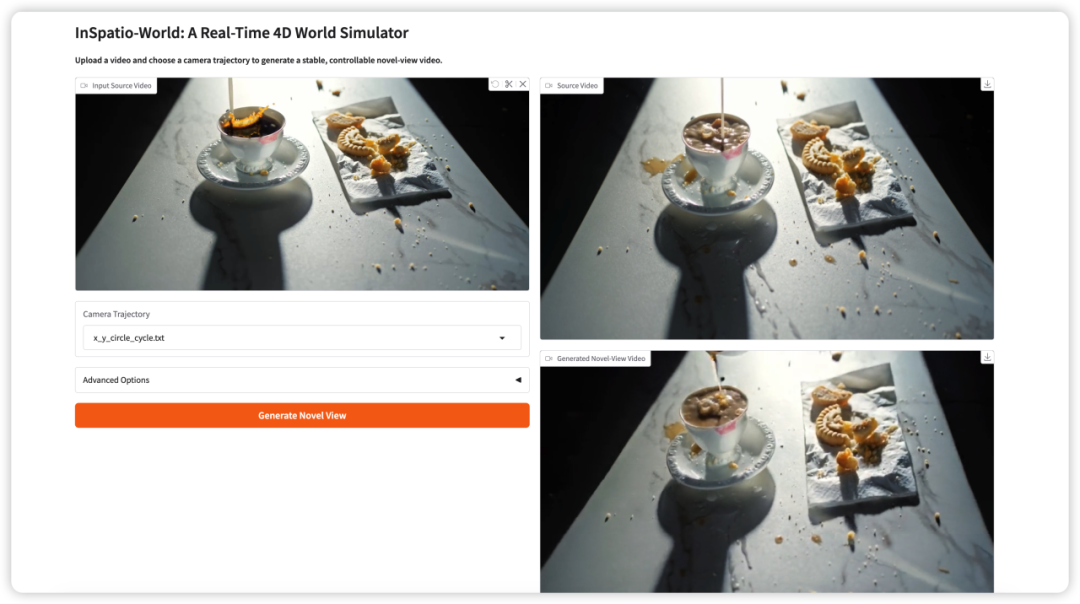
3. InSpatio-World: simulação de mundo 4D em tempo real
InSpatio-World é um simulador de mundo 4D em tempo real lançado pela equipe InSpatio em 2026. Ele pode receber um vídeo de entrada e uma trajetória de câmera especificada e, em seguida, gerar um vídeo estável de uma nova perspectiva.
A ideia central é tornar as cenas de vídeo mais controláveis. Em vez de assistir passivamente a uma visão de câmera fixa, os usuários podem definir o movimento da câmera e explorar a cena a partir de novos pontos de vista, preservando a consistência temporal.
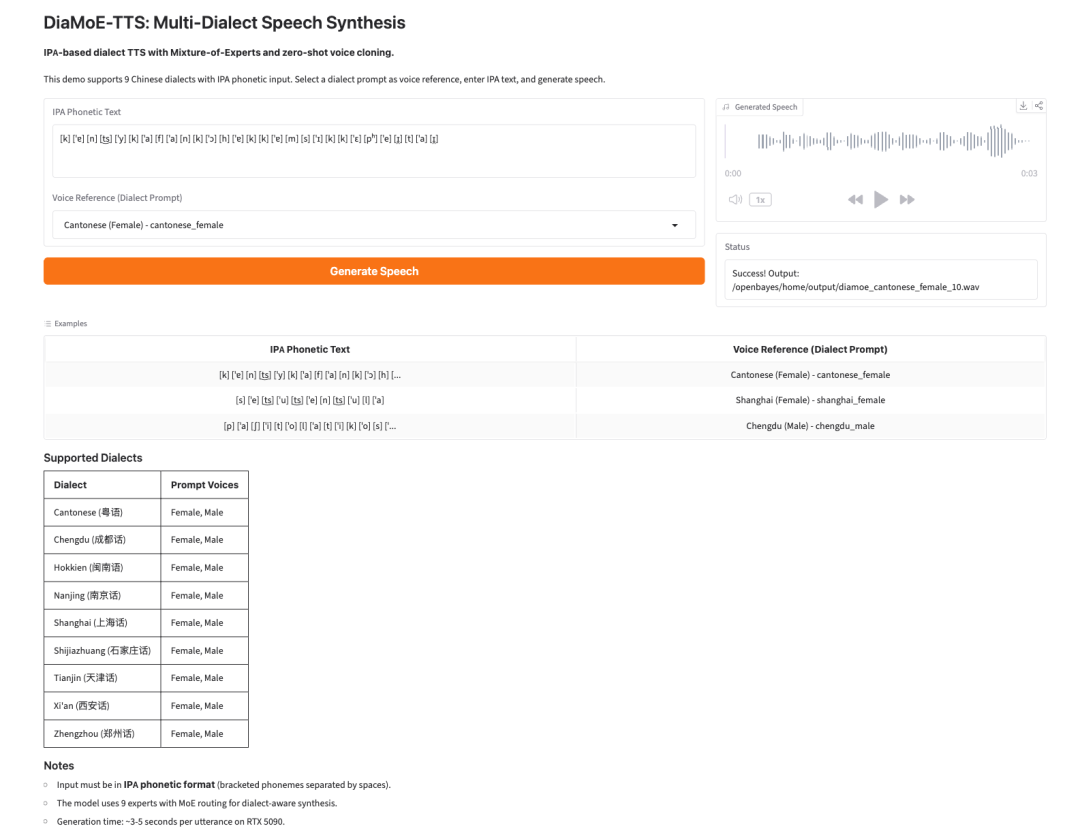
4. DiaMoE-TTS: síntese de fala multidialetal baseada em IPA
DiaMoE-TTS é uma estrutura de síntese de fala multidialetal do Giant AI Lab. Ela usa o Alfabeto Fonético Internacional, ou IPA, como frontend unificado para geração de fala em dialetos.
O modelo combina um design Mixture-of-Experts com métodos de adaptação eficientes em parâmetros, como LoRA e adaptadores de condicionamento. Isso permite que o sistema se adapte mais rapidamente a novos dialetos, mesmo quando há apenas dados limitados disponíveis.
{kind=link}
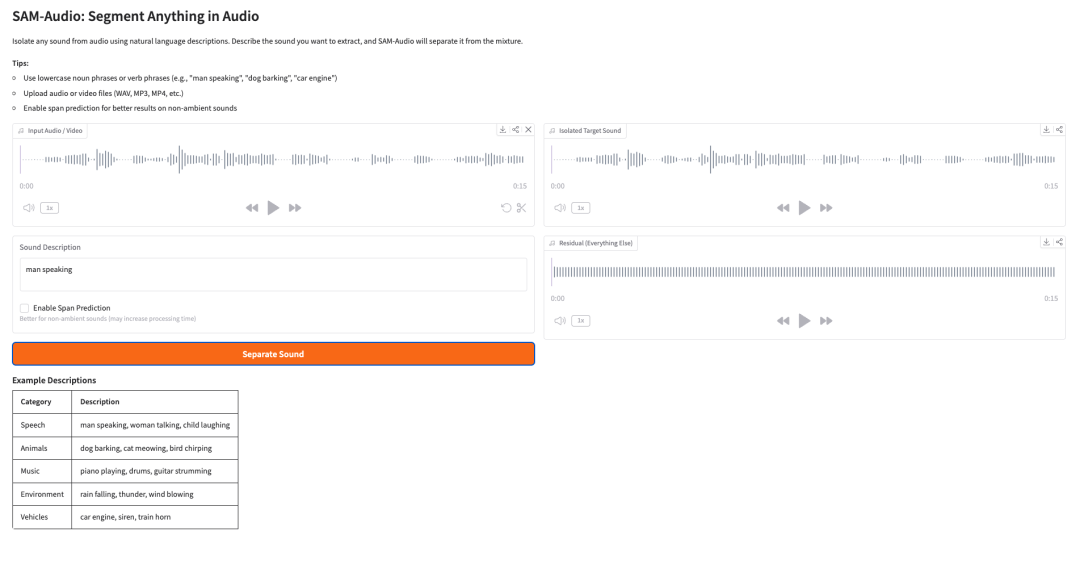
5. SAM-Audio: Segment Anything em Áudio
SAM-Audio é o modelo fundamental de separação de fontes de áudio da Meta. Ele consegue isolar um som-alvo de um sinal de áudio misto usando descrições em linguagem natural, pistas visuais de vídeo ou um intervalo de tempo selecionado.
Por exemplo, um usuário pode descrever o som que deseja separar, como “homem falando”, “cachorro latindo”, “motor de carro” ou “piano tocando”. Em seguida, o modelo tenta separar o áudio-alvo de todos os outros sons presentes na mistura.
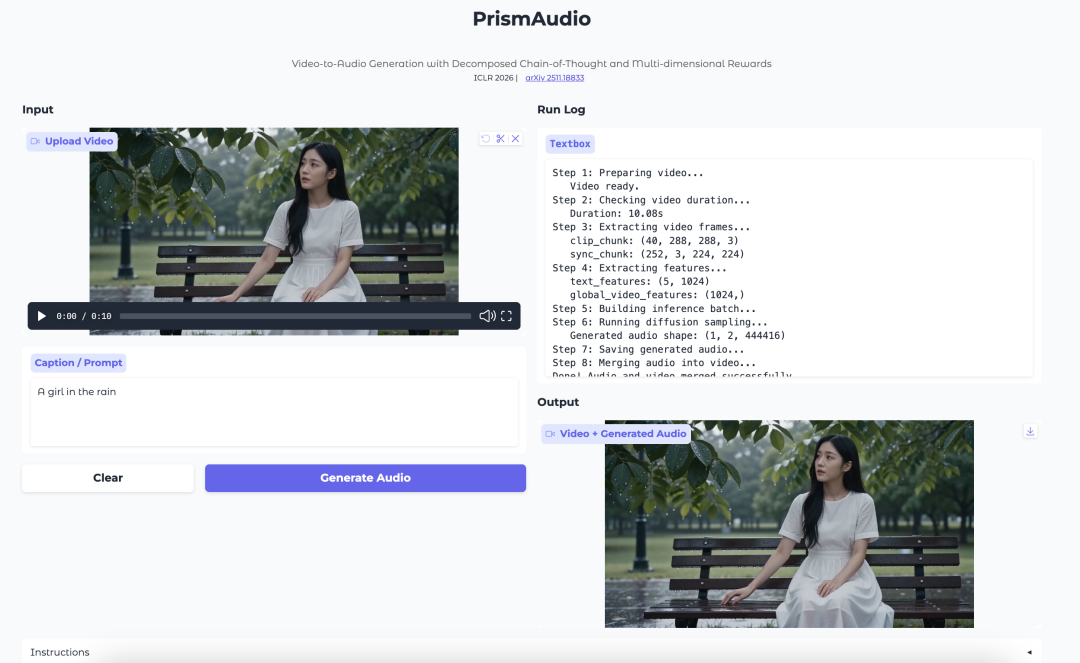
6. PrismAudio: Geração de Vídeo para Áudio com CoT Decomposto e Recompensas Multidimensionais
PrismAudio é um modelo de geração de vídeo para áudio do Tongyi Lab. Ele se concentra em gerar áudio que corresponda à cena visual, ao tempo, à atmosfera e à sensação espacial de um vídeo.
O modelo introduz um processo de planejamento de Chain-of-Thought decomposto. Em vez de tratar a geração de vídeo para áudio como uma única etapa de raciocínio, ele separa o processo em dimensões semântica, temporal, estética e espacial. Cada dimensão é associada a um sinal de recompensa específico para aprendizagem por reforço.
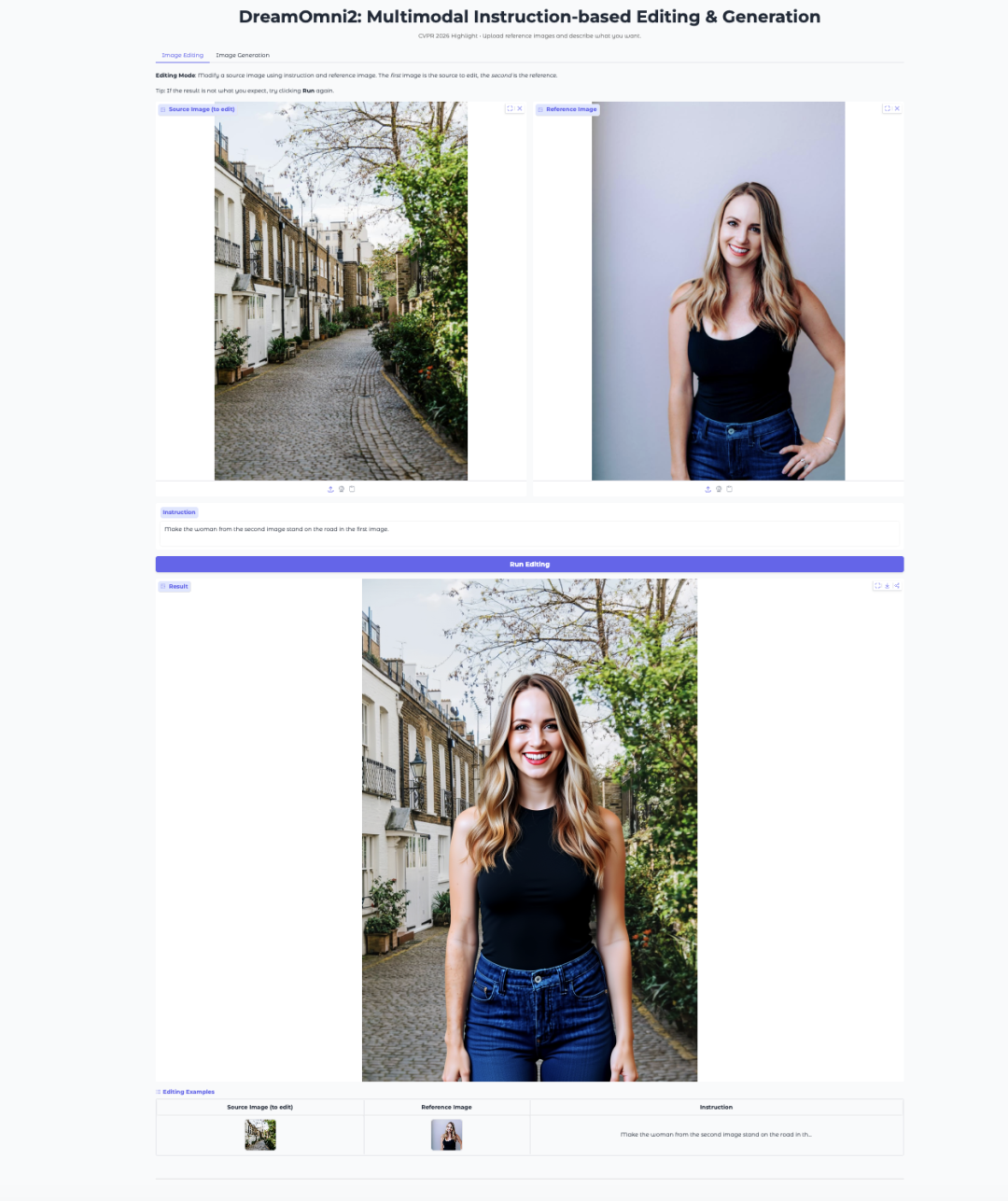
7. DreamOmni2: Edição e Geração de Imagens Multimodais Baseadas em Instruções
DreamOmni2 é um modelo multimodal de edição e geração de imagens do CUHK JIA Lab. Ele foi aceito pela CVPR 2026 como artigo Highlight.
O modelo é construído sobre o FLUX.1-Kontext-dev e usa um modelo de linguagem visual Qwen2.5-VL-7B ajustado para lidar com instruções. Ele oferece suporte a prompts em linguagem natural junto com imagens de referência, o que o torna adequado para tarefas como substituição de objetos, transferência de estilo, imitação de pose e geração orientada por conceitos.
8. PixelRefer: Compreensão Granular de Objetos em Imagens e Vídeos
PixelRefer é uma estrutura unificada de compreensão de objetos em imagens e vídeos da Alibaba DAMO Academy. Ela se concentra na compreensão detalhada centrada em objetos, em vez de apenas descrever uma cena inteira.
A estrutura oferece suporte a apontamento em nível de região, geração de legendas e resposta a perguntas. Ela também introduz um tokenizador de objetos adaptativo à escala e uma variante mais leve, PixelRefer-Lite, para tornar a representação de objetos mais compacta e eficiente.

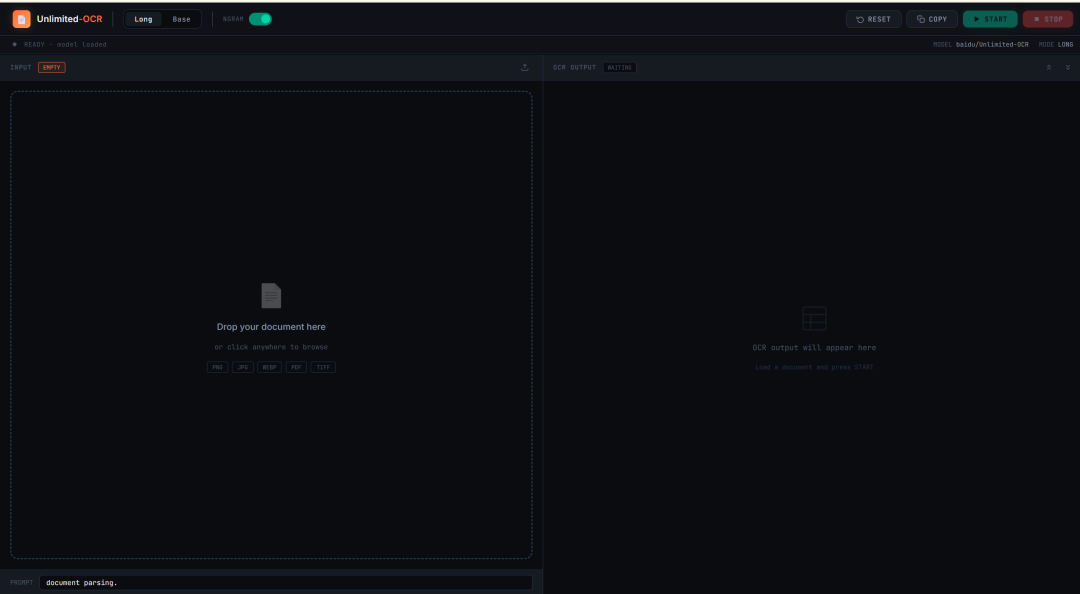
9. Unlimited-OCR: OCR de Documentos Longos em Uma Única Etapa e Análise de Layout
Unlimited-OCR é um projeto de OCR e análise de layout de documentos lançado pela Baidu em 2026. Ele foi projetado para a análise de documentos longos, e não apenas para o reconhecimento de páginas individuais.
O projeto pode processar imagens de documentos individuais, imagens multipágina e páginas convertidas de PDFs. Ele é especialmente útil para artigos, relatórios, documentos digitalizados, tabelas longas e materiais estruturados com múltiplas páginas.
10. EdgeTAM: Segmentação de Imagens e Vídeos com Prompts para Dispositivos de Borda
EdgeTAM é um Track Anything Model executado no dispositivo, desenvolvido pela Meta Reality Labs e pelo NTU S-Lab. Ele foi projetado para dispositivos com recursos limitados, mantendo a capacidade de segmentação interativa de modelos no estilo SAM.
O modelo reduz o gargalo de atenção de memória do SAM 2 por meio de um 2D Spatial Perceiver e de um pipeline de destilação. Na prática, isso significa que ele pode oferecer suporte a segmentação orientada por prompts
segmentação e rastreamento de objetos em vídeo de forma mais eficiente em hardware de borda.

11. Step-Audio-EditX: Clonagem de voz zero-shot e edição expressiva de áudio
Step-Audio-EditX é um modelo de edição de áudio da StepFun. Ele combina um modelo de áudio baseado em LLM com 3 bilhões de parâmetros e aprendizagem por reforço para oferecer suporte à clonagem de voz zero-shot e à edição expressiva de áudio.
O modelo pode lidar com mandarim, inglês, sichuanês, cantonês, japonês e coreano. Ele foi criado para tarefas como controle de emoção, edição de estilo de fala, edição paralinguística e refinamento iterativo de áudio.

12. Nemotron 3.5 ASR Streaming 0.6B: Reconhecimento de fala em streaming leve
Nemotron 3.5 ASR Streaming 0.6B é um modelo de reconhecimento automático de fala da NVIDIA. Ele foi criado para transcrição em streaming de baixa latência e usa uma arquitetura FastConformer-RNNT ciente de cache.
O principal design é o reúso de contexto. Durante a inferência em streaming, o modelo reutiliza o contexto do codificador em vez de recalcular trechos de áudio sobrepostos, o que ajuda a reduzir cálculos redundantes e a melhorar o desempenho em tempo real.
Entradas populares da enciclopédia
A HyperAI também destacou cinco entradas populares da enciclopédia de IA nesta semana:
- Modelo de Linguagem de Grande Porte (LLM)
- Modelo de Ação Mundial (WAM)
- Média Harmônica
- Triagem Virtual
- Aprendizagem por Reforço a partir de Feedback de IA (RLAIF)
A wiki da HyperAI reúne centenas de conceitos e explicações relacionados à IA. Ela é útil para leitores que desejam uma forma rápida de entender termos que aparecem com frequência em artigos, tutoriais e documentações de modelos.
Prazos de conferências de IA em julho
A atualização original também lista vários prazos de conferências de IA e ciência da computação em julho. Todos os horários dos prazos estão marcados como horário AoE.
| Data | Hora | Conferência |
|---|---|---|
| 09 de julho | 23:59:59 | POPL 2027 |
| 10 de julho | 23:59:59 | ICSE 2027 |
| 17 de julho | 23:59:59 | SIGMOD 2027 |
| 28 de julho | 23:59:59 | AAAI 2027 |
Sobre a HyperAI
A HyperAI é uma comunidade de inteligência artificial e computação de alto desempenho. Seu site oferece recursos públicos para desenvolvedores, pesquisadores e estudantes de IA.
Segundo a fonte original, a HyperAI já coletou ou oferece suporte a:
- Mais de 2.100 conjuntos de dados públicos com nós de aceleração domésticos
- Mais de 700 tutoriais online clássicos e populares
- Mais de 300 estudos de caso de artigos sobre AI4Science
- Mais de 700 entradas de enciclopédia relacionadas à IA
- Um espelho completo da documentação chinesa do Apache TVM
FAQ
O que é o Irodori-TTS-500M-v3?
Irodori-TTS-500M-v3 é um modelo aberto japonês de texto para fala baseado em uma arquitetura RF-DiT. Ele oferece suporte à geração de fala em japonês, clonagem de voz zero-shot com uma referência curta e controle de estilo baseado em emojis.
O Irodori-TTS consegue clonar uma voz sem ajuste fino?
Sim. A atualização original descreve o Irodori-TTS como compatível com clonagem de voz zero-shot a partir de um curto clipe de áudio de referência, geralmente com cerca de 3 a 10 segundos. O efeito ainda depende da qualidade e da clareza do áudio de referência.
Para que o SAM-Audio é usado?
O SAM-Audio é usado para separação de fontes de áudio baseada em prompts. Os usuários podem descrever o som que desejam extrair, fornecer pistas visuais ou especificar um intervalo de tempo para isolar um som-alvo de uma gravação mista.
Qual é a diferença entre matting de vídeo e segmentação de vídeo?
A segmentação de vídeo geralmente separa objetos em regiões ou máscaras, enquanto o matting de vídeo estima uma máscara alfa mais detalhada. O matting é especialmente importante para extração limpa do primeiro plano, detalhes de cabelo, bordas semitransparentes e composição.
O que o PrismAudio gera?
O PrismAudio gera áudio para vídeo. Ele tenta alinhar o som gerado com o conteúdo semântico, o tempo, a sensação estética e as pistas espaciais do vídeo.
Por que o Unlimited-OCR é útil para documentos longos?
O Unlimited-OCR foi projetado para análise de longo horizonte, não apenas para OCR isolado de páginas únicas. Ele pode ser útil ao lidar com artigos, relatórios, arquivos digitalizados, tabelas longas ou imagens derivadas de PDFs com várias páginas.
O Nemotron 3.5 ASR Streaming 0.6B é adequado para transcrição de fala em tempo real?
Sim, ele foi projetado para baixa latência
ASR em streaming. Sua arquitetura FastConformer-RNNT com consciência de cache reutiliza o contexto durante a inferência em streaming, o que ajuda a reduzir computações redundantes.
Ferramentas relacionadas
- Irodori-TTS: TTS japonês de código aberto com clonagem de voz por áudio de referência e controle de estilo.
- Irodori-TTS-500M-v3 no Hugging Face: Página do modelo para o checkpoint de TTS japonês 500M v3.
- SAM-Audio: Repositório da Meta para inferência e exemplos do Segment Anything in Audio.
- MatAnyone 2: Página do projeto do framework de matting de vídeo MatAnyone 2.
- InSpatio-World: Página do projeto para simulação interativa em tempo real de mundos 4D.
- DiaMoE-TTS: Repositório no GitHub para síntese de fala multidialetal baseada em IPA.
- PrismAudio: Página do projeto para geração de áudio a partir de vídeo com CoT decomposto e recompensas multidimensionais.
- DreamOmni2: Projeto multimodal de código aberto para edição e geração de imagens baseada em instruções.
- PixelRefer: Framework da Alibaba DAMO Academy para compreensão refinada de objetos em imagens e vídeos.
- Unlimited-OCR: Projeto da Baidu para OCR de longo horizonte e análise de documentos.
- EdgeTAM: Modelo da Meta executado no dispositivo para rastrear qualquer coisa, com segmentação de imagens e vídeos orientada por prompts.
- Step-Audio-EditX: Modelo da StepFun para clonagem de voz zero-shot e edição expressiva de áudio.
- Nemotron 3.5 ASR Streaming 0.6B: Página do modelo da NVIDIA no Hugging Face para ASR em streaming de baixa latência.
Links relacionados
- Artigo original no BAAI Hub: Artigo-fonte desta atualização semanal da HyperAI.
- Site oficial da HyperAI: Portal principal para tutoriais, artigos, conjuntos de dados e recursos de IA da HyperAI.
- HyperAI Wiki: Portal de enciclopédia de IA que cobre conceitos comuns e termos de pesquisa.
- HyperAI Conference Tracker: Rastreador de prazos de conferências de IA e ciência da computação.
- Página de pesquisa do Meta SAM-Audio: Página oficial de pesquisa do Segment Anything Model Audio.
- Artigo do SAM-Audio no arXiv: Artigo de pesquisa que descreve o modelo de base SAM-Audio.
- Artigo do MatAnyone 2 no arXiv: Artigo sobre o MatAnyone 2 e seu avaliador aprendido de qualidade de matting.
- Artigo do Unlimited-OCR no arXiv: Relatório técnico sobre o Unlimited OCR e análise de longo horizonte.
Resumo
Esta atualização semanal reúne um conjunto útil de novas demos de IA e recursos de modelos, especialmente nas áreas de geração de áudio, reconhecimento de fala, processamento de vídeo, compreensão de imagens e OCR de documentos longos.
As entradas mais práticas são o Irodori-TTS para geração de voz em japonês, o SAM-Audio para separação de som baseada em prompts, o MatAnyone 2 para matting de vídeo limpo, o Unlimited-OCR para documentos longos e o Nemotron 3.5 ASR para reconhecimento de fala em streaming.
No geral, este resumo é útil para leitores que desejam descobrir rapidamente quais novos modelos de IA valem a pena testar, o que cada um faz e onde experimentá-los.