HyperAI Wöchentliches KI-Modell-Update: Irodori-TTS, SAM-Audio, MatAnyone 2, PrismAudio und mehr
Dieses wöchentliche Update bündelt eine nützliche Auswahl neuer KI-Demos und Modellressourcen, insbesondere in den Bereichen Audiogenerierung, Spracherkennung, Videoverarbeitung, Bildverständnis und OCR für lange Dokumente. Zu den praktischsten Einträgen zählen Irodori-TTS für japanische Sprachgenerierung, SAM-Audio für promptbasierte Klangtrennung, MatAnyone 2 für sauberes Video-Matting, Unlimited-OCR für lange Dokumente und Nemotron 3.5 ASR für Streaming-Spracherkennung. **Insgesamt ist diese Zusammenstellung hilfreich für Leser, die schnell herausfinden möchten, welche neuen KI-Modelle einen Test wert sind, was jedes einzelne leistet und wo man sie ausprobieren kann.**

HyperAI Wöchentliches KI-Modell-Update: Irodori-TTS, SAM-Audio, MatAnyone 2, PrismAudio und mehr
Einführung
Das HyperAI-Update dieser Woche konzentriert sich auf eine starke Mischung aus Modellen für Audio, Video, Bildverständnis, OCR und Spracherkennung. Das Hauptprojekt ist Irodori-TTS-500M-v3, ein offenes japanisches Text-to-Speech-Modell, das hochwertige Sprachgenerierung mit 48 kHz, Zero-Shot-Stimmklonung und fein abgestimmte Stilsteuerung über Emoji-Annotationen kombiniert.
Das Update umfasst außerdem Werkzeuge für promptbasierte Audiotrennung, Video-Matting, 4D-Weltsimulation, Video-zu-Audio-Generierung, Dokumenten-OCR, On-Device-Segmentierung, expressive Audiobearbeitung und latenzarme Streaming-ASR. Unten finden Sie eine bereinigte, publikationsreife Version der ursprünglichen wöchentlichen Zusammenfassung, wobei die nützlichen Screenshots in ihrem ursprünglichen Kontext erhalten bleiben.
Quellenhinweis
Dieser Artikel basiert auf dem wöchentlichen Update von BAAI Hub / HyperAI, das veröffentlicht wurde unter Auf der Originalseite heißt es, dass die Artikelquelle WeChat ist und dass Bilder bei urheberrechtlichen Bedenken entfernt werden können.
QR-Codes, Werbeplakate, Gruppeneinladungsbilder und nicht verwandte Empfehlungsbanner wurden bewusst entfernt. Die Bildlinks zu DiaMoE-TTS und DreamOmni2 bleiben an ihren ursprünglichen Positionen erhalten, aber ihre Vorschauanfragen liefen während der Überprüfung in ein Timeout. Daher werden sie hier erwähnt, anstatt als vollständig verifizierte Screenshots behandelt zu werden.
Überblick über das wöchentliche HyperAI-Update
Vom 27. Juni bis 3. Juli aktualisierte HyperAI mehrere öffentliche Ressourcen auf seiner offiziellen Website:
- 12 ausgewählte öffentliche Tutorials
- 5 beliebte Einträge aus der KI-Enzyklopädie
- 4 Fristen für KI-Konferenzen im Juli
Das Hauptthema dieser Woche ist praktisches Experimentieren. Die meisten Einträge sind nicht nur Beschreibungen von Papers; sie stellen Online-Demos oder ausführbare Notebooks bereit, sodass Nutzer das Modellverhalten schnell testen können.
Ausgewählte öffentliche Tutorials
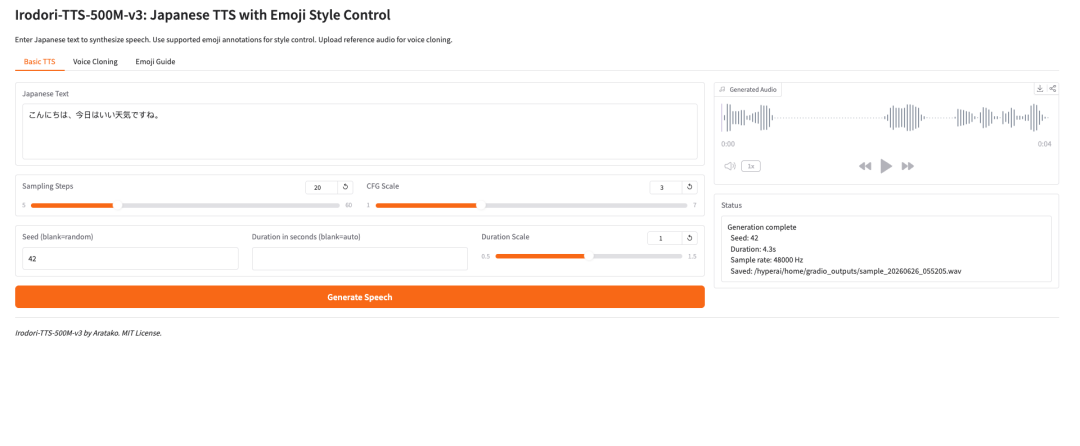
1. Irodori-TTS-500M-v3: Japanisches TTS mit Emoji-Stilsteuerung
Irodori-TTS ist ein Open-Source-Projekt für japanische Text-to-Speech-Synthese, das 2026 vom Entwickler Aratako veröffentlicht wurde. Das vorgestellte Modell, Irodori-TTS-500M-v3, ist für japanische Sprachsynthese, Zero-Shot-Stimmklonung und emoji-gesteuerte Stimmstilkontrolle konzipiert.
Das Modell basiert auf einer Rectified Flow Diffusion Transformer (RF-DiT)-Architektur und erzeugt Sprache in einem kontinuierlichen DACVAE-Latentraum. In der praktischen Nutzung ist der interessanteste Punkt, dass es eine Zielstimme aus nur einem kurzen Referenzclip klonen kann, üblicherweise etwa 3 bis 10 Sekunden, ohne zusätzliches Fine-Tuning.
Außerdem unterstützt es Stilsteuerung durch Emoji-Annotationen. Dadurch ist das Modell flexibler als ein einfaches TTS-System: Nutzer können Tonfall, Emotion, Sprechtempo und subtile nonverbale Ausdrucksweisen auf eine leichtere Weise steuern.
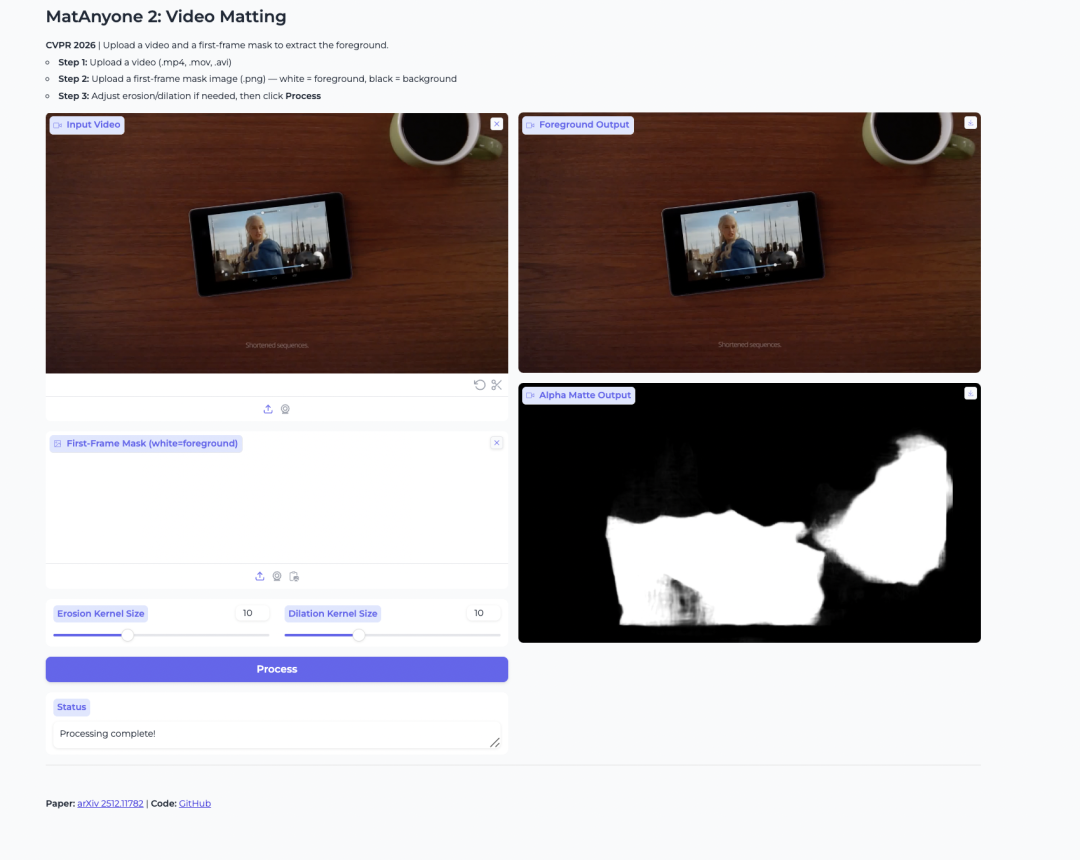
2. MatAnyone 2: Video-Matting zur Vordergrundextraktion
MatAnyone 2 ist ein Video-Matting-Modell, das von NTU S-Lab und SenseTime veröffentlicht wurde. Es wurde entwickelt, um menschliche Vordergründe zu extrahieren und Alpha-Mattes aus Videos zu erzeugen.
Das Modell verbessert die Stabilität durch einen gelernten Qualitätsbewerter. Dies hilft dabei, Randartefakte zu reduzieren und Details wie Haare, halbtransparente Kanten und Vordergrundkonturen zu erhalten. Es ist außerdem nützlich, wenn der Nutzer eine bestimmte Person in einem Video mit mehreren Personen isolieren möchte.
Online-Demo:
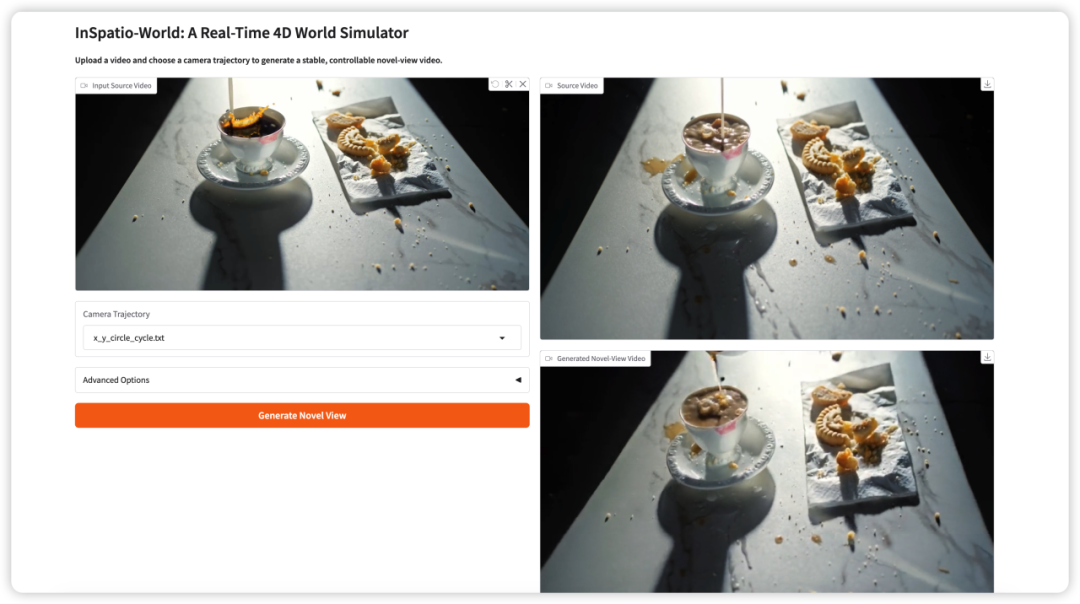
3. InSpatio-World: Echtzeit-4D-Weltsimulation
InSpatio-World ist ein Echtzeit-4D-Weltsimulator, der 2026 vom InSpatio-Team veröffentlicht wurde. Er kann ein Eingabevideo und eine festgelegte Kameratrajektorie verwenden und daraus ein stabiles Video aus einer neuen Perspektive erzeugen.
Die Kernidee besteht darin, Videoszenen besser steuerbar zu machen. Anstatt passiv eine feste Kameraperspektive zu betrachten, können Nutzer Kamerabewegungen definieren und die Szene aus neuen Blickwinkeln erkunden, während die zeitliche Konsistenz erhalten bleibt.
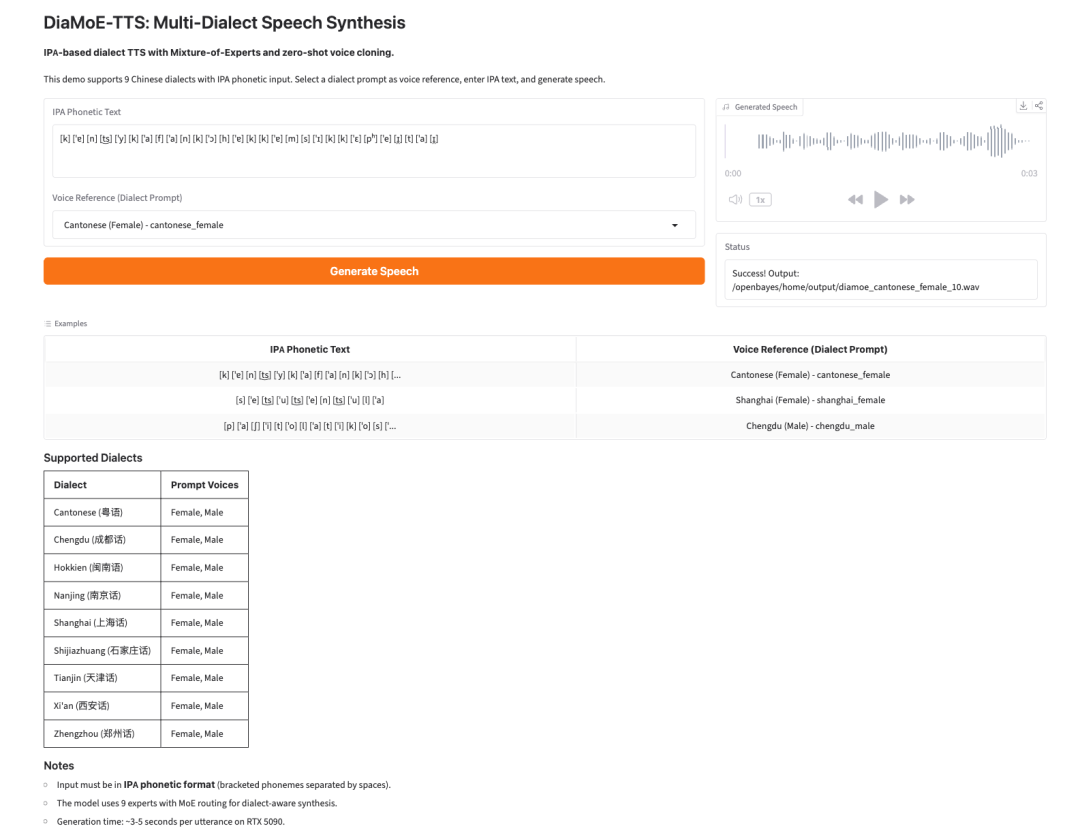
4. DiaMoE-TTS: IPA-basierte multidialektale Sprachsynthese
DiaMoE-TTS ist ein Framework für multidialektale Sprachsynthese von Giant AI Lab. Es verwendet das Internationale Phonetische Alphabet, kurz IPA, als einheitliches Frontend für die Erzeugung von Dialektsprache.
Das Modell kombiniert ein Mixture-of-Experts-Design mit parametereffizienten Anpassungsmethoden wie LoRA und Conditioning-Adaptern. Dadurch kann sich das System schneller an neue Dialekte anpassen, selbst wenn nur begrenzte Daten verfügbar sind.
{kind=link}
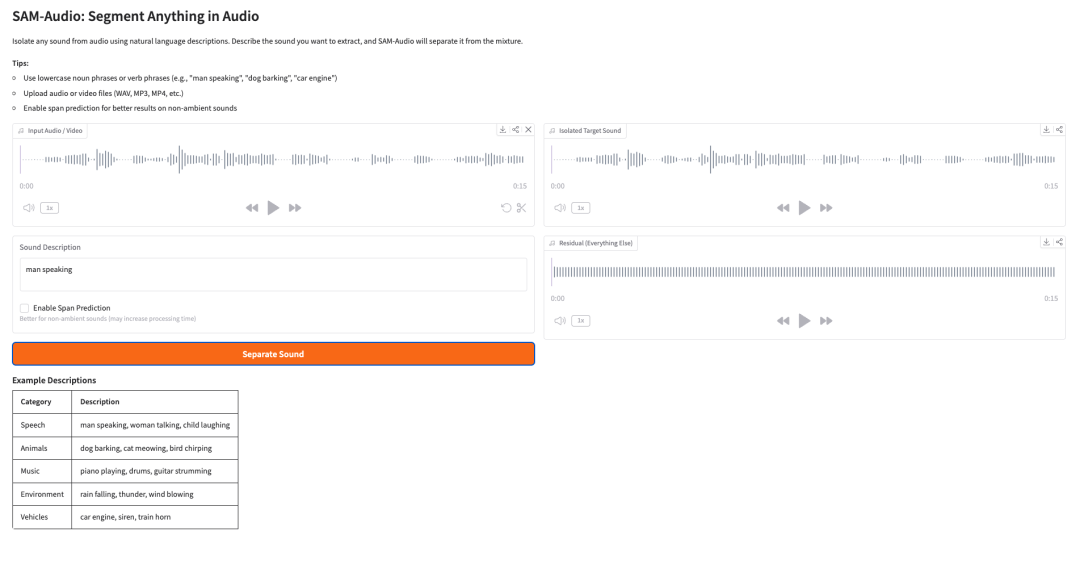
5. SAM-Audio: Segment Anything in Audio
SAM-Audio ist Metas Foundation-Modell zur Trennung von Audioquellen. Es kann einen Zielklang aus einem gemischten Audiosignal isolieren, indem es natürliche Sprachbeschreibungen, visuelle Hinweise aus Videos oder einen ausgewählten Zeitabschnitt nutzt.
Beispielsweise kann ein Nutzer den Klang beschreiben, den er trennen möchte, etwa „man speaking“, „dog barking“, „car engine“ oder „piano playing“. Das Modell versucht anschließend, das Zielaudio von allem anderen in der Mischung zu trennen.
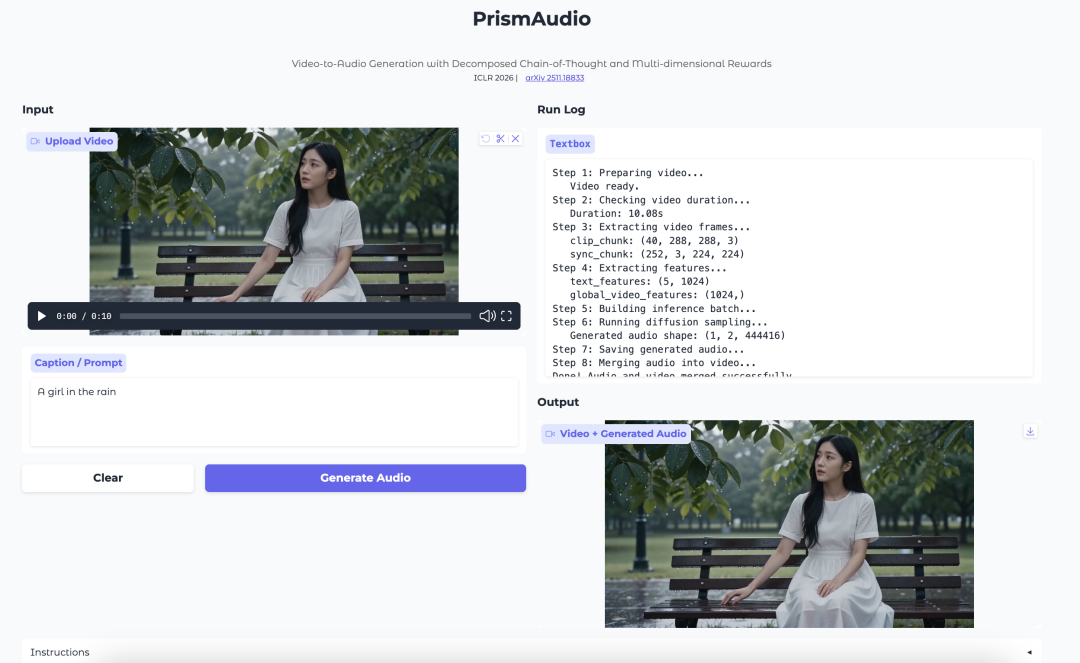
6. PrismAudio: Video-zu-Audio-Generierung mit zerlegter CoT und mehrdimensionalen Belohnungen
PrismAudio ist ein Video-zu-Audio-Generierungsmodell von Tongyi Lab. Es konzentriert sich darauf, Audio zu erzeugen, das zur visuellen Szene, zum Timing, zur Atmosphäre und zum räumlichen Eindruck eines Videos passt.
Das Modell führt einen zerlegten Chain-of-Thought-Planungsprozess ein. Statt die Video-zu-Audio-Generierung als einen einzigen Schlussfolgerungsschritt zu behandeln, unterteilt es den Prozess in semantische, zeitliche, ästhetische und räumliche Dimensionen. Jede Dimension wird mit einem gezielten Belohnungssignal für Reinforcement Learning gekoppelt.
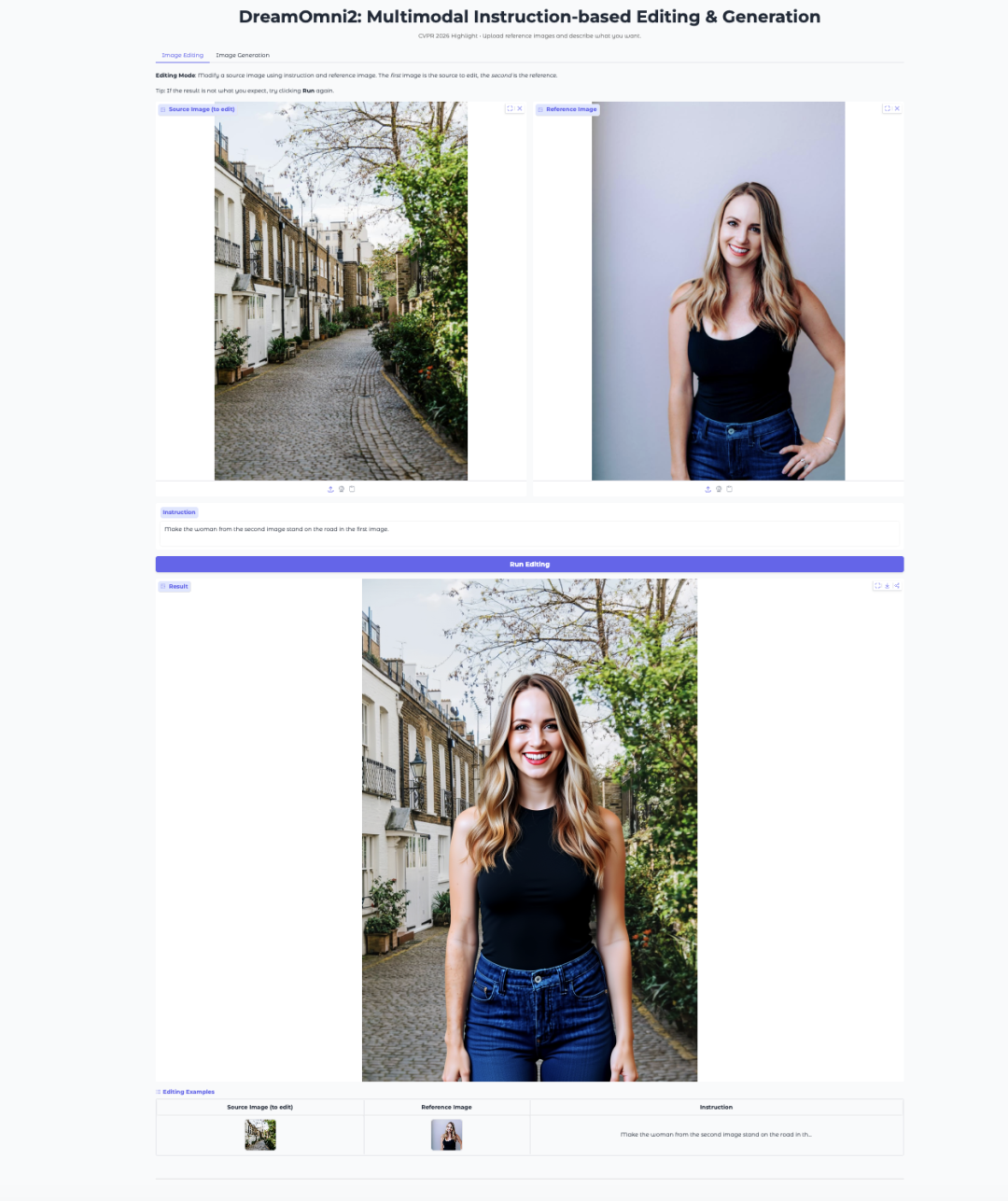
7. DreamOmni2: Multimodale instruktionsbasierte Bildbearbeitung und -generierung
DreamOmni2 ist ein multimodales Modell zur Bildbearbeitung und -generierung aus dem CUHK JIA Lab. Es wurde von der CVPR 2026 als Highlight-Paper angenommen.
Das Modell basiert auf FLUX.1-Kontext-dev und verwendet ein feinabgestimmtes visuelles Sprachmodell Qwen2.5-VL-7B zur Verarbeitung von Anweisungen. Es unterstützt natürlichsprachliche Prompts zusammen mit Referenzbildern und eignet sich damit für Aufgaben wie Objektersetzung, Stiltransfer, Posenimitation und konzeptgesteuerte Generierung.
8. PixelRefer: Feingranulares Objektverständnis für Bilder und Videos
PixelRefer ist ein einheitliches Framework für das Objektverständnis in Bildern und Videos von Alibaba DAMO Academy. Es konzentriert sich auf feingranulares, objektzentriertes Verständnis, anstatt nur eine gesamte Szene zu beschreiben.
Das Framework unterstützt zeigebasierte Referenzierung auf Regionenebene, Bildbeschriftung und Fragebeantwortung. Außerdem führt es einen skalenadaptiven Objekt-Tokenizer sowie eine leichtere Variante namens PixelRefer-Lite ein, um Objektrepräsentationen kompakter und effizienter zu machen.

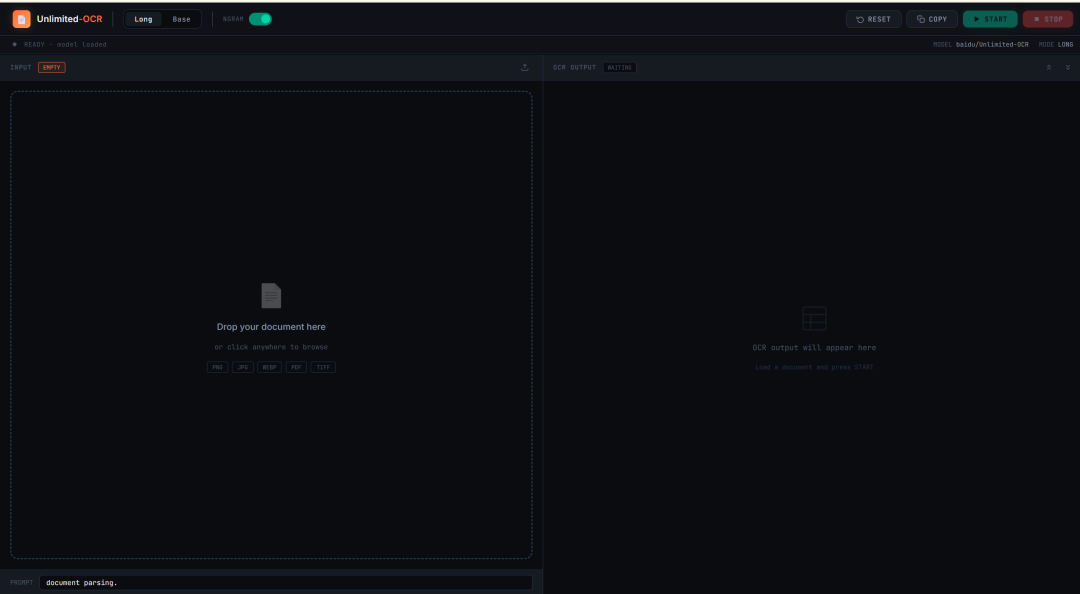
9. Unlimited-OCR: One-Shot-OCR für lange Dokumente und Layout-Parsing
Unlimited-OCR ist ein OCR- und Dokumentlayout-Parsing-Projekt, das 2026 von Baidu veröffentlicht wurde. Es ist auf das Parsen langer Dokumente ausgelegt und nicht nur auf die Erkennung einzelner Seiten.
Das Projekt kann einzelne Dokumentbilder, mehrseitige Bilder und aus PDFs konvertierte Seiten verarbeiten. Es ist besonders nützlich für wissenschaftliche Arbeiten, Berichte, gescannte Dokumente, lange Tabellen und mehrseitige strukturierte Materialien.
10. EdgeTAM: Promptbare Bild- und Videosegmentierung für Edge-Geräte
EdgeTAM ist ein On-Device-Track-Anything-Modell, das von Meta Reality Labs und NTU S-Lab entwickelt wurde. Es ist für ressourcenbeschränkte Geräte konzipiert und bewahrt gleichzeitig die interaktive Segmentierungsfähigkeit von SAM-ähnlichen Modellen.
Das Modell reduziert den Engpass der Memory Attention von SAM 2 durch einen 2D Spatial Perceiver und eine Distillationspipeline. In der Praxis bedeutet das, dass es promptbare
Segmentierung und Video-Objektverfolgung effizienter auf Edge-Hardware.

11. Step-Audio-EditX: Zero-Shot-Stimmklonen und expressive Audiobearbeitung
Step-Audio-EditX ist ein Audiobearbeitungsmodell von StepFun. Es kombiniert ein LLM-basiertes Audiomodell mit 3 Milliarden Parametern mit Reinforcement Learning, um Zero-Shot-Stimmklonen und expressive Audiobearbeitung zu unterstützen.
Das Modell kann Mandarin, Englisch, Sichuanesisch, Kantonesisch, Japanisch und Koreanisch verarbeiten. Es ist für Aufgaben wie Emotionssteuerung, Bearbeitung des Sprechstils, paralinguistische Bearbeitung und iterative Audioverfeinerung konzipiert.

12. Nemotron 3.5 ASR Streaming 0.6B: Leichte Streaming-Spracherkennung
Nemotron 3.5 ASR Streaming 0.6B ist ein Modell zur automatischen Spracherkennung von NVIDIA. Es wurde für latenzarme Streaming-Transkription entwickelt und nutzt eine cache-bewusste FastConformer-RNNT-Architektur.
Das zentrale Designprinzip ist die Wiederverwendung von Kontext. Während der Streaming-Inferenz verwendet das Modell Encoder-Kontext erneut, anstatt überlappende Audioabschnitte neu zu berechnen. Dadurch werden redundante Berechnungen reduziert und die Echtzeitleistung verbessert.
Beliebte Enzyklopädie-Einträge
HyperAI hob diese Woche außerdem fünf beliebte Einträge aus der KI-Enzyklopädie hervor:
- Large Language Model (LLM)
- World Action Model (WAM)
- Harmonisches Mittel
- Virtuelles Screening
- Reinforcement Learning from AI Feedback (RLAIF)
Das Wiki von HyperAI sammelt Hunderte von KI-bezogenen Konzepten und Erklärungen. Es ist nützlich für Leser, die eine schnelle Möglichkeit suchen, Begriffe zu verstehen, die häufig in wissenschaftlichen Arbeiten, Tutorials und Modelldokumentationen vorkommen.
Fristen für KI-Konferenzen im Juli
Das ursprüngliche Update listet außerdem mehrere Fristen für KI- und Informatikkonferenzen im Juli auf. Alle Fristzeiten sind als AoE-Zeit angegeben.
| Datum | Uhrzeit | Konferenz |
|---|---|---|
| 09. Juli | 23:59:59 | POPL 2027 |
| 10. Juli | 23:59:59 | ICSE 2027 |
| 17. Juli | 23:59:59 | SIGMOD 2027 |
| 28. Juli | 23:59:59 | AAAI 2027 |
Über HyperAI
HyperAI ist eine Community für künstliche Intelligenz und Hochleistungsrechnen. Die Website stellt öffentliche Ressourcen für Entwickler, Forschende und KI-Lernende bereit.
Laut der ursprünglichen Quelle hat HyperAI bereits Folgendes gesammelt oder unterstützt:
- Über 2.100 öffentliche Datensätze mit inländischen Beschleunigungsknoten
- Über 700 klassische und beliebte Online-Tutorials
- Über 300 Fallstudien zu AI4Science-Papern
- Über 700 KI-bezogene Enzyklopädie-Einträge
- Einen vollständigen chinesischen Dokumentationsspiegel für Apache TVM
FAQ
Was ist Irodori-TTS-500M-v3?
Irodori-TTS-500M-v3 ist ein offenes japanisches Text-to-Speech-Modell auf Basis einer RF-DiT-Architektur. Es unterstützt die Erzeugung japanischer Sprache, Zero-Shot-Stimmklonen mit kurzer Referenzaufnahme und stilistische Steuerung per Emoji.
Kann Irodori-TTS eine Stimme ohne Fine-Tuning klonen?
Ja. Im ursprünglichen Update wird beschrieben, dass Irodori-TTS Zero-Shot-Stimmklonen aus einem kurzen Referenz-Audioclip unterstützt, typischerweise mit einer Länge von etwa 3 bis 10 Sekunden. Das Ergebnis hängt jedoch weiterhin von der Qualität und Klarheit der Referenzaufnahme ab.
Wofür wird SAM-Audio verwendet?
SAM-Audio wird für promptbasierte Audiosignalquellentrennung verwendet. Nutzer können den Klang beschreiben, den sie extrahieren möchten, visuelle Hinweise bereitstellen oder einen Zeitbereich angeben, um einen Zielklang aus einer gemischten Aufnahme zu isolieren.
Was ist der Unterschied zwischen Video-Matting und Video-Segmentierung?
Video-Segmentierung trennt Objekte in der Regel in Regionen oder Masken, während Video-Matting eine detailliertere Alpha-Matte schätzt. Matting ist besonders wichtig für saubere Vordergrundextraktion, Haardetails, halbtransparente Kanten und Compositing.
Was erzeugt PrismAudio?
PrismAudio erzeugt Audio für Videos. Es versucht, den generierten Klang an den semantischen Inhalt, das Timing, die ästhetische Wirkung und die räumlichen Hinweise des Videos anzupassen.
Warum ist Unlimited-OCR für lange Dokumente nützlich?
Unlimited-OCR ist für langfristige Analyse ausgelegt, nicht nur für isolierte OCR einzelner Seiten. Es kann nützlich sein, wenn man mit wissenschaftlichen Arbeiten, Berichten, gescannten Dateien, langen Tabellen oder aus mehrseitigen PDFs abgeleiteten Bildern arbeitet.
Ist Nemotron 3.5 ASR Streaming 0.6B für Echtzeit-Sprachtranskription geeignet?
Ja, es ist für latenzarme
Streaming-ASR. Seine cache-bewusste FastConformer-RNNT-Architektur nutzt Kontext während der Streaming-Inferenz wieder, was dazu beiträgt, redundante Berechnungen zu reduzieren.
Verwandte Tools
- Irodori-TTS: Open-Source-TTS für Japanisch mit Stimmklonen anhand von Referenz-Audio und Stilsteuerung.
- Irodori-TTS-500M-v3 auf Hugging Face: Modellseite für den japanischen TTS-Checkpoint 500M v3.
- SAM-Audio: Metas Repository für Segment-Anything-in-Audio-Inferenz und Beispiele.
- MatAnyone 2: Projektseite für das Video-Matting-Framework MatAnyone 2.
- InSpatio-World: Projektseite für interaktive 4D-Weltsimulation in Echtzeit.
- DiaMoE-TTS: GitHub-Repository für IPA-basierte Sprachsynthese mit mehreren Dialekten.
- PrismAudio: Projektseite für Video-zu-Audio-Generierung mit zerlegter CoT und mehrdimensionalen Belohnungen.
- DreamOmni2: Open-Source-Projekt für multimodale, instruktionsbasierte Bildbearbeitung und -generierung.
- PixelRefer: Framework der Alibaba DAMO Academy für feingranulares Verständnis von Bild- und Videoobjekten.
- Unlimited-OCR: Baidus Projekt für OCR über lange Kontexte und Dokumentenparsing.
- EdgeTAM: Metas On-Device-Track-Anything-Modell für promptbare Bild- und Videosegmentierung.
- Step-Audio-EditX: StepFuns Modell für Zero-Shot-Stimmklonen und expressive Audiobearbeitung.
- Nemotron 3.5 ASR Streaming 0.6B: NVIDIAs Hugging-Face-Modellseite für latenzarme Streaming-ASR.
Verwandte Links
- Originalartikel im BAAI Hub: Quellartikel für dieses wöchentliche HyperAI-Update.
- Offizielle HyperAI-Website: Hauptportal für HyperAI-Tutorials, Paper, Datensätze und KI-Ressourcen.
- HyperAI Wiki: KI-Enzyklopädieportal zu gängigen Konzepten und Forschungsbegriffen.
- HyperAI Conference Tracker: Tracker für Einreichungsfristen von KI- und Informatikkonferenzen.
- Meta SAM-Audio Research Page: Offizielle Forschungsseite für Segment Anything Model Audio.
- SAM-Audio-Paper auf arXiv: Forschungspapier, das das SAM-Audio-Foundation-Modell beschreibt.
- MatAnyone 2 Paper auf arXiv: Paper zu MatAnyone 2 und seinem gelernten Qualitätsbewerter für Matting.
- Unlimited-OCR Paper auf arXiv: Technischer Bericht zu Unlimited OCR und Parsing über lange Kontexte.
Zusammenfassung
Dieses wöchentliche Update bündelt eine nützliche Auswahl neuer KI-Demos und Modellressourcen, insbesondere in den Bereichen Audiogenerierung, Spracherkennung, Videoverarbeitung, Bildverständnis und OCR für lange Dokumente.
Die praktischsten Einträge sind Irodori-TTS für japanische Sprachgenerierung, SAM-Audio für promptbasierte Klangtrennung, MatAnyone 2 für sauberes Video-Matting, Unlimited-OCR für lange Dokumente und Nemotron 3.5 ASR für Streaming-Spracherkennung.
Insgesamt ist diese Übersicht nützlich für Leser, die schnell herausfinden möchten, welche neuen KI-Modelle einen Test wert sind, was sie jeweils leisten und wo man sie ausprobieren kann.