Aggiornamento settimanale dei modelli AI di HyperAI: Irodori-TTS, SAM-Audio, MatAnyone 2, PrismAudio e altro
Questo aggiornamento settimanale riunisce una selezione utile di nuove demo di intelligenza artificiale e risorse di modelli, in particolare nei campi della generazione audio, del riconoscimento vocale, dell'elaborazione video, della comprensione delle immagini e dell'OCR per documenti lunghi. Le voci più pratiche sono Irodori-TTS per la generazione vocale in giapponese, SAM-Audio per la separazione dei suoni basata su prompt, MatAnyone 2 per un video matting pulito, Unlimited-OCR per documenti lunghi e Nemotron 3.5 ASR per il riconoscimento vocale in streaming. **Nel complesso, questa panoramica è utile per i lettori che vogliono scoprire rapidamente quali nuovi modelli AI vale la pena testare, cosa fa ciascuno di essi e dove provarli.**

Aggiornamento settimanale dei modelli AI di HyperAI: Irodori-TTS, SAM-Audio, MatAnyone 2, PrismAudio e altro
Introduzione
L’aggiornamento HyperAI di questa settimana si concentra su un solido mix di modelli per audio, video, comprensione delle immagini, OCR e riconoscimento vocale. Il progetto principale è Irodori-TTS-500M-v3, un modello aperto di sintesi vocale giapponese che combina generazione vocale ad alta fedeltà a 48 kHz, clonazione vocale zero-shot e controllo stilistico fine tramite annotazioni emoji.
L’aggiornamento include inoltre strumenti per la separazione audio basata su prompt, il video matting, la simulazione di mondi 4D, la generazione da video ad audio, l’OCR di documenti, la segmentazione on-device, l’editing audio espressivo e l’ASR in streaming a bassa latenza. Di seguito è riportata una versione ripulita e pronta per la pubblicazione del riepilogo settimanale originale, con gli screenshot utili conservati nel loro contesto originale.
Nota sulla fonte
Questo articolo si basa sull’aggiornamento settimanale di BAAI Hub / HyperAI pubblicato su La pagina originale indica che la fonte dell’articolo proviene da WeChat e che le immagini possono essere rimosse in caso di problemi di copyright.
Codici QR, poster promozionali, immagini di invito a gruppi e banner di raccomandazione non correlati sono stati rimossi intenzionalmente. I link alle immagini di DiaMoE-TTS e DreamOmni2 sono mantenuti nelle rispettive posizioni originali, ma le richieste di anteprima sono andate in timeout durante il controllo, quindi vengono indicati qui invece di essere trattati come screenshot pienamente verificati.
Panoramica dell’aggiornamento settimanale di HyperAI
Dal 27 giugno al 3 luglio, HyperAI ha aggiornato diverse risorse pubbliche sul proprio sito ufficiale:
- 12 tutorial pubblici selezionati
- 5 voci popolari dell’enciclopedia AI
- 4 scadenze di conferenze AI a luglio
Il tema principale di questa settimana è la sperimentazione pratica. La maggior parte delle voci non si limita a descrivere paper: offre demo online o notebook eseguibili, così gli utenti possono testare rapidamente il comportamento dei modelli.
Tutorial pubblici selezionati
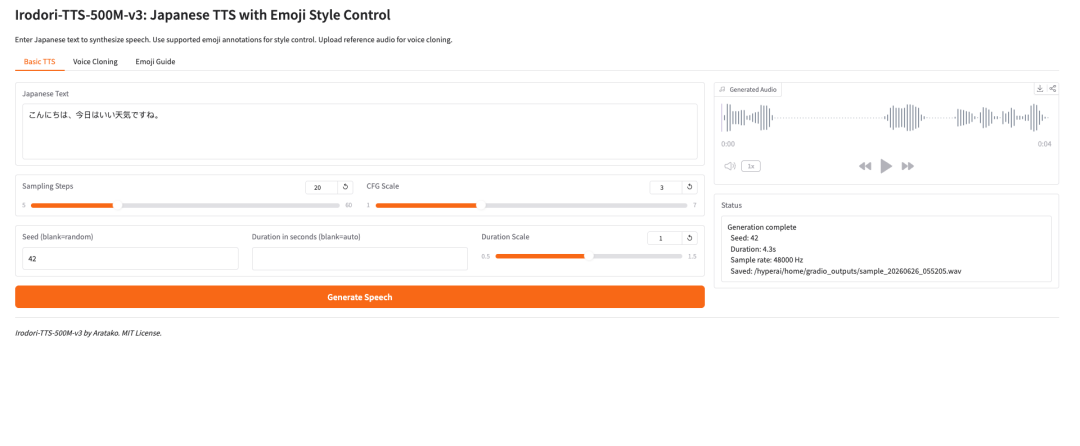
1. Irodori-TTS-500M-v3: TTS giapponese con controllo dello stile tramite emoji
Irodori-TTS è un progetto open source di sintesi vocale giapponese rilasciato dallo sviluppatore Aratako nel 2026. Il modello in evidenza, Irodori-TTS-500M-v3, è progettato per la sintesi vocale in giapponese, la clonazione vocale zero-shot e il controllo dello stile della voce guidato da emoji.
Il modello è costruito intorno a un’architettura Rectified Flow Diffusion Transformer (RF-DiT) e genera parlato in uno spazio latente DACVAE continuo. Nell’uso pratico, l’aspetto più interessante è che può clonare una voce target a partire da un breve clip di riferimento, di solito di circa 3-10 secondi, senza ulteriore fine-tuning.
Supporta inoltre il controllo dello stile tramite annotazioni emoji. Questo rende il modello più flessibile rispetto a un sistema TTS di base: gli utenti possono guidare tono, emozione, ritmo ed espressioni non verbali sottili in modo più leggero.
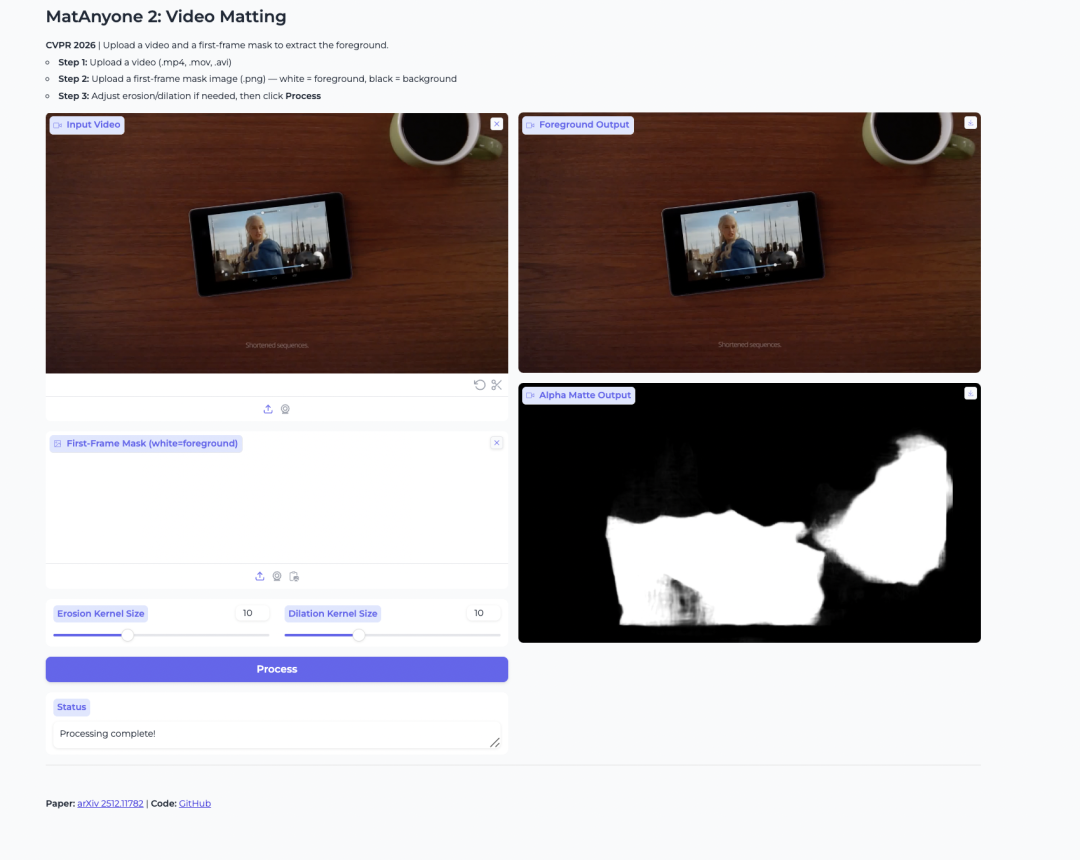
2. MatAnyone 2: video matting per l’estrazione del primo piano
MatAnyone 2 è un modello di video matting rilasciato da NTU S-Lab e SenseTime. È progettato per estrarre primi piani umani e generare alpha matte dai video.
Il modello migliora la stabilità utilizzando un valutatore di qualità appreso. Questo aiuta a ridurre gli artefatti sui bordi e a preservare dettagli come capelli, contorni semi-trasparenti e profili del primo piano. È utile anche quando l’utente desidera isolare una persona specifica in un video con più persone.
Demo online:
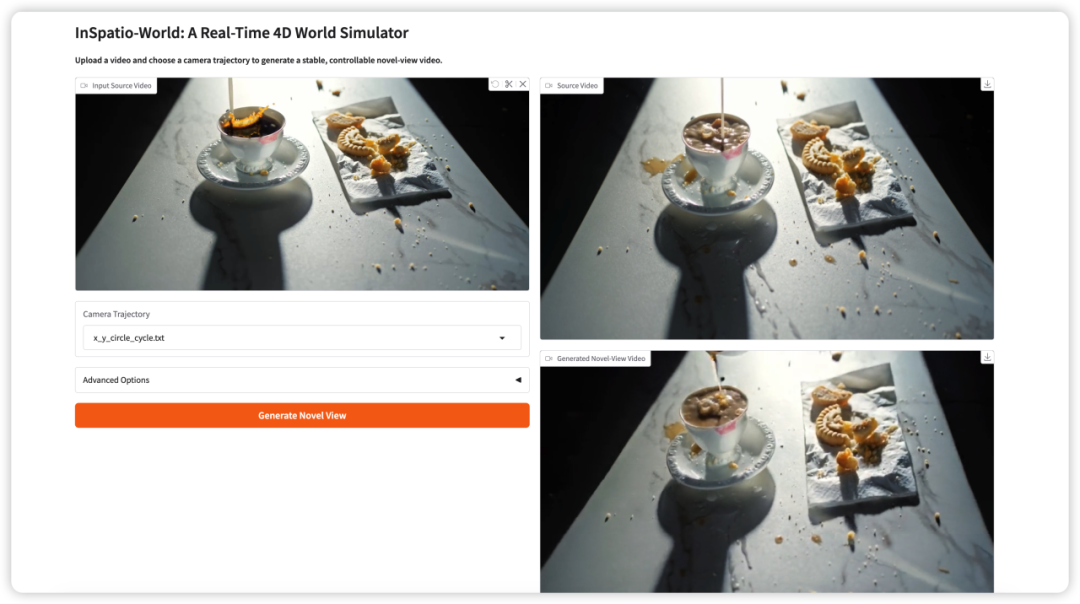
3. InSpatio-World: simulazione di mondi 4D in tempo reale
InSpatio-World è un simulatore di mondi 4D in tempo reale rilasciato dal team InSpatio nel 2026. Può prendere un video in input e una traiettoria di camera specificata, quindi generare un video stabile da una nuova prospettiva.
L’idea centrale è rendere le scene video più controllabili. Invece di osservare passivamente una vista da camera fissa, gli utenti possono definire il movimento della camera ed esplorare la scena da nuovi punti di vista, preservando al contempo la coerenza temporale.
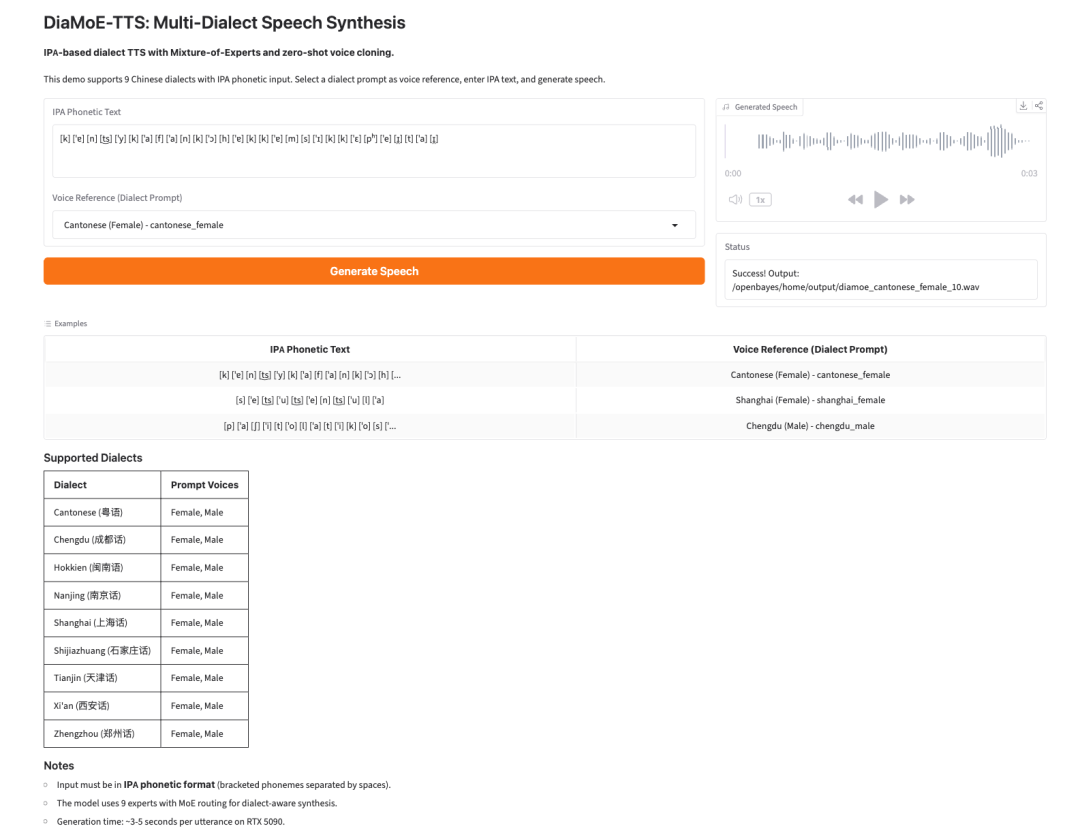
4. DiaMoE-TTS: sintesi vocale multidialettale basata su IPA
DiaMoE-TTS è un framework di sintesi vocale multidialettale sviluppato da Giant AI Lab. Utilizza l’Alfabeto Fonetico Internazionale, o IPA, come frontend unificato per la generazione vocale dialettale.
Il modello combina un design Mixture-of-Experts con metodi di adattamento efficienti in termini di parametri, come LoRA e conditioning adapter. Ciò consente al sistema di adattarsi più rapidamente a nuovi dialetti, anche quando sono disponibili solo dati limitati.
{kind=link}
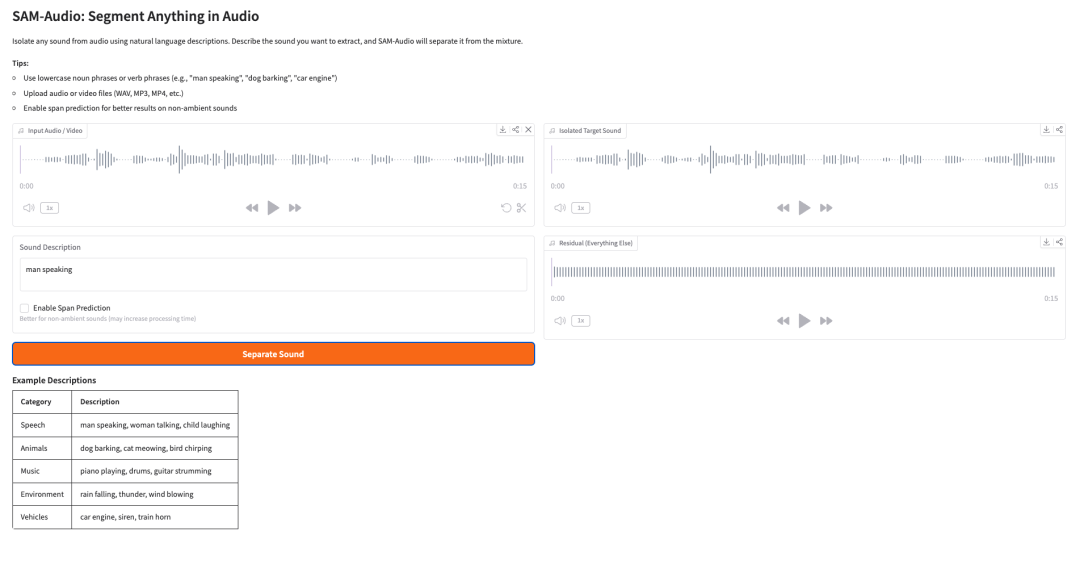
5. SAM-Audio: Segment Anything in Audio
SAM-Audio è il modello fondazionale di Meta per la separazione delle sorgenti audio. Può isolare un suono target da un segnale audio misto utilizzando descrizioni in linguaggio naturale, indizi visivi provenienti da un video oppure un intervallo temporale selezionato.
Per esempio, un utente può descrivere il suono che desidera separare, come “uomo che parla”, “cane che abbaia”, “motore di un’auto” o “pianoforte che suona”. Il modello tenta quindi di separare l’audio target da tutto il resto presente nella miscela.
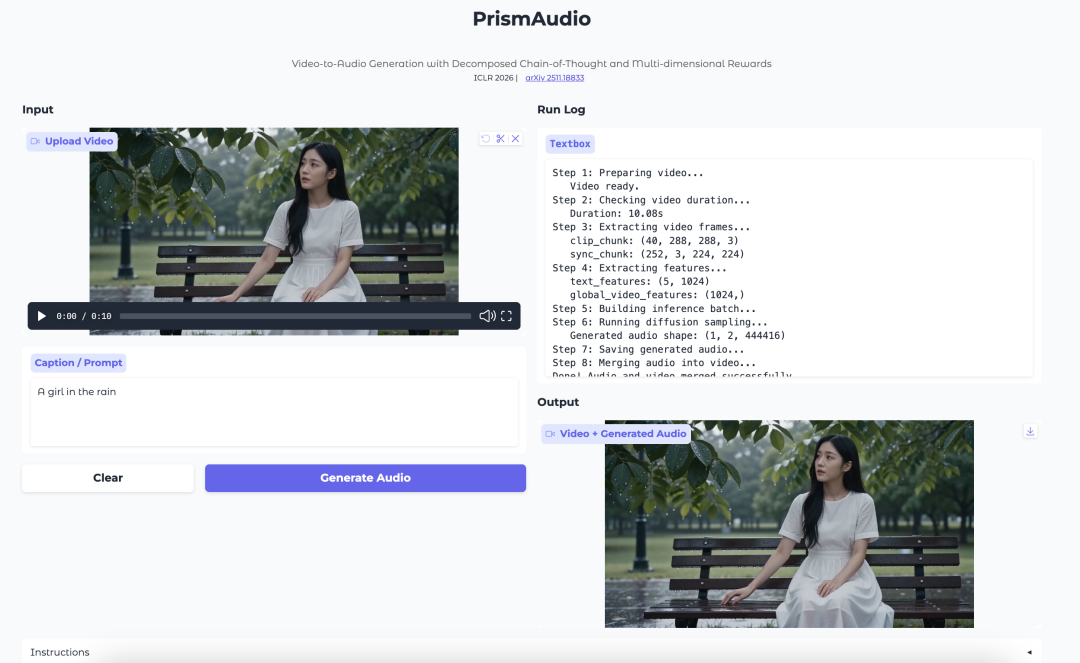
6. PrismAudio: Generazione video-audio con CoT scomposta e ricompense multidimensionali
PrismAudio è un modello di generazione audio da video sviluppato da Tongyi Lab. Si concentra sulla generazione di audio coerente con la scena visiva, il ritmo, l’atmosfera e la percezione spaziale di un video.
Il modello introduce un processo di pianificazione Chain-of-Thought scomposto. Invece di trattare la generazione video-audio come un unico passaggio di ragionamento, separa il processo in dimensioni semantiche, temporali, estetiche e spaziali. Ogni dimensione è associata a un segnale di ricompensa mirato per l’apprendimento per rinforzo.
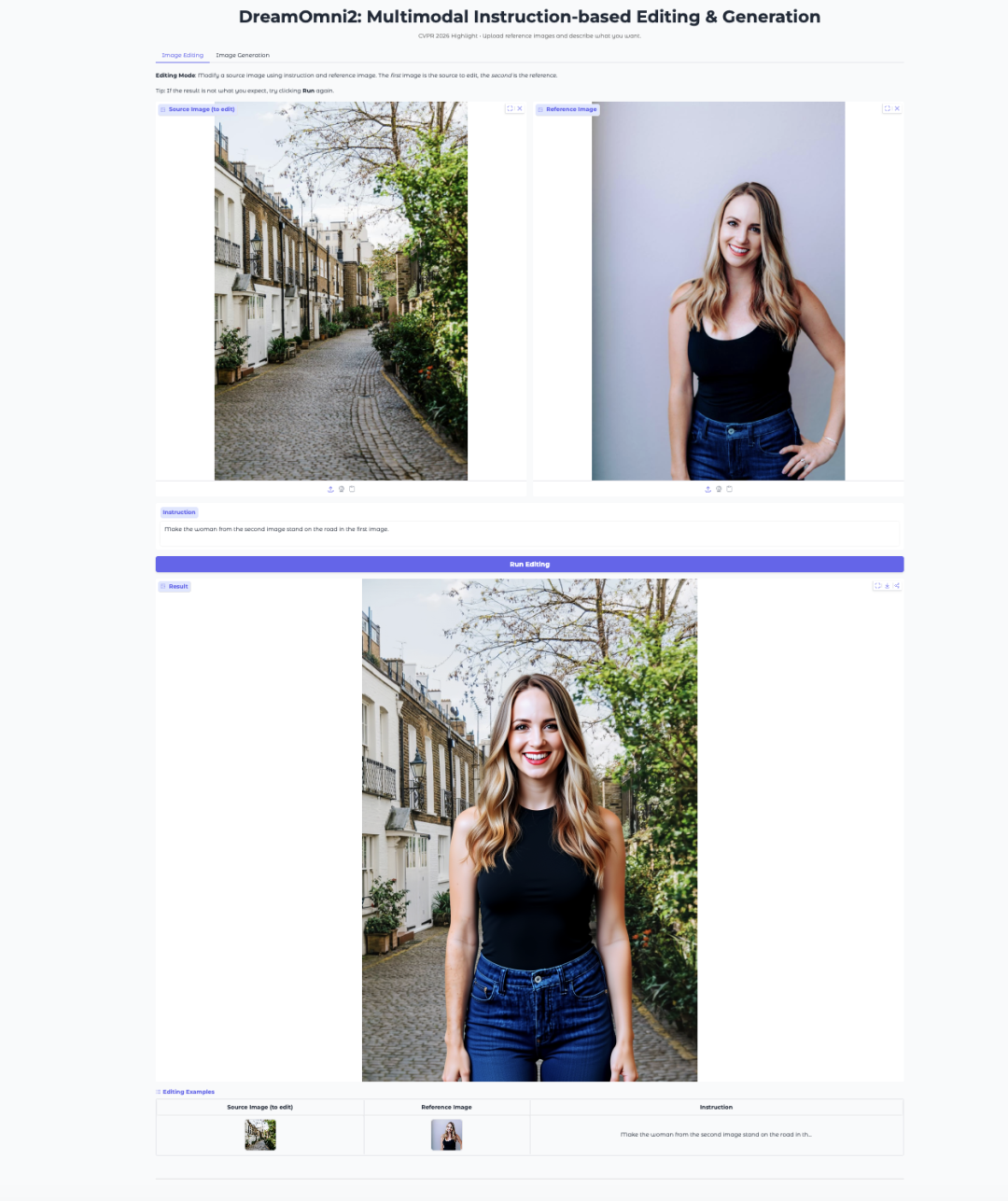
7. DreamOmni2: Editing e generazione di immagini multimodali basati su istruzioni
DreamOmni2 è un modello multimodale di editing e generazione di immagini sviluppato da CUHK JIA Lab. È stato accettato da CVPR 2026 come articolo Highlight.
Il modello è basato su FLUX.1-Kontext-dev e utilizza un modello visivo-linguistico Qwen2.5-VL-7B messo a punto per gestire le istruzioni. Supporta prompt in linguaggio naturale insieme a immagini di riferimento, rendendolo adatto a compiti come sostituzione di oggetti, trasferimento di stile, imitazione della posa e generazione guidata da concetti.
8. PixelRefer: Comprensione granulare degli oggetti per immagini e video
PixelRefer è un framework unificato di Alibaba DAMO Academy per la comprensione degli oggetti in immagini e video. Si concentra sulla comprensione fine-grained e centrata sugli oggetti, anziché limitarsi a descrivere un’intera scena.
Il framework supporta il pointing a livello di regione, la generazione di descrizioni e la risposta a domande. Introduce inoltre un tokenizer di oggetti adattivo alla scala e una variante più leggera, PixelRefer-Lite, per rendere la rappresentazione degli oggetti più compatta ed efficiente.

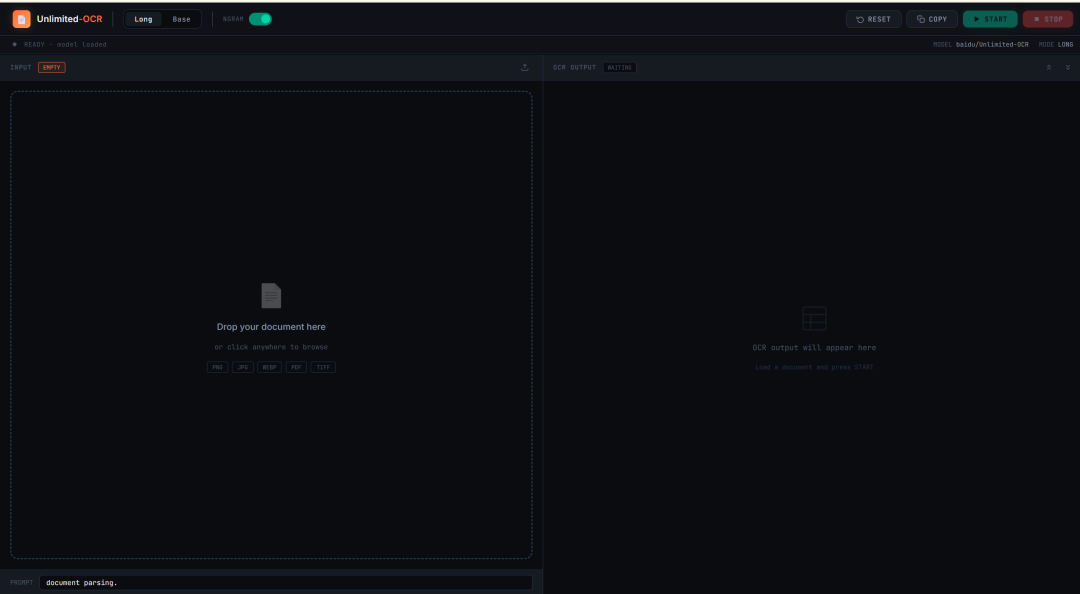
9. Unlimited-OCR: OCR one-shot per documenti lunghi e analisi del layout
Unlimited-OCR è un progetto di OCR e analisi del layout dei documenti rilasciato da Baidu nel 2026. È progettato per l’analisi di documenti lunghi, non solo per il riconoscimento di singole pagine.
Il progetto può elaborare immagini di singoli documenti, immagini multipagina e pagine convertite da PDF. È particolarmente utile per articoli scientifici, report, documenti scansionati, tabelle lunghe e materiali strutturati multipagina.
10. EdgeTAM: Segmentazione promptable di immagini e video per dispositivi edge
EdgeTAM è un modello Track Anything on-device sviluppato da Meta Reality Labs e NTU S-Lab. È progettato per dispositivi con risorse limitate, mantenendo al contempo la capacità di segmentazione interattiva dei modelli in stile SAM.
Il modello riduce il collo di bottiglia dell’attenzione in memoria di SAM 2 attraverso un 2D Spatial Perceiver e una pipeline di distillazione. In pratica, questo significa che può supportare una segmentazione promptable
segmentazione e tracciamento di oggetti video in modo più efficiente su hardware edge.

11. Step-Audio-EditX: clonazione vocale zero-shot ed editing audio espressivo
Step-Audio-EditX è un modello di editing audio di StepFun. Combina un modello audio basato su LLM da 3 miliardi di parametri con l’apprendimento per rinforzo per supportare la clonazione vocale zero-shot e l’editing audio espressivo.
Il modello è in grado di gestire mandarino, inglese, sichuanese, cantonese, giapponese e coreano. È progettato per attività come il controllo delle emozioni, la modifica dello stile di parlato, l’editing paralinguistico e il perfezionamento audio iterativo.

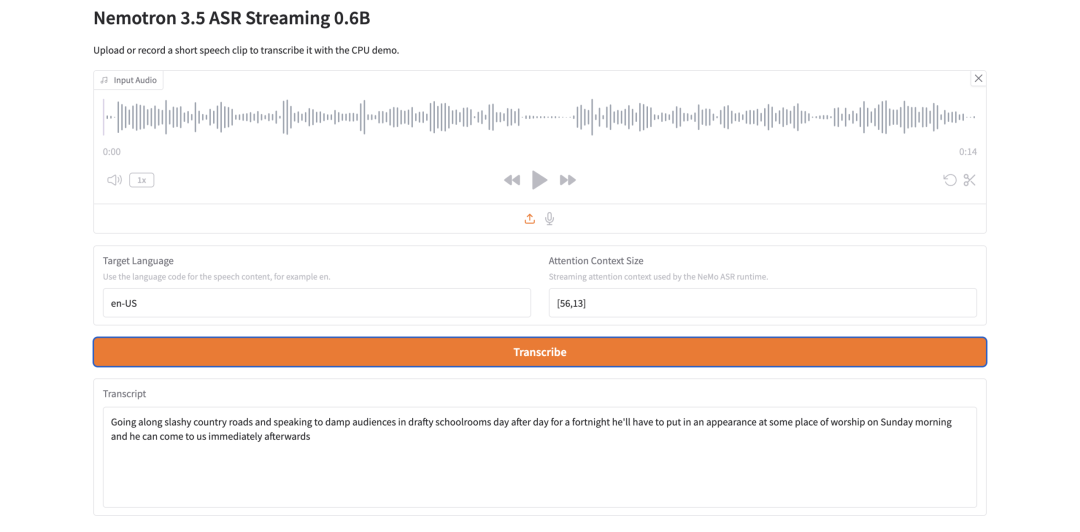
12. Nemotron 3.5 ASR Streaming 0.6B: riconoscimento vocale in streaming leggero
Nemotron 3.5 ASR Streaming 0.6B è un modello di riconoscimento vocale automatico di NVIDIA. È progettato per la trascrizione in streaming a bassa latenza e utilizza un’architettura FastConformer-RNNT sensibile alla cache.
Il principio chiave del design è il riutilizzo del contesto. Durante l’inferenza in streaming, il modello riutilizza il contesto dell’encoder invece di ricalcolare blocchi audio sovrapposti, contribuendo così a ridurre i calcoli ridondanti e a migliorare le prestazioni in tempo reale.
Voci enciclopediche popolari
Questa settimana HyperAI ha inoltre messo in evidenza cinque voci popolari della sua enciclopedia sull’IA:
- Large Language Model (LLM)
- World Action Model (WAM)
- Media armonica
- Screening virtuale
- Apprendimento per rinforzo da feedback dell’IA (RLAIF)
La wiki di HyperAI raccoglie centinaia di concetti e spiegazioni relativi all’IA. È utile per i lettori che desiderano un modo rapido per comprendere termini che compaiono spesso in articoli scientifici, tutorial e documentazione dei modelli.
Scadenze delle conferenze sull’IA a luglio
L’aggiornamento originale elenca anche diverse scadenze di conferenze di IA e informatica a luglio. Tutti gli orari di scadenza sono indicati in orario AoE.
| Data | Ora | Conferenza |
|---|---|---|
| 09 luglio | 23:59:59 | POPL 2027 |
| 10 luglio | 23:59:59 | ICSE 2027 |
| 17 luglio | 23:59:59 | SIGMOD 2027 |
| 28 luglio | 23:59:59 | AAAI 2027 |
Informazioni su HyperAI
HyperAI è una community dedicata all’intelligenza artificiale e al calcolo ad alte prestazioni. Il suo sito web fornisce risorse pubbliche per sviluppatori, ricercatori e studenti di IA.
Secondo la fonte originale, HyperAI ha già raccolto o supportato:
- oltre 2.100 dataset pubblici con nodi di accelerazione domestici
- oltre 700 tutorial online classici e popolari
- oltre 300 case study di articoli AI4Science
- oltre 700 voci enciclopediche relative all’IA
- un mirror completo della documentazione cinese di Apache TVM
FAQ
Che cos’è Irodori-TTS-500M-v3?
Irodori-TTS-500M-v3 è un modello open source giapponese di sintesi vocale basato su testo, fondato su un’architettura RF-DiT. Supporta la generazione di parlato in giapponese, la clonazione vocale zero-shot con un breve riferimento e il controllo dello stile tramite emoji.
Irodori-TTS può clonare una voce senza fine-tuning?
Sì. L’aggiornamento originale descrive Irodori-TTS come in grado di supportare la clonazione vocale zero-shot a partire da un breve clip audio di riferimento, in genere di circa 3-10 secondi. Il risultato dipende comunque dalla qualità e dalla chiarezza dell’audio di riferimento.
A cosa serve SAM-Audio?
SAM-Audio viene utilizzato per la separazione delle sorgenti audio basata su prompt. Gli utenti possono descrivere il suono che desiderano estrarre, fornire indizi visivi oppure specificare un intervallo temporale per isolare un suono target da una registrazione mista.
Qual è la differenza tra video matting e segmentazione video?
La segmentazione video di solito separa gli oggetti in regioni o maschere, mentre il video matting stima un alpha matte più dettagliato. Il matting è particolarmente importante per l’estrazione pulita del primo piano, i dettagli dei capelli, i bordi semitrasparenti e il compositing.
Che cosa genera PrismAudio?
PrismAudio genera audio per i video. Cerca di allineare il suono generato con il contenuto semantico, il timing, la sensazione estetica e gli indizi spaziali del video.
Perché Unlimited-OCR è utile per i documenti lunghi?
Unlimited-OCR è progettato per l’analisi a lungo orizzonte, non solo per l’OCR di singole pagine isolate. Può essere utile quando si lavora con articoli scientifici, report, file scansionati, tabelle lunghe o immagini derivate da PDF multipagina.
Nemotron 3.5 ASR Streaming 0.6B è adatto alla trascrizione vocale in tempo reale?
Sì, è progettato per una bassa latenza
ASR in streaming. La sua architettura FastConformer-RNNT consapevole della cache riutilizza il contesto durante l’inferenza in streaming, contribuendo a ridurre i calcoli ridondanti.
Strumenti correlati
- Irodori-TTS: TTS giapponese open source con clonazione vocale da audio di riferimento e controllo dello stile.
- Irodori-TTS-500M-v3 su Hugging Face: Pagina del modello per il checkpoint TTS giapponese 500M v3.
- SAM-Audio: Repository di Meta per l’inferenza e gli esempi di Segment Anything in Audio.
- MatAnyone 2: Pagina del progetto per il framework di video matting MatAnyone 2.
- InSpatio-World: Pagina del progetto per la simulazione interattiva in tempo reale di mondi 4D.
- DiaMoE-TTS: Repository GitHub per la sintesi vocale multidialettale basata su IPA.
- PrismAudio: Pagina del progetto per la generazione da video ad audio con CoT decomposta e ricompense multidimensionali.
- DreamOmni2: Progetto open source di editing e generazione di immagini multimodale basato su istruzioni.
- PixelRefer: Framework di Alibaba DAMO Academy per la comprensione fine-grained di oggetti in immagini e video.
- Unlimited-OCR: Progetto di Baidu per OCR a lungo orizzonte e parsing di documenti.
- EdgeTAM: Modello on-device di Meta per il tracciamento di qualsiasi oggetto, con segmentazione promptable di immagini e video.
- Step-Audio-EditX: Modello di StepFun per clonazione vocale zero-shot ed editing audio espressivo.
- Nemotron 3.5 ASR Streaming 0.6B: Pagina del modello NVIDIA su Hugging Face per ASR in streaming a bassa latenza.
Link correlati
- Articolo originale su BAAI Hub: Articolo fonte per questo aggiornamento settimanale di HyperAI.
- Sito ufficiale di HyperAI: Portale principale per tutorial, paper, dataset e risorse AI di HyperAI.
- HyperAI Wiki: Portale enciclopedico sull’AI che copre concetti comuni e termini di ricerca.
- HyperAI Conference Tracker: Strumento di monitoraggio delle scadenze delle conferenze di AI e informatica.
- Pagina di ricerca Meta SAM-Audio: Pagina di ricerca ufficiale per Segment Anything Model Audio.
- Paper di SAM-Audio su arXiv: Paper di ricerca che descrive il modello fondazionale SAM-Audio.
- Paper di MatAnyone 2 su arXiv: Paper su MatAnyone 2 e sul suo valutatore appreso della qualità del matting.
- Paper di Unlimited-OCR su arXiv: Report tecnico su Unlimited OCR e parsing a lungo orizzonte.
Riepilogo
Questo aggiornamento settimanale riunisce un gruppo utile di nuove demo AI e risorse di modelli, in particolare nell’ambito della generazione audio, del riconoscimento vocale, dell’elaborazione video, della comprensione delle immagini e dell’OCR per documenti lunghi.
Le voci più pratiche sono Irodori-TTS per la generazione vocale in giapponese, SAM-Audio per la separazione sonora basata su prompt, MatAnyone 2 per un video matting pulito, Unlimited-OCR per documenti lunghi e Nemotron 3.5 ASR per il riconoscimento vocale in streaming.
Nel complesso, questa rassegna è utile per i lettori che vogliono scoprire rapidamente quali nuovi modelli AI vale la pena testare, cosa fa ciascuno di essi e dove provarli.