HyperAI 주간 AI 모델 업데이트: Irodori-TTS, SAM-Audio, MatAnyone 2, PrismAudio 등
이번 주간 업데이트는 오디오 생성, 음성 인식, 영상 처리, 이미지 이해, 장문 문서 OCR을 중심으로 유용한 신규 AI 데모와 모델 리소스를 한데 모았습니다. 가장 실용적인 항목으로는 일본어 음성 생성을 위한 Irodori-TTS, 프롬프트 기반 소리 분리를 위한 SAM-Audio, 깔끔한 비디오 매팅을 위한 MatAnyone 2, 장문 문서를 위한 Unlimited-OCR, 스트리밍 음성 인식을 위한 Nemotron 3.5 ASR이 있습니다. **전반적으로 이 모음은 어떤 신규 AI 모델이 테스트해 볼 만한지, 각 모델이 무엇을 하는지, 어디에서 사용해 볼 수 있는지를 빠르게 파악하고 싶은 독자에게 유용합니다.**

HyperAI 주간 AI 모델 업데이트: Irodori-TTS, SAM-Audio, MatAnyone 2, PrismAudio 등
소개
이번 주 HyperAI 업데이트는 오디오, 비디오, 이미지 이해, OCR, 음성 인식 모델을 폭넓게 다룹니다. 주요 프로젝트는 Irodori-TTS-500M-v3로, 고충실도 48 kHz 음성 생성, 제로샷 음성 복제, 이모지 주석을 통한 세밀한 스타일 제어를 결합한 오픈 일본어 텍스트 음성 변환 모델입니다.
이번 업데이트에는 프롬프트 기반 오디오 분리, 비디오 매팅, 4D 월드 시뮬레이션, 비디오-오디오 생성, 문서 OCR, 온디바이스 세그멘테이션, 표현력 있는 오디오 편집, 저지연 스트리밍 ASR을 위한 도구도 포함되어 있습니다. 아래는 원본 주간 요약을 정리해 발행 가능한 형태로 다듬은 버전이며, 유용한 스크린샷은 원래 문맥에 맞게 유지했습니다.
출처 안내
이 글은 BAAI Hub / HyperAI 주간 업데이트를 기반으로 합니다. 원문 페이지에는 글의 출처가 WeChat이며, 저작권 문제가 있을 경우 이미지를 삭제할 수 있다고 명시되어 있습니다.
QR 코드, 홍보 포스터, 그룹 초대 이미지, 관련 없는 추천 배너는 의도적으로 제거했습니다. DiaMoE-TTS와 DreamOmni2 이미지 링크는 원래 위치에 유지했지만, 확인 과정에서 미리보기 요청 시간이 초과되어 완전히 검증된 스크린샷으로 처리하지 않고 이곳에 별도로 언급합니다.
주간 HyperAI 업데이트 개요
6월 27일부터 7월 3일까지, HyperAI는 공식 웹사이트의 여러 공개 리소스를 업데이트했습니다.
- 선별된 공개 튜토리얼 12개
- 인기 AI 백과 항목 5개
- 7월 AI 학회 마감 일정 4개
이번 주의 핵심 주제는 실용적인 실험입니다. 대부분의 항목은 단순한 논문 설명에 그치지 않고, 사용자가 모델 동작을 빠르게 테스트할 수 있도록 온라인 데모나 실행 가능한 노트북을 제공합니다.
선별된 공개 튜토리얼
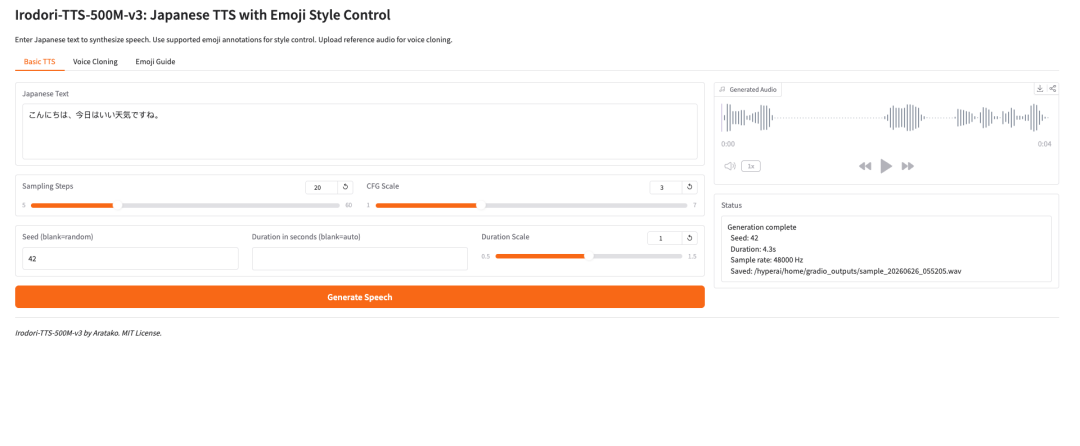
1. Irodori-TTS-500M-v3: 이모지 스타일 제어를 지원하는 일본어 TTS
Irodori-TTS는 개발자 Aratako가 2026년에 공개한 오픈소스 일본어 텍스트 음성 변환 프로젝트입니다. 소개된 모델인 Irodori-TTS-500M-v3는 일본어 음성 합성, 제로샷 음성 복제, 이모지 기반 음성 스타일 제어를 위해 설계되었습니다.
이 모델은 Rectified Flow Diffusion Transformer(RF-DiT) 아키텍처를 기반으로 하며, 연속적인 DACVAE 잠재 공간에서 음성을 생성합니다. 실제 사용에서 가장 흥미로운 점은 추가 파인튜닝 없이도 보통 3~10초 정도의 짧은 참조 클립만으로 대상 음성을 복제할 수 있다는 것입니다.
또한 이모지 주석을 통한 스타일 제어도 지원합니다. 이를 통해 사용자는 기본 TTS 시스템보다 더 유연하게 톤, 감정, 말하기 속도, 미묘한 비언어적 표현을 가볍게 안내할 수 있습니다.
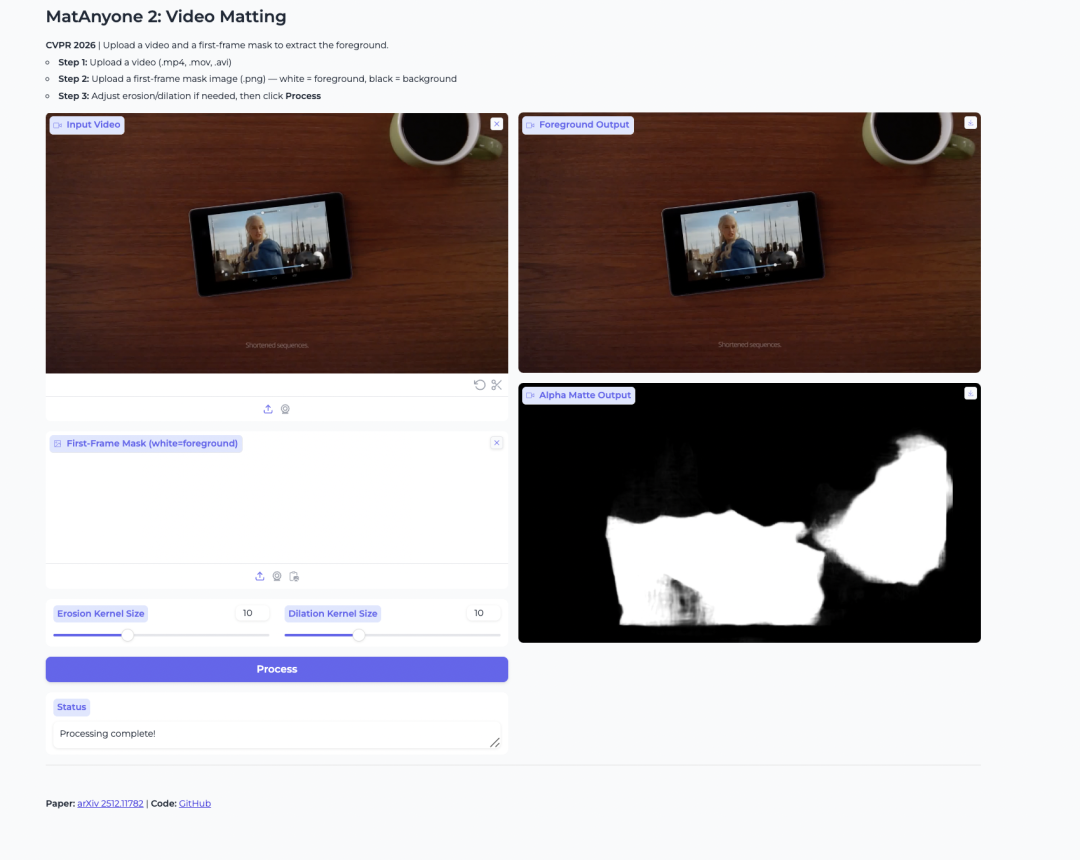
2. MatAnyone 2: 전경 추출을 위한 비디오 매팅
MatAnyone 2는 NTU S-Lab과 SenseTime이 공개한 비디오 매팅 모델입니다. 비디오에서 사람 전경을 추출하고 알파 매트를 생성하도록 설계되었습니다.
이 모델은 학습된 품질 평가기를 사용해 안정성을 향상합니다. 이를 통해 경계 아티팩트를 줄이고 머리카락, 반투명 가장자리, 전경 윤곽과 같은 세부 정보를 보존하는 데 도움이 됩니다. 또한 여러 사람이 등장하는 비디오에서 특정 인물을 분리하려는 경우에도 유용합니다.
온라인 데모:
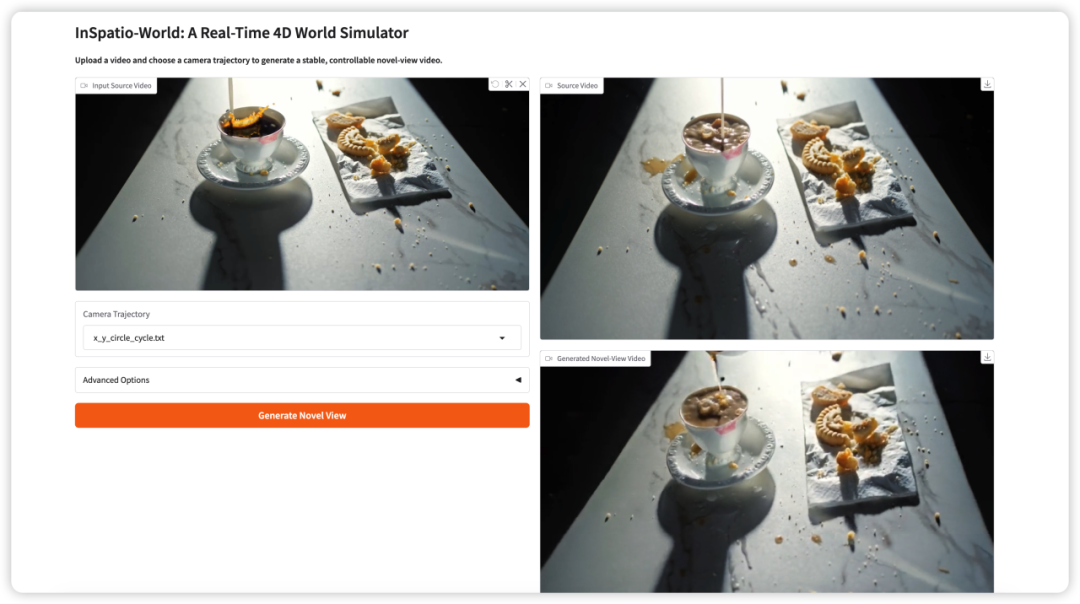
3. InSpatio-World: 실시간 4D 월드 시뮬레이션
InSpatio-World는 InSpatio 팀이 2026년에 공개한 실시간 4D 월드 시뮬레이터입니다. 입력 비디오와 지정된 카메라 궤적을 받아 안정적인 새로운 시점의 비디오를 생성할 수 있습니다.
핵심 아이디어는 비디오 장면을 더 제어 가능하게 만드는 것입니다. 사용자는 고정된 카메라 뷰를 수동적으로 시청하는 대신, 카메라 움직임을 정의하고 시간적 일관성을 유지하면서 새로운 시점에서 장면을 탐색할 수 있습니다.
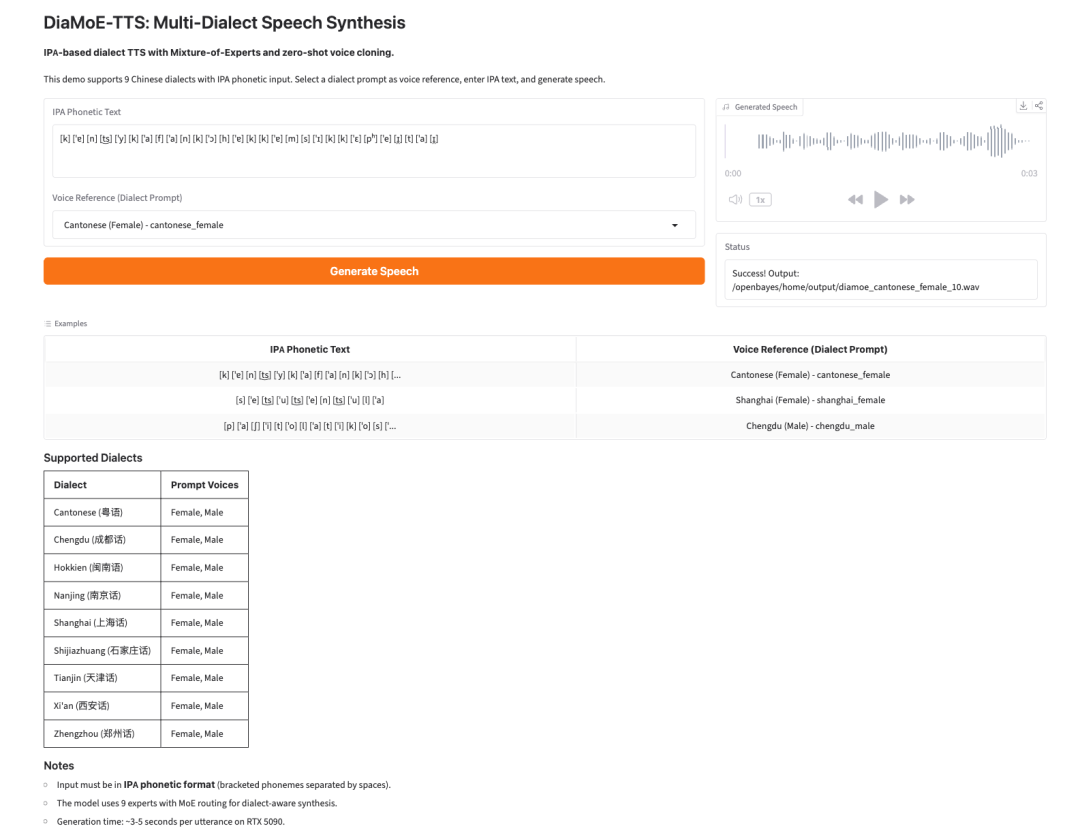
4. DiaMoE-TTS: IPA 기반 다중 방언 음성 합성
DiaMoE-TTS는 Giant AI Lab이 개발한 다중 방언 음성 합성 프레임워크입니다. 방언 음성 생성을 위한 통합 프런트엔드로 국제음성기호, 즉 IPA를 사용합니다.
이 모델은 Mixture-of-Experts 설계와 LoRA 및 조건부 어댑터 같은 매개변수 효율적 적응 방법을 결합합니다. 이를 통해 제한된 데이터만 있는 경우에도 시스템이 새로운 방언에 더 빠르게 적응할 수 있습니다.
위쪽에는 IPA 기반 Mixture-of-Experts 설계와 LoRA 및 조건부 어댑터와 같은 파라미터 효율적 적응 방법에 대한 소개가 있다. 가운데에는 “Generate Speech” 버튼이 있고, 아래쪽에는 예시 텍스트 입력창이 있으며 9가지 중국 방언을 지원한다. 오른쪽에는 생성된 음성 파형과 음성 참조(방언 프롬프트)가 표시된다. 하단에는 지원되는 방언과 해당 프롬프트 음성이 나열되어 있으며, 모델이 KPL 모델을 사용해 방언 합성을 수행한다는 점과 생성 시간 등의 정보도 표시되어 있다. 이 그림은 문서에서 소개하는 DiaMoE-TTS 모델의 내용과 관련이 있으며, 해당 모델의 조작 인터페이스와 기능을 직관적으로 보여준다.](https://we0-cms.oss-cn-beijing.aliyuncs.com/cms-assets/image/2026/07/094c618c-2830-4af5-9cdc-ca950fe12565-05-c0ba34b2-8a4a-4e6a-9d15-517f152cb52a.png)
{kind=link}
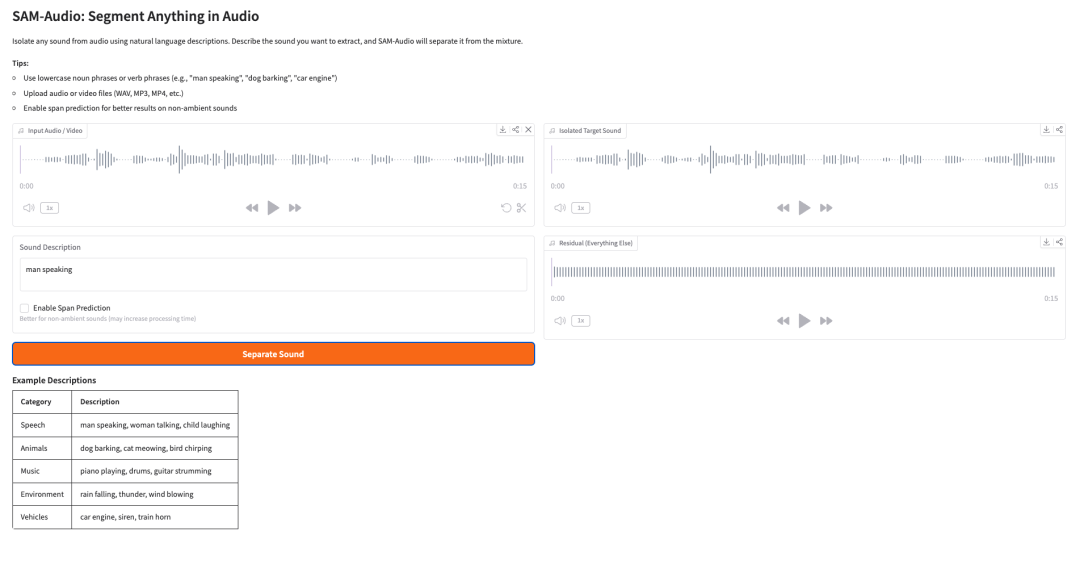
5. SAM-Audio: 오디오에서 무엇이든 분할하기
SAM-Audio는 Meta의 오디오 소스 분리 기반 모델이다. 자연어 설명, 비디오의 시각적 단서 또는 선택한 시간 구간을 사용해 혼합 오디오 신호에서 목표 소리를 분리할 수 있다.
예를 들어 사용자는 “man speaking”, “dog barking”, “car engine”, “piano playing”처럼 분리하고 싶은 소리를 설명할 수 있다. 그러면 모델은 혼합 신호에서 목표 오디오를 나머지 소리와 분리하려고 시도한다.
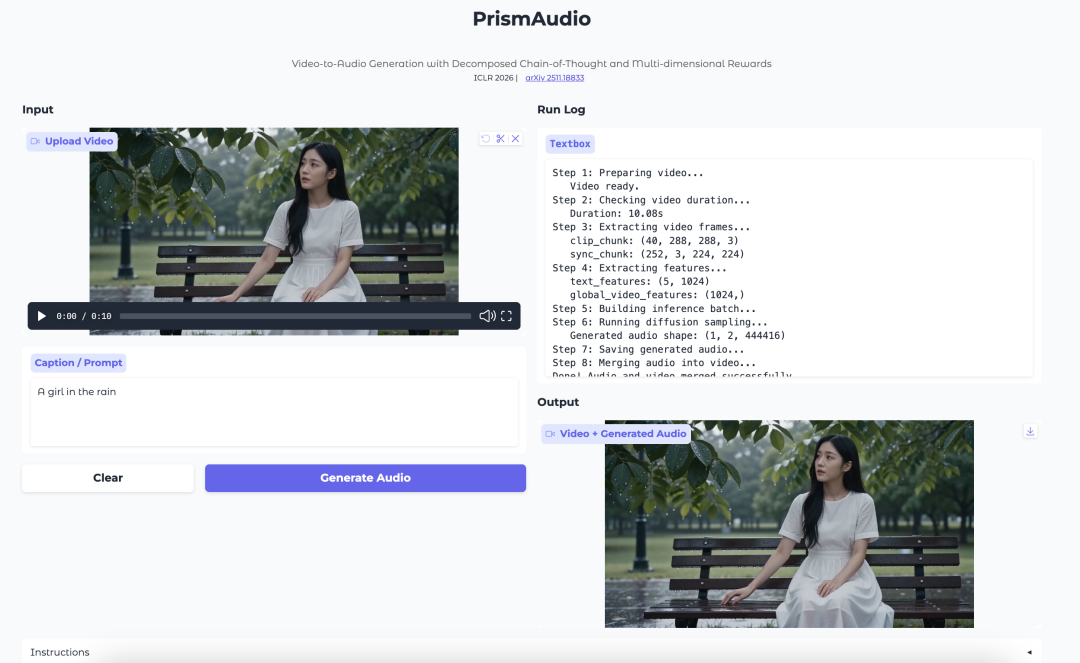
6. PrismAudio: 분해된 CoT와 다차원 보상을 활용한 비디오-오디오 생성
PrismAudio는 Tongyi Lab의 비디오-오디오 생성 모델이다. 비디오의 시각 장면, 타이밍, 분위기, 공간감을 잘 반영하는 오디오를 생성하는 데 중점을 둔다.
이 모델은 분해된 Chain-of-Thought 계획 프로세스를 도입한다. 비디오-오디오 생성을 하나의 단일 추론 단계로 처리하는 대신, 과정을 의미, 시간, 미학, 공간 차원으로 분리한다. 각 차원은 강화학습을 위한 목적별 보상 신호와 연결된다.
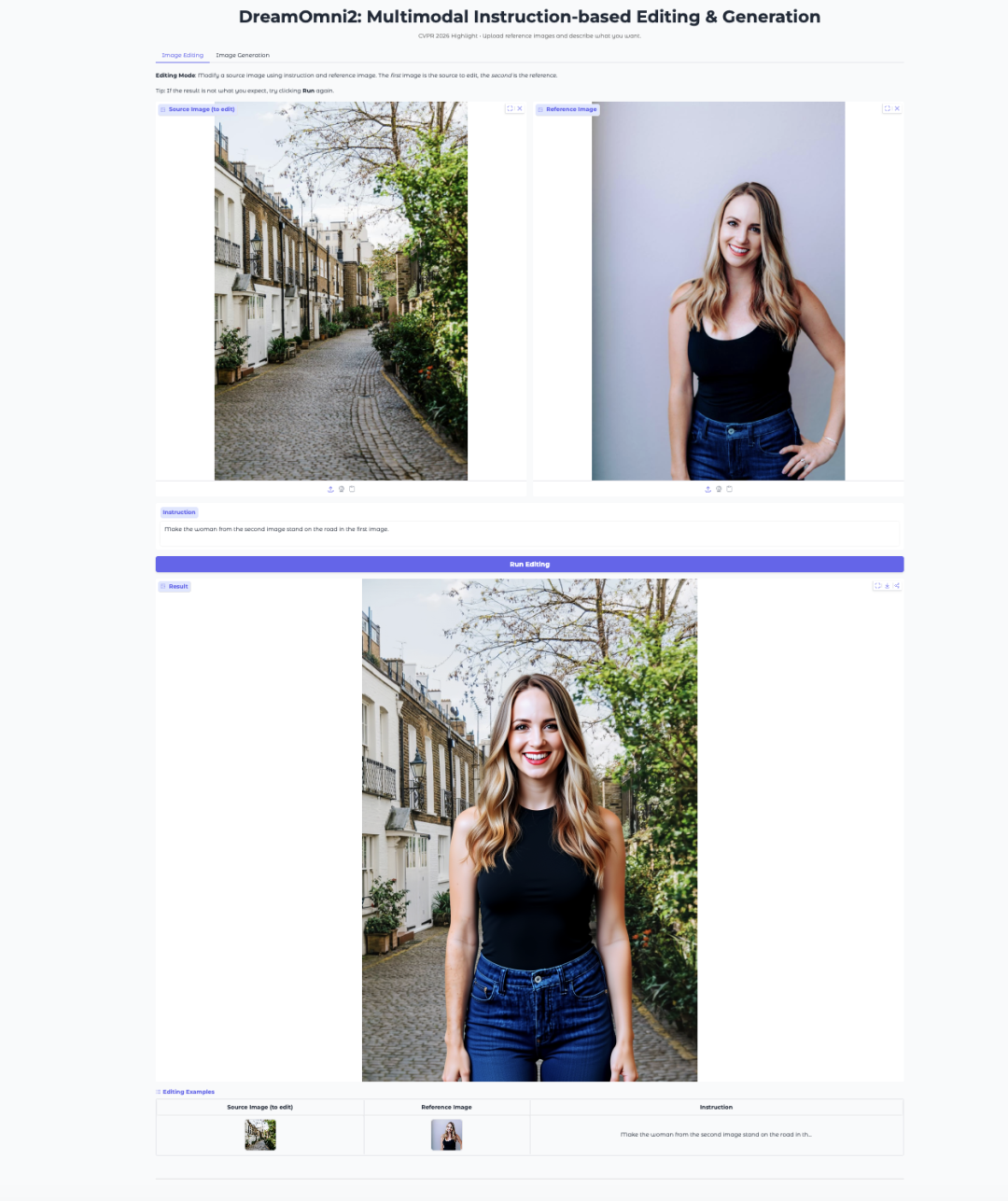
7. DreamOmni2: 멀티모달 지시 기반 이미지 편집 및 생성
DreamOmni2는 CUHK JIA Lab의 멀티모달 이미지 편집 및 생성 모델이다. 이 모델은 CVPR 2026에서 Highlight 논문으로 채택되었다.
이 모델은 FLUX.1-Kontext-dev를 기반으로 구축되었으며, 지시어 처리를 위해 미세 조정된 Qwen2.5-VL-7B 시각 언어 모델을 사용한다. 자연어 프롬프트와 참조 이미지를 함께 지원하므로 객체 교체, 스타일 전환, 포즈 모방, 개념 기반 생성과 같은 작업에 적합하다.
8. PixelRefer: 이미지와 비디오를 위한 세밀한 객체 이해
PixelRefer는 Alibaba DAMO Academy의 통합 이미지 및 비디오 객체 이해 프레임워크이다. 전체 장면을 설명하는 데 그치지 않고, 객체 중심의 세밀한 이해에 초점을 맞춘다.
이 프레임워크는 영역 수준의 포인팅, 캡셔닝, 질의응답을 지원한다. 또한 객체 표현을 더 간결하고 효율적으로 만들기 위해 스케일 적응형 객체 토크나이저와 더 가벼운 PixelRefer-Lite 변형 모델을 도입한다.

9. Unlimited-OCR: 원샷 장문 문서 OCR 및 레이아웃 파싱
Unlimited-OCR는 Baidu가 2026년에 공개한 OCR 및 문서 레이아웃 파싱 프로젝트이다. 단일 페이지 인식에만 국한되지 않고 장문 문서 파싱을 위해 설계되었다.
이 프로젝트는 단일 문서 이미지, 다중 페이지 이미지, PDF에서 변환된 페이지를 처리할 수 있다. 특히 논문, 보고서, 스캔 문서, 긴 표, 다중 페이지 구조화 자료에 유용하다.
10. EdgeTAM: 엣지 디바이스를 위한 프롬프트 기반 이미지 및 비디오 세그멘테이션
EdgeTAM은 Meta Reality Labs와 NTU S-Lab이 개발한 온디바이스 Track Anything Model이다. SAM 스타일 모델의 인터랙티브 세그멘테이션 능력을 유지하면서도 리소스가 제한된 디바이스를 위해 설계되었다.
이 모델은 2D Spatial Perceiver와 지식 증류 파이프라인을 통해 SAM 2의 메모리 어텐션 병목을 줄인다. 실제로 이는 프롬프트 기반을 지원할 수 있음을 의미한다.
에지 하드웨어에서 분할 및 비디오 객체 추적을 더 효율적으로 수행합니다.

11. Step-Audio-EditX: 제로샷 음성 클로닝 및 표현력 있는 오디오 편집
Step-Audio-EditX는 StepFun의 오디오 편집 모델입니다. 30억 개 파라미터의 LLM 기반 오디오 모델과 강화학습을 결합하여 제로샷 음성 클로닝과 표현력 있는 오디오 편집을 지원합니다.
이 모델은 중국어 표준어, 영어, 쓰촨어, 광둥어, 일본어, 한국어를 처리할 수 있습니다. 감정 제어, 말하기 스타일 편집, 준언어적 편집, 반복적 오디오 개선과 같은 작업을 위해 구축되었습니다.

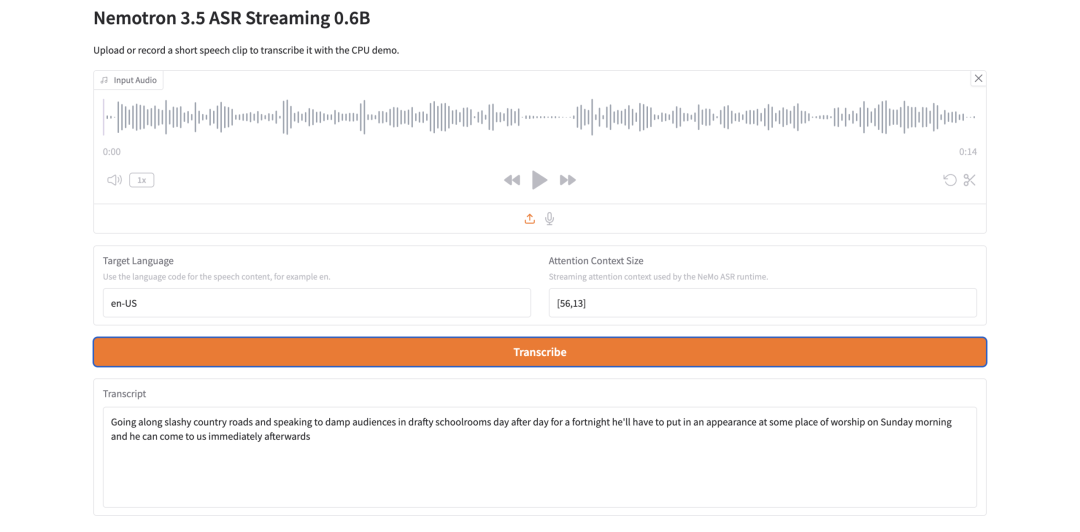
12. Nemotron 3.5 ASR Streaming 0.6B: 경량 스트리밍 음성 인식
Nemotron 3.5 ASR Streaming 0.6B는 NVIDIA의 자동 음성 인식 모델입니다. 저지연 스트리밍 전사를 위해 구축되었으며, 캐시 인식 FastConformer-RNNT 아키텍처를 사용합니다.
핵심 설계는 컨텍스트 재사용입니다. 스트리밍 추론 중 모델은 겹치는 오디오 청크를 다시 계산하는 대신 인코더 컨텍스트를 재사용하여 중복 계산을 줄이고 실시간 성능을 개선하는 데 도움이 됩니다.
인기 백과 항목
HyperAI는 이번 주 인기 AI 백과 항목 다섯 가지도 소개했습니다.
- 대규모 언어 모델(LLM)
- 월드 액션 모델(WAM)
- 조화 평균
- 가상 스크리닝
- AI 피드백 기반 강화학습(RLAIF)
HyperAI의 위키는 AI 관련 개념과 설명 수백 가지를 모아 제공합니다. 논문, 튜토리얼, 모델 문서에 자주 등장하는 용어를 빠르게 이해하고 싶은 독자에게 유용합니다.
7월 AI 학회 마감일
원문 업데이트에는 7월의 여러 AI 및 컴퓨터 과학 학회 마감일도 나열되어 있습니다. 모든 마감 시간은 AoE 시간으로 표시되어 있습니다.
| 날짜 | 시간 | 학회 |
|---|---|---|
| 7월 09일 | 23:59:59 | POPL 2027 |
| 7월 10일 | 23:59:59 | ICSE 2027 |
| 7월 17일 | 23:59:59 | SIGMOD 2027 |
| 7월 28일 | 23:59:59 | AAAI 2027 |
HyperAI 소개
HyperAI는 인공지능 및 고성능 컴퓨팅 커뮤니티입니다. 해당 웹사이트는 개발자, 연구자, AI 학습자를 위한 공개 리소스를 제공합니다.
원문 출처에 따르면 HyperAI는 이미 다음을 수집하거나 지원하고 있습니다.
- 국내 가속 노드를 갖춘 2,100개 이상의 공개 데이터셋
- 700개 이상의 고전 및 인기 온라인 튜토리얼
- 300개 이상의 AI4Science 논문 사례 연구
- 700개 이상의 AI 관련 백과 항목
- Apache TVM의 완전한 중국어 문서 미러
FAQ
Irodori-TTS-500M-v3는 무엇인가요?
Irodori-TTS-500M-v3는 RF-DiT 아키텍처를 기반으로 한 오픈 일본어 텍스트 음성 변환 모델입니다. 일본어 음성 생성, 짧은 참조 기반 제로샷 음성 클로닝, 이모지 기반 스타일 제어를 지원합니다.
Irodori-TTS는 파인튜닝 없이 음성을 클로닝할 수 있나요?
네. 원문 업데이트에서는 Irodori-TTS가 보통 약 3~10초 길이의 짧은 참조 오디오 클립을 통해 제로샷 음성 클로닝을 지원한다고 설명합니다. 다만 결과는 참조 오디오의 품질과 명료도에 따라 달라집니다.
SAM-Audio는 무엇에 사용되나요?
SAM-Audio는 프롬프트 기반 오디오 소스 분리에 사용됩니다. 사용자는 추출하려는 소리를 설명하거나, 시각적 단서를 제공하거나, 시간 범위를 지정하여 혼합 녹음에서 목표 소리를 분리할 수 있습니다.
비디오 매팅과 비디오 분할의 차이는 무엇인가요?
비디오 분할은 일반적으로 객체를 영역이나 마스크로 분리하는 반면, 비디오 매팅은 더 세밀한 알파 매트를 추정합니다. 매팅은 깔끔한 전경 추출, 머리카락 디테일, 반투명 가장자리, 합성 작업에 특히 중요합니다.
PrismAudio는 무엇을 생성하나요?
PrismAudio는 비디오용 오디오를 생성합니다. 생성된 사운드를 비디오의 의미적 내용, 타이밍, 미적 느낌, 공간적 단서와 정렬하려고 합니다.
Unlimited-OCR은 긴 문서에 왜 유용한가요?
Unlimited-OCR은 단순히 개별 단일 페이지 OCR이 아니라 장기 범위 파싱을 위해 설계되었습니다. 논문, 보고서, 스캔 파일, 긴 표, 여러 페이지 PDF에서 파생된 이미지를 처리할 때 유용할 수 있습니다.
Nemotron 3.5 ASR Streaming 0.6B는 실시간 음성 전사에 적합한가요?
네, 저지연 처리를 위해 설계되었습니다.
스트리밍 ASR. 캐시 인식 FastConformer-RNNT 아키텍처는 스트리밍 추론 중 컨텍스트를 재사용하여 중복 연산을 줄이는 데 도움이 됩니다.
관련 도구
- Irodori-TTS: 참조 오디오 기반 음성 복제와 스타일 제어를 지원하는 오픈소스 일본어 TTS.
- Hugging Face의 Irodori-TTS-500M-v3: 500M v3 일본어 TTS 체크포인트의 모델 페이지.
- SAM-Audio: 오디오에서 Segment Anything 추론 및 예제를 제공하는 Meta의 저장소.
- MatAnyone 2: MatAnyone 2 비디오 매팅 프레임워크의 프로젝트 페이지.
- InSpatio-World: 실시간 인터랙티브 4D 월드 시뮬레이션 프로젝트 페이지.
- DiaMoE-TTS: IPA 기반 다중 방언 음성 합성을 위한 GitHub 저장소.
- PrismAudio: 분해된 CoT와 다차원 보상을 활용한 비디오-오디오 생성 프로젝트 페이지.
- DreamOmni2: 오픈소스 멀티모달 지시 기반 이미지 편집 및 생성 프로젝트.
- PixelRefer: 세밀한 이미지 및 비디오 객체 이해를 위한 Alibaba DAMO Academy의 프레임워크.
- Unlimited-OCR: Baidu의 장기 범위 OCR 및 문서 파싱 프로젝트.
- EdgeTAM: 프롬프트 기반 이미지 및 비디오 세그멘테이션을 위한 Meta의 온디바이스 트랙 애니싱 모델.
- Step-Audio-EditX: 제로샷 음성 복제와 표현력 있는 오디오 편집을 위한 StepFun의 모델.
- Nemotron 3.5 ASR Streaming 0.6B: 저지연 스트리밍 ASR을 위한 NVIDIA의 Hugging Face 모델 페이지.
관련 링크
- BAAI Hub 원문 기사: 이번 주 HyperAI 업데이트의 출처 기사.
- HyperAI 공식 웹사이트: HyperAI 튜토리얼, 논문, 데이터셋, AI 리소스를 제공하는 메인 포털.
- HyperAI Wiki: 일반 개념과 연구 용어를 다루는 AI 백과사전 포털.
- HyperAI Conference Tracker: AI 및 컴퓨터 과학 학회 마감일 추적 도구.
- Meta SAM-Audio 연구 페이지: Segment Anything Model Audio의 공식 연구 페이지.
- arXiv의 SAM-Audio 논문: SAM-Audio 파운데이션 모델을 설명하는 연구 논문.
- arXiv의 MatAnyone 2 논문: MatAnyone 2와 학습 기반 매팅 품질 평가기에 관한 논문.
- arXiv의 Unlimited-OCR 논문: Unlimited OCR 및 장기 범위 파싱에 대한 기술 보고서.
요약
이번 주 업데이트는 오디오 생성, 음성 인식, 비디오 처리, 이미지 이해, 장문 문서 OCR을 중심으로 새로운 AI 데모와 모델 리소스를 유용하게 모아 소개합니다.
가장 실용적인 항목으로는 일본어 음성 생성을 위한 Irodori-TTS, 프롬프트 기반 사운드 분리를 위한 SAM-Audio, 깔끔한 비디오 매팅을 위한 MatAnyone 2, 장문 문서를 위한 Unlimited-OCR, 스트리밍 음성 인식을 위한 Nemotron 3.5 ASR이 있습니다.
전반적으로 이 모음은 어떤 새로운 AI 모델을 테스트해 볼 가치가 있는지, 각 모델이 무엇을 하는지, 어디에서 사용해 볼 수 있는지 빠르게 파악하려는 독자에게 유용합니다.