Mise à jour hebdomadaire des modèles d’IA HyperAI : Irodori-TTS, SAM-Audio, MatAnyone 2, PrismAudio, et plus encore
Cette mise à jour hebdomadaire rassemble une sélection utile de nouvelles démos d’IA et de ressources de modèles, en particulier autour de la génération audio, de la reconnaissance vocale, du traitement vidéo, de la compréhension d’images et de l’OCR pour documents longs. Les entrées les plus pratiques sont Irodori-TTS pour la génération de voix en japonais, SAM-Audio pour la séparation sonore à partir de prompts, MatAnyone 2 pour un détourage vidéo propre, Unlimited-OCR pour les documents longs, et Nemotron 3.5 ASR pour la reconnaissance vocale en streaming. **Dans l’ensemble, cette sélection est utile aux lecteurs qui souhaitent découvrir rapidement quels nouveaux modèles d’IA valent la peine d’être testés, ce que chacun fait et où les essayer.**

Mise à jour hebdomadaire des modèles d’IA HyperAI : Irodori-TTS, SAM-Audio, MatAnyone 2, PrismAudio, et plus encore
Introduction
La mise à jour HyperAI de cette semaine met l’accent sur un ensemble solide de modèles couvrant l’audio, la vidéo, la compréhension d’images, l’OCR et la reconnaissance vocale. Le projet phare est Irodori-TTS-500M-v3, un modèle ouvert de synthèse vocale japonaise qui combine une génération vocale haute fidélité à 48 kHz, le clonage vocal zero-shot et un contrôle stylistique précis grâce à des annotations par emoji.
La mise à jour inclut également des outils de séparation audio guidée par prompt, de matting vidéo, de simulation de monde 4D, de génération audio à partir de vidéo, d’OCR de documents, de segmentation sur appareil, d’édition audio expressive et d’ASR en streaming à faible latence. Vous trouverez ci-dessous une version remaniée et prête à être publiée du tour d’horizon hebdomadaire original, avec les captures d’écran utiles conservées dans leur contexte d’origine.
Note sur la source
Cet article est basé sur la mise à jour hebdomadaire BAAI Hub / HyperAI publiée sur le site. La page originale indique que la source de l’article provient de WeChat et que les images peuvent être retirées en cas de préoccupations liées aux droits d’auteur.
Les codes QR, affiches promotionnelles, images d’invitation à des groupes et bannières de recommandations sans rapport ont été volontairement supprimés. Les liens d’images DiaMoE-TTS et DreamOmni2 sont conservés à leurs emplacements d’origine, mais leurs demandes de prévisualisation ont expiré lors de la vérification ; ils sont donc mentionnés ici au lieu d’être considérés comme des captures d’écran entièrement vérifiées.
Aperçu de la mise à jour hebdomadaire HyperAI
Du 27 juin au 3 juillet, HyperAI a mis à jour plusieurs ressources publiques sur son site officiel :
- 12 tutoriels publics sélectionnés
- 5 entrées populaires de l’encyclopédie IA
- 4 échéances de conférences IA en juillet
Le thème principal de cette semaine est l’expérimentation pratique. La plupart des entrées ne se limitent pas à des descriptions d’articles scientifiques ; elles proposent des démonstrations en ligne ou des notebooks exécutables afin que les utilisateurs puissent tester rapidement le comportement des modèles.
Tutoriels publics sélectionnés
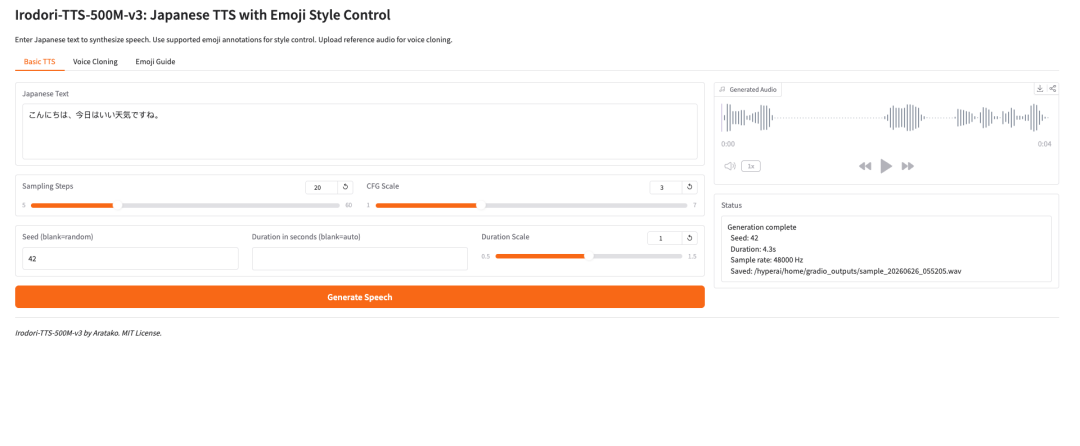
1. Irodori-TTS-500M-v3 : TTS japonais avec contrôle du style par emoji
Irodori-TTS est un projet open source de synthèse vocale japonaise publié par le développeur Aratako en 2026. Le modèle présenté, Irodori-TTS-500M-v3, est conçu pour la synthèse vocale en japonais, le clonage vocal zero-shot et le contrôle du style vocal guidé par emoji.
Le modèle repose sur une architecture Rectified Flow Diffusion Transformer (RF-DiT) et génère la parole dans un espace latent DACVAE continu. En usage pratique, son aspect le plus intéressant est qu’il peut cloner une voix cible à partir d’un court extrait de référence, généralement d’environ 3 à 10 secondes, sans affinage supplémentaire.
Il prend également en charge le contrôle du style via des annotations par emoji. Cela rend le modèle plus flexible qu’un système TTS de base : les utilisateurs peuvent guider le ton, l’émotion, le rythme et de subtiles expressions non verbales de manière plus légère.
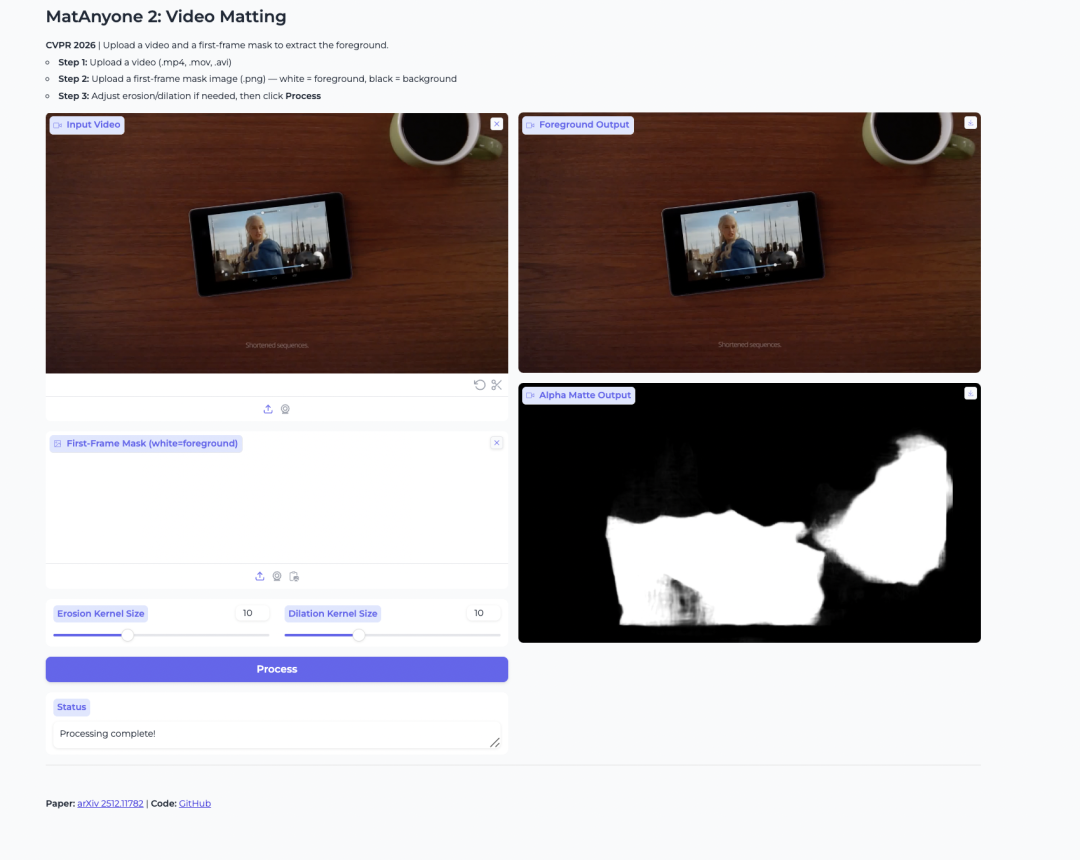
2. MatAnyone 2 : matting vidéo pour l’extraction de premier plan
MatAnyone 2 est un modèle de matting vidéo publié par NTU S-Lab et SenseTime. Il est conçu pour extraire des premiers plans humains et générer des mattes alpha à partir de vidéos.
Le modèle améliore la stabilité grâce à un évaluateur de qualité appris. Cela permet de réduire les artefacts de bord et de préserver des détails tels que les cheveux, les contours semi-transparents et les limites du premier plan. Il est également utile lorsque l’utilisateur souhaite isoler une personne spécifique dans une vidéo comprenant plusieurs personnes.
Démo en ligne :
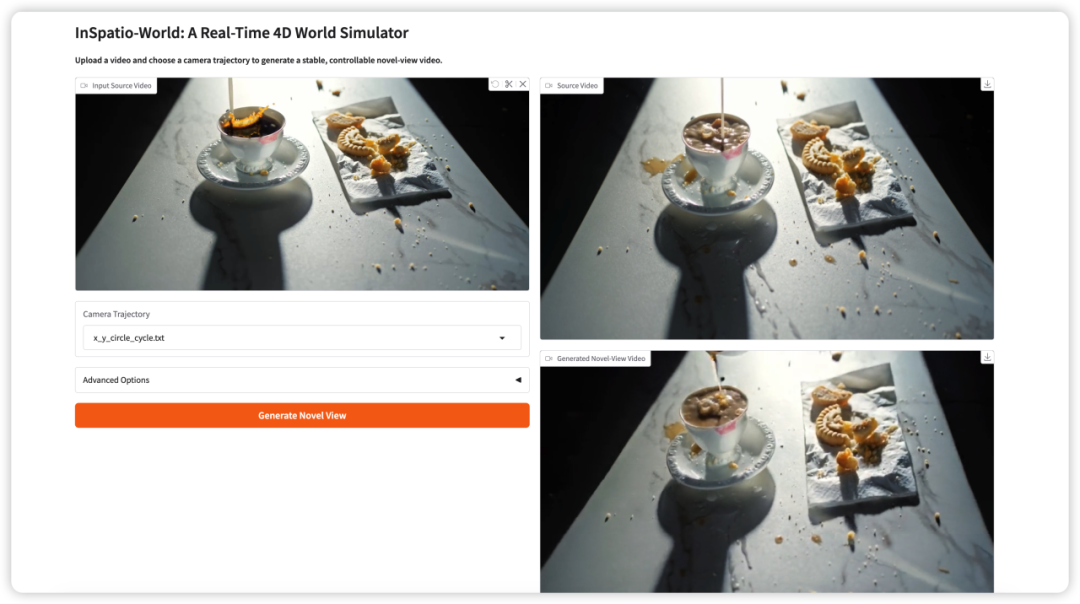
3. InSpatio-World : simulation de monde 4D en temps réel
InSpatio-World est un simulateur de monde 4D en temps réel publié par l’équipe InSpatio en 2026. Il peut prendre une vidéo d’entrée et une trajectoire de caméra spécifiée, puis générer une vidéo stable depuis un nouveau point de vue.
L’idée centrale est de rendre les scènes vidéo plus contrôlables. Au lieu de regarder passivement une vue de caméra fixe, les utilisateurs peuvent définir le mouvement de la caméra et explorer la scène depuis de nouveaux points de vue tout en préservant la cohérence temporelle.
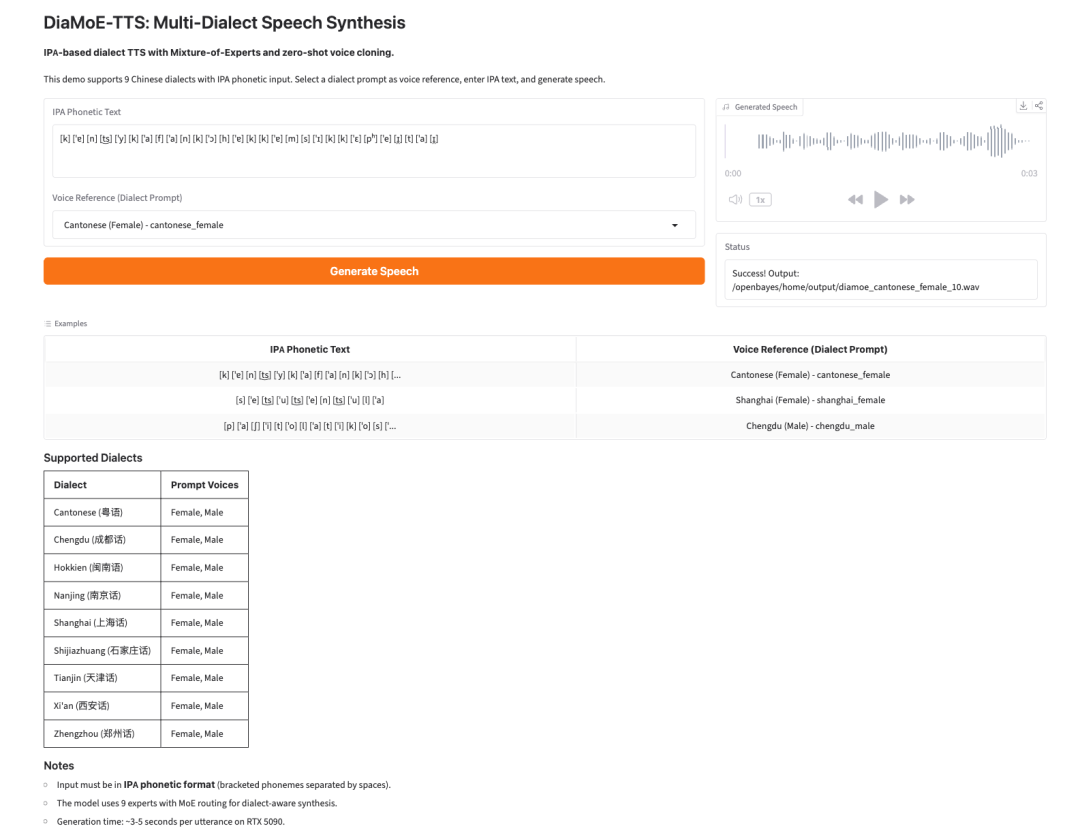
4. DiaMoE-TTS : synthèse vocale multi-dialectale basée sur l’API
DiaMoE-TTS est un cadre de synthèse vocale multi-dialectale développé par Giant AI Lab. Il utilise l’alphabet phonétique international, ou API, comme interface frontale unifiée pour la génération de parole dialectale.
Le modèle combine une conception Mixture-of-Experts avec des méthodes d’adaptation efficaces en paramètres, telles que LoRA et les adaptateurs de conditionnement. Cela permet au système de s’adapter plus rapidement à de nouveaux dialectes, même lorsque seules des données limitées sont disponibles.
{kind=link}
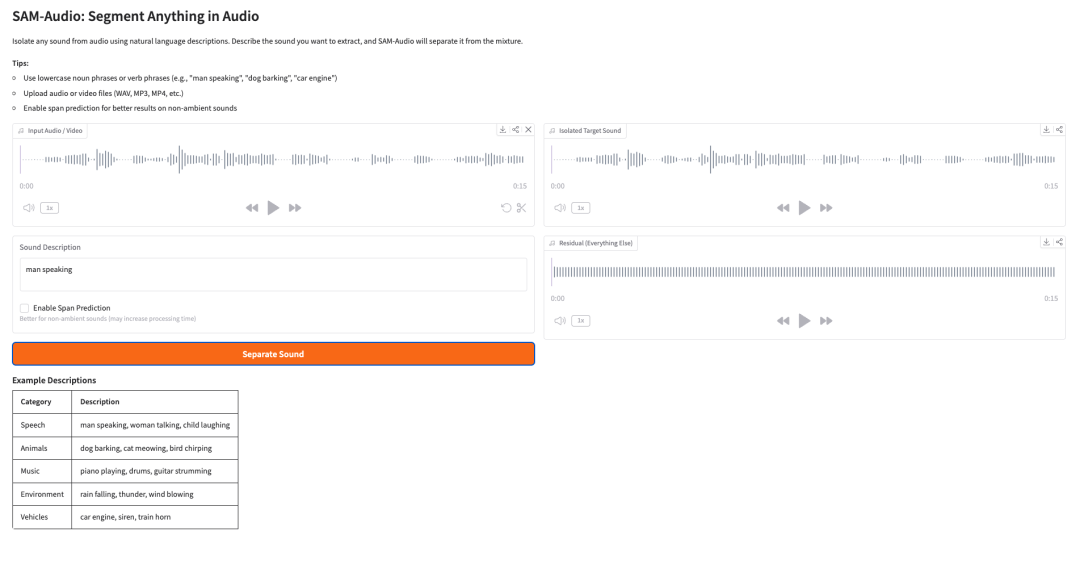
5. SAM-Audio : segmenter n’importe quoi dans l’audio
SAM-Audio est le modèle fondation de séparation de sources audio de Meta. Il peut isoler un son cible à partir d’un signal audio mixte au moyen de descriptions en langage naturel, d’indices visuels issus d’une vidéo ou d’un intervalle temporel sélectionné.
Par exemple, un utilisateur peut décrire le son qu’il souhaite séparer, comme « homme qui parle », « chien qui aboie », « moteur de voiture » ou « piano qui joue ». Le modèle tente ensuite de séparer l’audio cible de tout le reste du mélange.
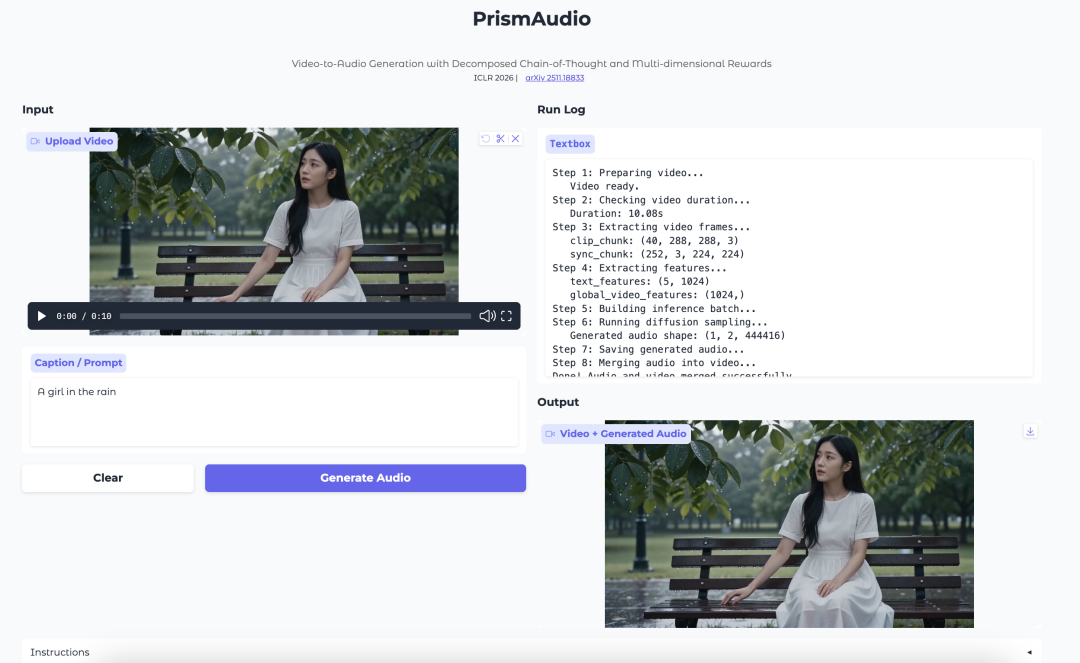
6. PrismAudio : génération audio à partir de vidéo avec CoT décomposée et récompenses multidimensionnelles
PrismAudio est un modèle de génération audio à partir de vidéo développé par Tongyi Lab. Il vise à générer un audio correspondant à la scène visuelle, au timing, à l’atmosphère et à la sensation spatiale d’une vidéo.
Le modèle introduit un processus de planification de type chaîne de pensée décomposée. Au lieu de traiter la génération audio à partir de vidéo comme une seule étape de raisonnement, il sépare le processus en dimensions sémantique, temporelle, esthétique et spatiale. Chaque dimension est associée à un signal de récompense ciblé pour l’apprentissage par renforcement.
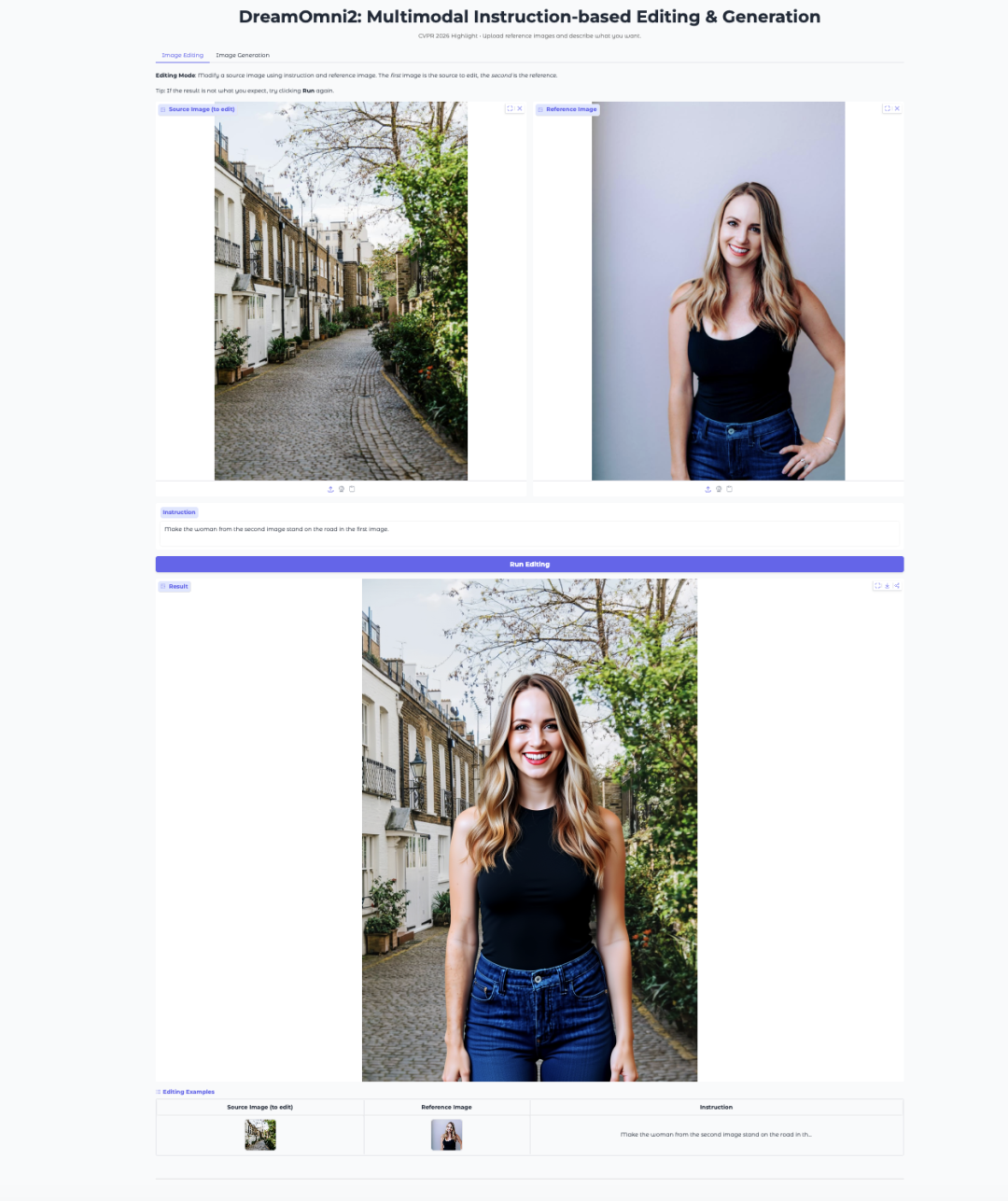
7. DreamOmni2 : édition et génération d’images multimodales fondées sur des instructions
DreamOmni2 est un modèle multimodal d’édition et de génération d’images développé par CUHK JIA Lab. Il a été accepté à la CVPR 2026 en tant qu’article Highlight.
Le modèle est construit sur FLUX.1-Kontext-dev et utilise un modèle vision-langage Qwen2.5-VL-7B affiné pour traiter les instructions. Il prend en charge les prompts en langage naturel associés à des images de référence, ce qui le rend adapté à des tâches telles que le remplacement d’objets, le transfert de style, l’imitation de pose et la génération guidée par des concepts.
8. PixelRefer : compréhension fine des objets pour les images et les vidéos
PixelRefer est un cadre unifié de compréhension d’objets dans les images et les vidéos développé par Alibaba DAMO Academy. Il se concentre sur une compréhension fine centrée sur les objets, plutôt que sur la simple description d’une scène entière.
Le cadre prend en charge le pointage au niveau des régions, le captioning et la réponse aux questions. Il introduit également un tokenizer d’objets adaptatif à l’échelle, ainsi qu’une variante plus légère, PixelRefer-Lite, afin de rendre la représentation des objets plus compacte et plus efficace.

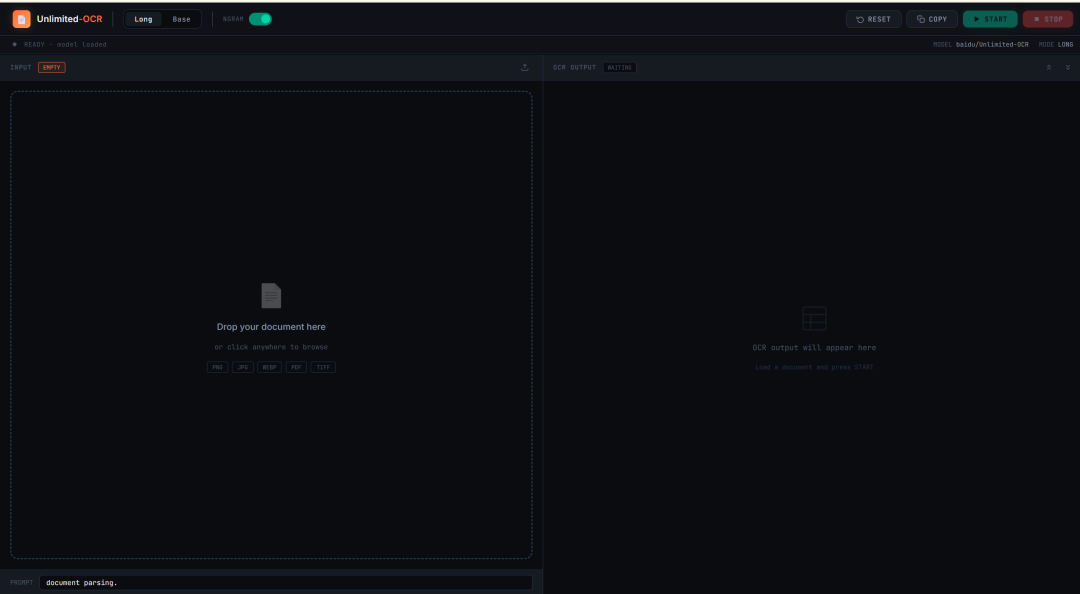
9. Unlimited-OCR : OCR et analyse de mise en page de longs documents en une seule passe
Unlimited-OCR est un projet d’OCR et d’analyse de mise en page de documents publié par Baidu en 2026. Il est conçu pour l’analyse de longs documents, et non uniquement pour la reconnaissance de pages isolées.
Le projet peut traiter des images de documents uniques, des images multipages et des pages converties à partir de PDF. Il est particulièrement utile pour les articles scientifiques, les rapports, les documents numérisés, les longs tableaux et les documents structurés multipages.
10. EdgeTAM : segmentation d’images et de vidéos pilotable par prompts pour appareils en périphérie
EdgeTAM est un modèle embarqué Track Anything développé par Meta Reality Labs et NTU S-Lab. Il est conçu pour les appareils aux ressources limitées tout en conservant la capacité de segmentation interactive des modèles de type SAM.
Le modèle réduit le goulot d’étranglement de l’attention mémoire de SAM 2 grâce à un Perceiver spatial 2D et à un pipeline de distillation. En pratique, cela signifie qu’il peut prendre en charge une segmentation pilotable par prompts.
la segmentation et le suivi d’objets vidéo plus efficacement sur du matériel en périphérie.

11. Step-Audio-EditX : clonage vocal zero-shot et édition audio expressive
Step-Audio-EditX est un modèle d’édition audio de StepFun. Il combine un modèle audio basé sur un LLM de 3 milliards de paramètres avec l’apprentissage par renforcement afin de prendre en charge le clonage vocal zero-shot et l’édition audio expressive.
Le modèle peut gérer le mandarin, l’anglais, le sichuanais, le cantonais, le japonais et le coréen. Il est conçu pour des tâches telles que le contrôle des émotions, l’édition du style de parole, l’édition paralinguistique et l’amélioration audio itérative.

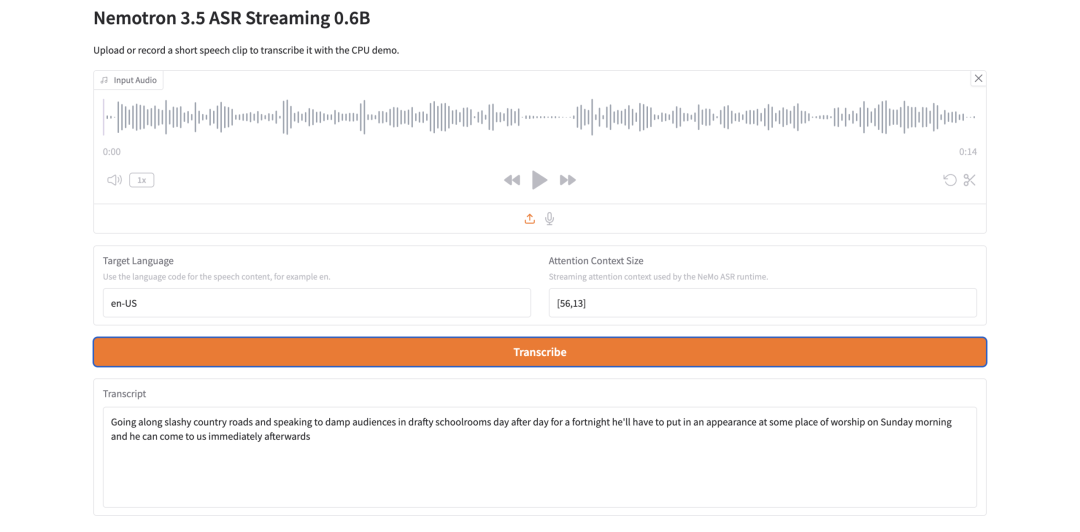
12. Nemotron 3.5 ASR Streaming 0.6B : reconnaissance vocale en streaming légère
Nemotron 3.5 ASR Streaming 0.6B est un modèle de reconnaissance automatique de la parole développé par NVIDIA. Il est conçu pour la transcription en streaming à faible latence et utilise une architecture FastConformer-RNNT sensible au cache.
Le principe clé de sa conception est la réutilisation du contexte. Lors de l’inférence en streaming, le modèle réutilise le contexte de l’encodeur au lieu de recalculer les segments audio qui se chevauchent, ce qui permet de réduire les calculs redondants et d’améliorer les performances en temps réel.
Entrées encyclopédiques populaires
HyperAI a également mis en avant cinq entrées populaires de son encyclopédie de l’IA cette semaine :
- Grand modèle de langage (LLM)
- Modèle d’action du monde (WAM)
- Moyenne harmonique
- Criblage virtuel
- Apprentissage par renforcement à partir de retours d’IA (RLAIF)
Le wiki de HyperAI rassemble des centaines de concepts et d’explications liés à l’IA. Il est utile aux lecteurs qui souhaitent comprendre rapidement des termes apparaissant souvent dans les articles scientifiques, les tutoriels et la documentation des modèles.
Dates limites des conférences IA en juillet
La mise à jour originale répertorie également plusieurs dates limites de conférences en IA et en informatique en juillet. Toutes les heures limites sont indiquées en heure AoE.
| Date | Heure | Conférence |
|---|---|---|
| 09 juillet | 23:59:59 | POPL 2027 |
| 10 juillet | 23:59:59 | ICSE 2027 |
| 17 juillet | 23:59:59 | SIGMOD 2027 |
| 28 juillet | 23:59:59 | AAAI 2027 |
À propos de HyperAI
HyperAI est une communauté dédiée à l’intelligence artificielle et au calcul haute performance. Son site web fournit des ressources publiques aux développeurs, chercheurs et apprenants en IA.
Selon la source originale, HyperAI a déjà rassemblé ou pris en charge :
- plus de 2 100 jeux de données publics avec des nœuds d’accélération nationaux
- plus de 700 tutoriels en ligne classiques et populaires
- plus de 300 études de cas d’articles AI4Science
- plus de 700 entrées encyclopédiques liées à l’IA
- un miroir complet de la documentation chinoise d’Apache TVM
FAQ
Qu’est-ce qu’Irodori-TTS-500M-v3 ?
Irodori-TTS-500M-v3 est un modèle ouvert de synthèse vocale japonaise basé sur une architecture RF-DiT. Il prend en charge la génération de parole en japonais, le clonage vocal zero-shot avec une courte référence et le contrôle du style au moyen d’émojis.
Irodori-TTS peut-il cloner une voix sans ajustement fin ?
Oui. La mise à jour originale décrit Irodori-TTS comme prenant en charge le clonage vocal zero-shot à partir d’un court extrait audio de référence, généralement d’environ 3 à 10 secondes. Le résultat dépend toutefois de la qualité et de la clarté de l’audio de référence.
À quoi sert SAM-Audio ?
SAM-Audio sert à la séparation de sources audio guidée par des prompts. Les utilisateurs peuvent décrire le son qu’ils souhaitent extraire, fournir des indices visuels ou spécifier une plage temporelle afin d’isoler un son cible dans un enregistrement mixte.
Quelle est la différence entre le matting vidéo et la segmentation vidéo ?
La segmentation vidéo sépare généralement les objets en régions ou en masques, tandis que le matting vidéo estime un cache alpha plus détaillé. Le matting est particulièrement important pour une extraction propre du premier plan, les détails des cheveux, les bords semi-transparents et la composition.
Que génère PrismAudio ?
PrismAudio génère de l’audio pour la vidéo. Il cherche à aligner le son généré avec le contenu sémantique de la vidéo, son rythme, son ressenti esthétique et ses indices spatiaux.
Pourquoi Unlimited-OCR est-il utile pour les documents longs ?
Unlimited-OCR est conçu pour l’analyse à long horizon, et pas seulement pour l’OCR de pages isolées. Il peut être utile pour traiter des articles, rapports, fichiers numérisés, longs tableaux ou images dérivées de PDF multipages.
Nemotron 3.5 ASR Streaming 0.6B convient-il à la transcription vocale en temps réel ?
Oui, il est conçu pour la transcription vocale à faible latence.
ASR en streaming. Son architecture FastConformer-RNNT sensible au cache réutilise le contexte lors de l’inférence en streaming, ce qui contribue à réduire les calculs redondants.
Outils associés
- Irodori-TTS : TTS japonais open source avec clonage vocal à partir d’un audio de référence et contrôle du style.
- Irodori-TTS-500M-v3 sur Hugging Face : page du modèle pour le point de contrôle TTS japonais 500M v3.
- SAM-Audio : dépôt de Meta pour l’inférence et les exemples de Segment Anything in Audio.
- MatAnyone 2 : page du projet du framework de détourage vidéo MatAnyone 2.
- InSpatio-World : page du projet de simulation interactive en temps réel de mondes 4D.
- DiaMoE-TTS : dépôt GitHub pour la synthèse vocale multidialectale basée sur l’API.
- PrismAudio : page du projet de génération audio à partir de vidéo avec CoT décomposé et récompenses multidimensionnelles.
- DreamOmni2 : projet open source multimodal d’édition et de génération d’images à partir d’instructions.
- PixelRefer : framework de l’Alibaba DAMO Academy pour la compréhension fine des objets dans les images et les vidéos.
- Unlimited-OCR : projet de Baidu pour l’OCR à long contexte et l’analyse de documents.
- EdgeTAM : modèle embarqué de Meta pour le suivi universel d’objets et la segmentation d’images et de vidéos guidée par invite.
- Step-Audio-EditX : modèle de StepFun pour le clonage vocal zero-shot et l’édition audio expressive.
- Nemotron 3.5 ASR Streaming 0.6B : page du modèle Hugging Face de NVIDIA pour l’ASR en streaming à faible latence.
Liens associés
- Article original du BAAI Hub : article source de cette mise à jour hebdomadaire HyperAI.
- Site officiel HyperAI : portail principal des tutoriels, articles, jeux de données et ressources IA d’HyperAI.
- Wiki HyperAI : portail encyclopédique sur l’IA couvrant les concepts courants et les termes de recherche.
- Suivi des conférences HyperAI : outil de suivi des échéances des conférences en IA et en informatique.
- Page de recherche Meta SAM-Audio : page de recherche officielle pour Segment Anything Model Audio.
- Article SAM-Audio sur arXiv : article de recherche décrivant le modèle de fondation SAM-Audio.
- Article MatAnyone 2 sur arXiv : article sur MatAnyone 2 et son évaluateur appris de la qualité du détourage.
- Article Unlimited-OCR sur arXiv : rapport technique sur Unlimited OCR et l’analyse à long contexte.
Résumé
Cette mise à jour hebdomadaire rassemble un ensemble utile de nouvelles démos IA et de ressources de modèles, en particulier autour de la génération audio, de la reconnaissance vocale, du traitement vidéo, de la compréhension d’images et de l’OCR de documents longs.
Les entrées les plus pratiques sont Irodori-TTS pour la génération de voix japonaise, SAM-Audio pour la séparation sonore basée sur des invites, MatAnyone 2 pour un détourage vidéo propre, Unlimited-OCR pour les documents longs, et Nemotron 3.5 ASR pour la reconnaissance vocale en streaming.
Dans l’ensemble, cette sélection est utile aux lecteurs qui souhaitent découvrir rapidement quels nouveaux modèles d’IA valent la peine d’être testés, ce que chacun fait et où les essayer.