Actualización semanal de modelos de IA de HyperAI: Irodori-TTS, SAM-Audio, MatAnyone 2, PrismAudio y más
Esta actualización semanal reúne un conjunto útil de nuevas demostraciones y recursos de modelos de IA, especialmente en torno a la generación de audio, el reconocimiento de voz, el procesamiento de vídeo, la comprensión de imágenes y el OCR para documentos largos. Las entradas más prácticas son Irodori-TTS para la generación de voz en japonés, SAM-Audio para la separación de sonidos basada en prompts, MatAnyone 2 para un matting de vídeo limpio, Unlimited-OCR para documentos largos y Nemotron 3.5 ASR para el reconocimiento de voz en streaming. **En general, este resumen es útil para los lectores que desean descubrir rápidamente qué nuevos modelos de IA vale la pena probar, qué hace cada uno y dónde probarlos.**

Actualización semanal de modelos de IA de HyperAI: Irodori-TTS, SAM-Audio, MatAnyone 2, PrismAudio y más
Introducción
La actualización de HyperAI de esta semana se centra en una potente combinación de modelos de audio, video, comprensión de imágenes, OCR y reconocimiento de voz. El proyecto destacado es Irodori-TTS-500M-v3, un modelo abierto de texto a voz en japonés que combina generación de voz de alta fidelidad a 48 kHz, clonación de voz zero-shot y control de estilo detallado mediante anotaciones con emojis.
La actualización también incluye herramientas para separación de audio basada en prompts, matting de video, simulación de mundos 4D, generación de audio a partir de video, OCR de documentos, segmentación en el dispositivo, edición expresiva de audio y ASR en streaming de baja latencia. A continuación se presenta una versión depurada y lista para publicación del resumen semanal original, con las capturas de pantalla útiles conservadas en su contexto original.
Nota sobre la fuente
Este artículo se basa en la actualización semanal de BAAI Hub / HyperAI publicada en La página original indica que la fuente del artículo proviene de WeChat y que las imágenes pueden eliminarse si existen preocupaciones de derechos de autor.
Se eliminaron intencionalmente códigos QR, carteles promocionales, imágenes de invitación a grupos y banners de recomendaciones no relacionados. Los enlaces de imágenes de DiaMoE-TTS y DreamOmni2 se mantienen en sus posiciones originales, pero sus solicitudes de vista previa agotaron el tiempo de espera durante la verificación, por lo que se mencionan aquí en lugar de tratarse como capturas de pantalla plenamente verificadas.
Resumen de la actualización semanal de HyperAI
Del 27 de junio al 3 de julio, HyperAI actualizó varios recursos públicos en su sitio web oficial:
- 12 tutoriales públicos seleccionados
- 5 entradas populares de la enciclopedia de IA
- 4 fechas límite de conferencias de IA en julio
El tema principal de esta semana es la experimentación práctica. La mayoría de las entradas no son solo descripciones de artículos académicos; ofrecen demos en línea o notebooks ejecutables para que los usuarios puedan probar rápidamente el comportamiento de los modelos.
Tutoriales públicos seleccionados
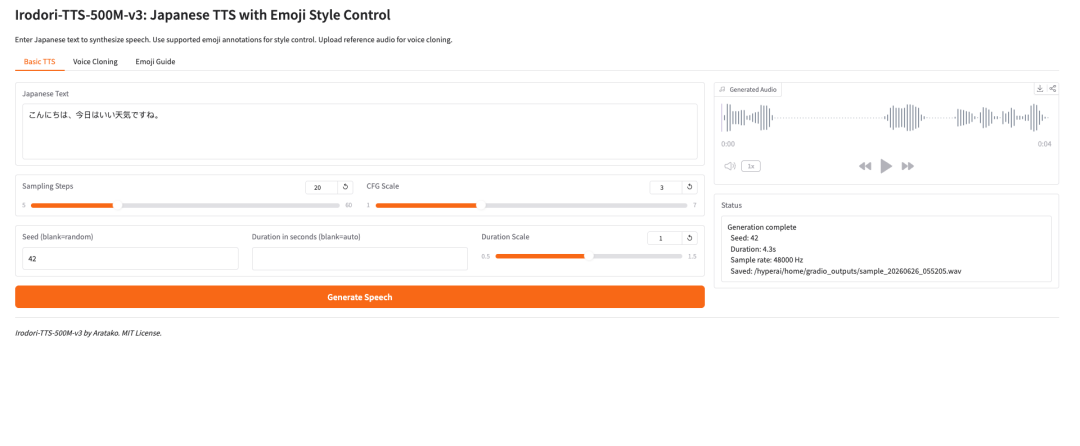
1. Irodori-TTS-500M-v3: TTS en japonés con control de estilo mediante emojis
Irodori-TTS es un proyecto de texto a voz en japonés de código abierto lanzado por el desarrollador Aratako en 2026. El modelo destacado, Irodori-TTS-500M-v3, está diseñado para síntesis de voz en japonés, clonación de voz zero-shot y control del estilo vocal guiado por emojis.
El modelo se basa en una arquitectura Rectified Flow Diffusion Transformer (RF-DiT) y genera voz en un espacio latente continuo DACVAE. En el uso práctico, el punto más interesante es que puede clonar una voz objetivo a partir de un breve clip de referencia, normalmente de alrededor de 3 a 10 segundos, sin ajuste fino adicional.
También admite control de estilo mediante anotaciones con emojis. Esto hace que el modelo sea más flexible que un sistema TTS básico: los usuarios pueden guiar el tono, la emoción, el ritmo y expresiones no verbales sutiles de una forma más ligera.
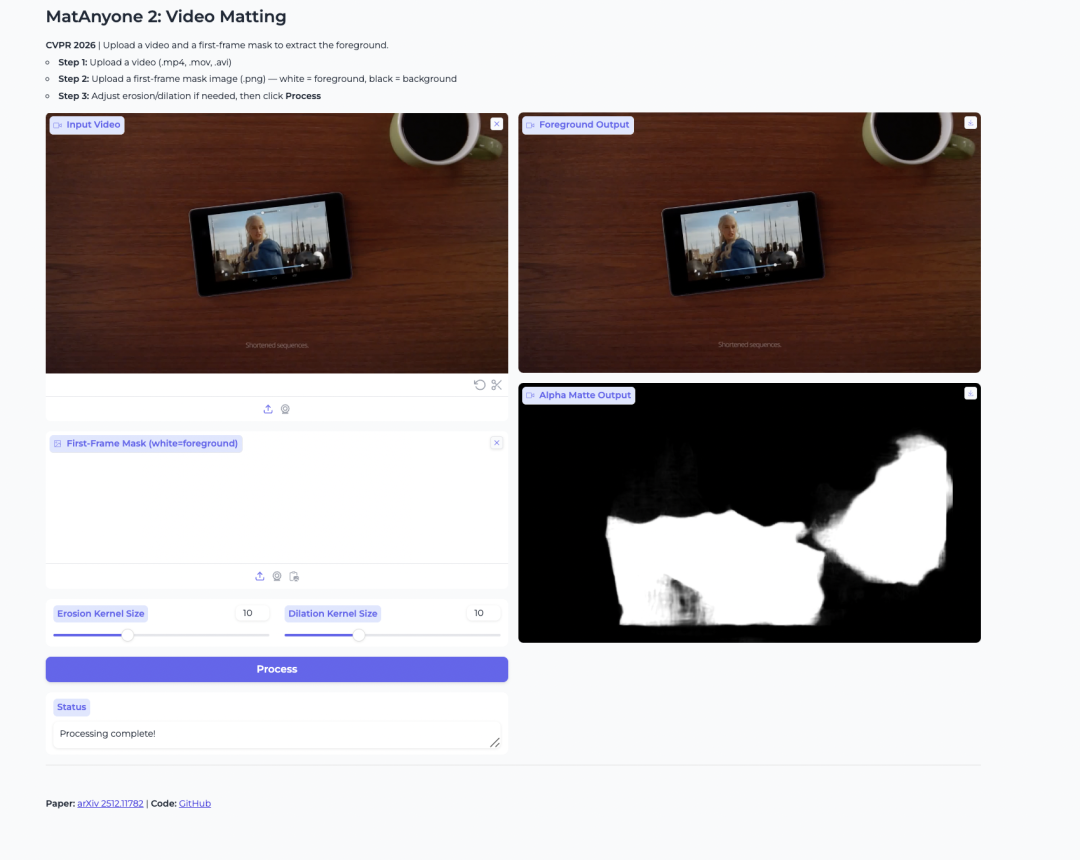
2. MatAnyone 2: matting de video para extracción de primer plano
MatAnyone 2 es un modelo de matting de video lanzado por NTU S-Lab y SenseTime. Está diseñado para extraer primeros planos humanos y generar mapas alfa a partir de videos.
El modelo mejora la estabilidad mediante un evaluador de calidad aprendido. Esto ayuda a reducir artefactos en los bordes y a preservar detalles como cabello, bordes semitransparentes y contornos del primer plano. También resulta útil cuando el usuario desea aislar a una persona específica en un video con varias personas.
Demo en línea:
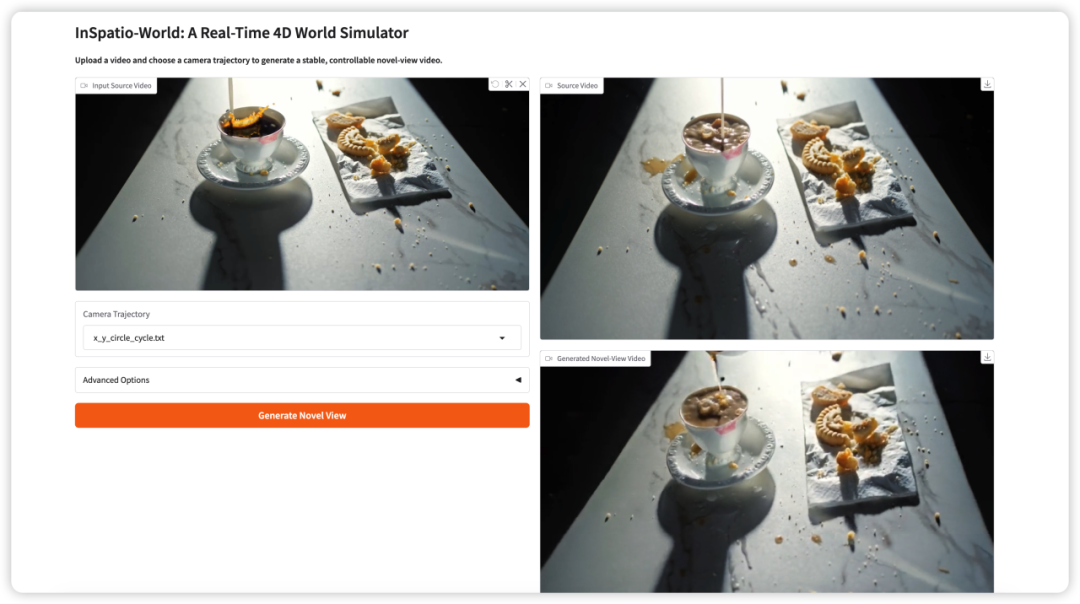
3. InSpatio-World: simulación de mundos 4D en tiempo real
InSpatio-World es un simulador de mundos 4D en tiempo real lanzado por el equipo de InSpatio en 2026. Puede tomar un video de entrada y una trayectoria de cámara especificada, y luego generar un video estable desde una nueva vista.
La idea central es hacer que las escenas de video sean más controlables. En lugar de observar pasivamente una vista de cámara fija, los usuarios pueden definir el movimiento de la cámara y explorar la escena desde nuevos puntos de vista, manteniendo la coherencia temporal.
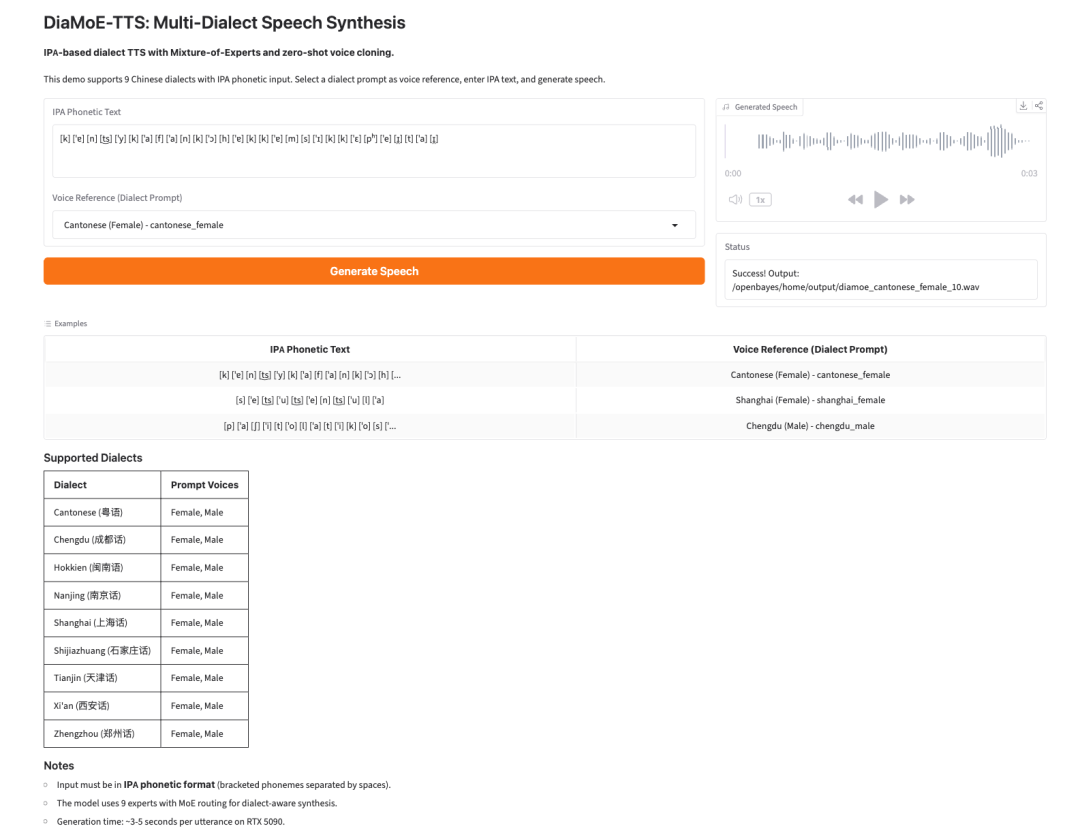
4. DiaMoE-TTS: síntesis de voz multidialectal basada en IPA
DiaMoE-TTS es un marco de síntesis de voz multidialectal de Giant AI Lab. Utiliza el Alfabeto Fonético Internacional, o IPA, como frontend unificado para la generación de habla dialectal.
El modelo combina un diseño Mixture-of-Experts con métodos de adaptación eficientes en parámetros, como LoRA y adaptadores de condicionamiento. Esto permite que el sistema se adapte con mayor rapidez a nuevos dialectos, incluso cuando solo hay datos limitados disponibles.
. En la parte inferior se enumeran los dialectos compatibles y sus audios de referencia correspondientes, además de información como el uso del modelo KPL para la síntesis dialectal y el tiempo de generación. La imagen está relacionada con el contenido del documento que presenta el modelo DiaMoE-TTS y muestra de forma intuitiva su interfaz de operación y sus funciones.](https://we0-cms.oss-cn-beijing.aliyuncs.com/cms-assets/image/2026/07/094c618c-2830-4af5-9cdc-ca950fe12565-05-c0ba34b2-8a4a-4e6a-9d15-517f152cb52a.png)
{kind=link}
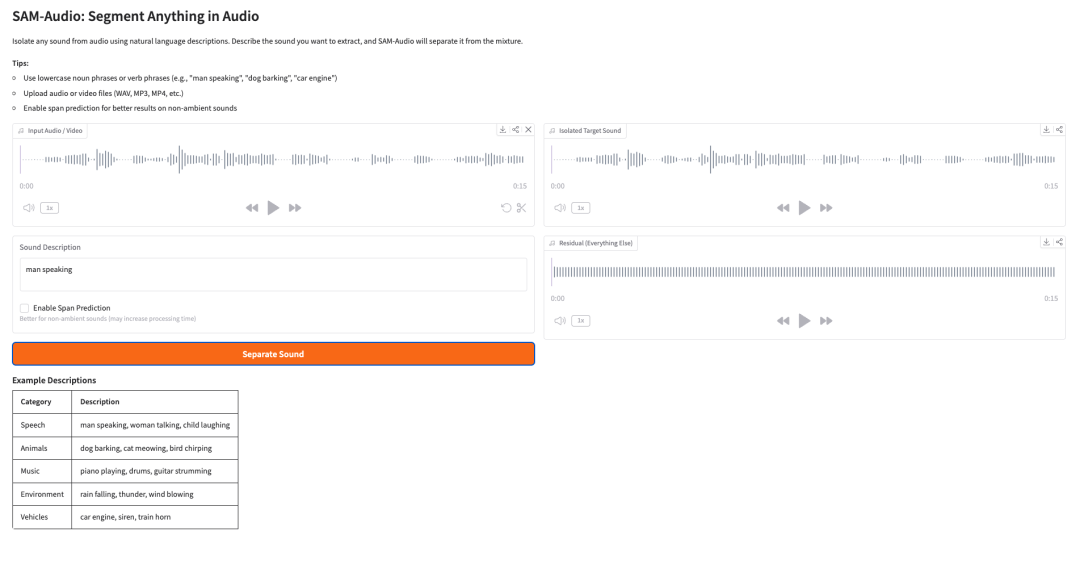
5. SAM-Audio: Segment Anything in Audio
SAM-Audio es el modelo fundacional de separación de fuentes de audio de Meta. Puede aislar un sonido objetivo de una señal de audio mezclada mediante descripciones en lenguaje natural, pistas visuales de un video o un intervalo de tiempo seleccionado.
Por ejemplo, un usuario puede describir el sonido que desea separar, como “hombre hablando”, “perro ladrando”, “motor de automóvil” o “piano tocando”. A continuación, el modelo intenta separar el audio objetivo de todo lo demás presente en la mezcla.
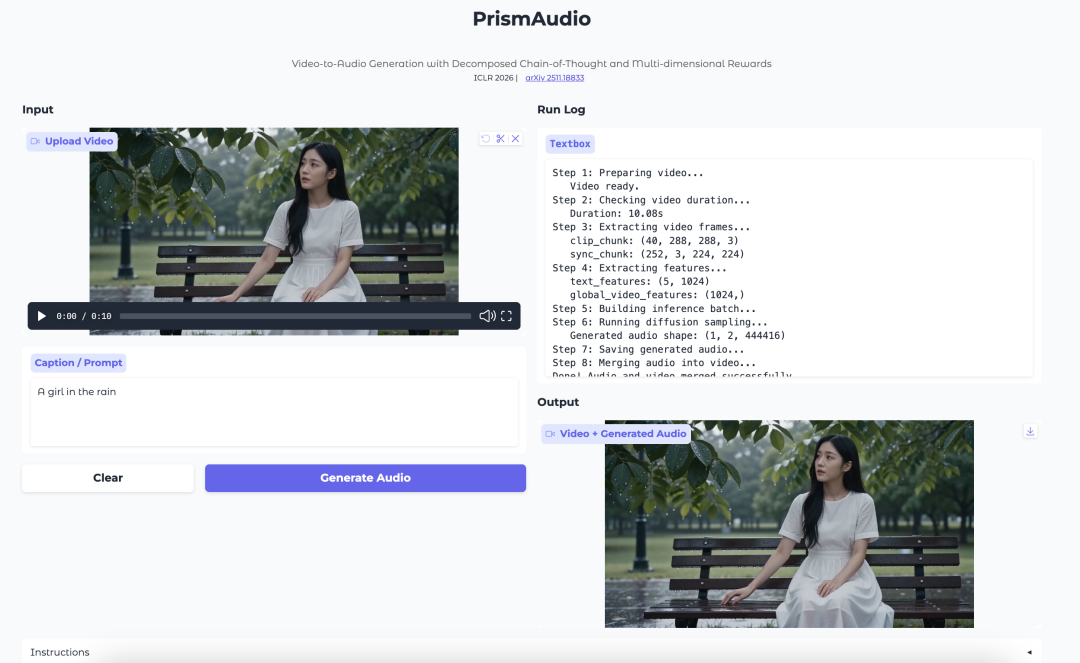
6. PrismAudio: generación de video a audio con CoT descompuesto y recompensas multidimensionales
PrismAudio es un modelo de generación de audio a partir de video desarrollado por Tongyi Lab. Se centra en generar audio que coincida con la escena visual, el ritmo, la atmósfera y la sensación espacial de un video.
El modelo introduce un proceso de planificación de Chain-of-Thought descompuesto. En lugar de tratar la generación de audio a partir de video como un único paso de razonamiento, separa el proceso en dimensiones semánticas, temporales, estéticas y espaciales. Cada dimensión se combina con una señal de recompensa específica para el aprendizaje por refuerzo.
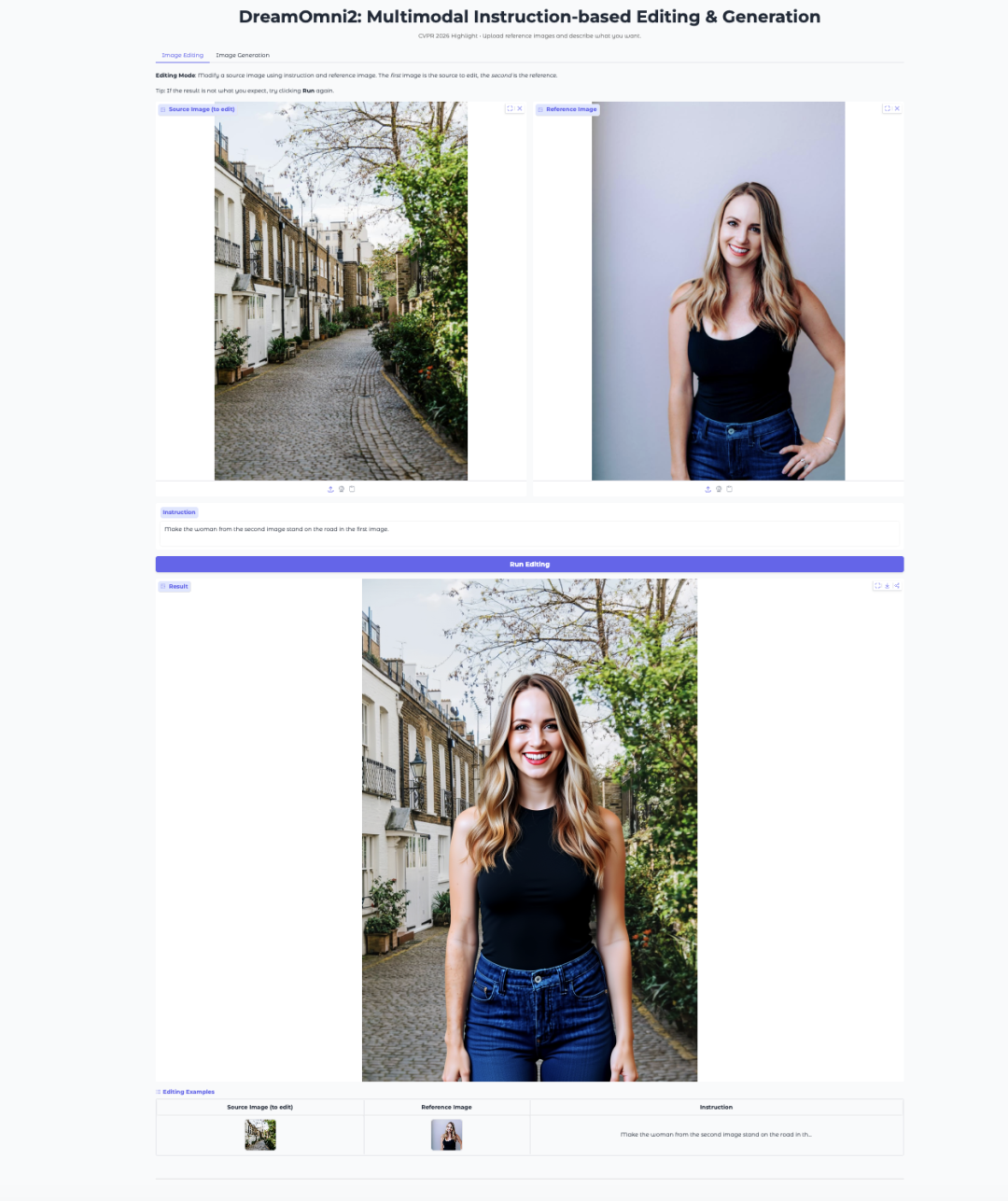
7. DreamOmni2: edición y generación de imágenes multimodal basada en instrucciones
DreamOmni2 es un modelo multimodal de edición y generación de imágenes desarrollado por CUHK JIA Lab. Ha sido aceptado por CVPR 2026 como artículo destacado.
El modelo se basa en FLUX.1-Kontext-dev y utiliza un modelo de lenguaje visual Qwen2.5-VL-7B ajustado finamente para procesar instrucciones. Admite prompts en lenguaje natural junto con imágenes de referencia, lo que lo hace adecuado para tareas como sustitución de objetos, transferencia de estilo, imitación de poses y generación guiada por conceptos.
8. PixelRefer: comprensión de objetos de grano fino para imágenes y videos
PixelRefer es un marco unificado de comprensión de objetos en imágenes y videos desarrollado por Alibaba DAMO Academy. Se centra en la comprensión detallada orientada a objetos, en lugar de limitarse a describir una escena completa.
El marco admite señalamiento a nivel de región, generación de descripciones y respuesta a preguntas. También introduce un tokenizador de objetos adaptativo a la escala y una variante más ligera, PixelRefer-Lite, para hacer que la representación de objetos sea más compacta y eficiente.

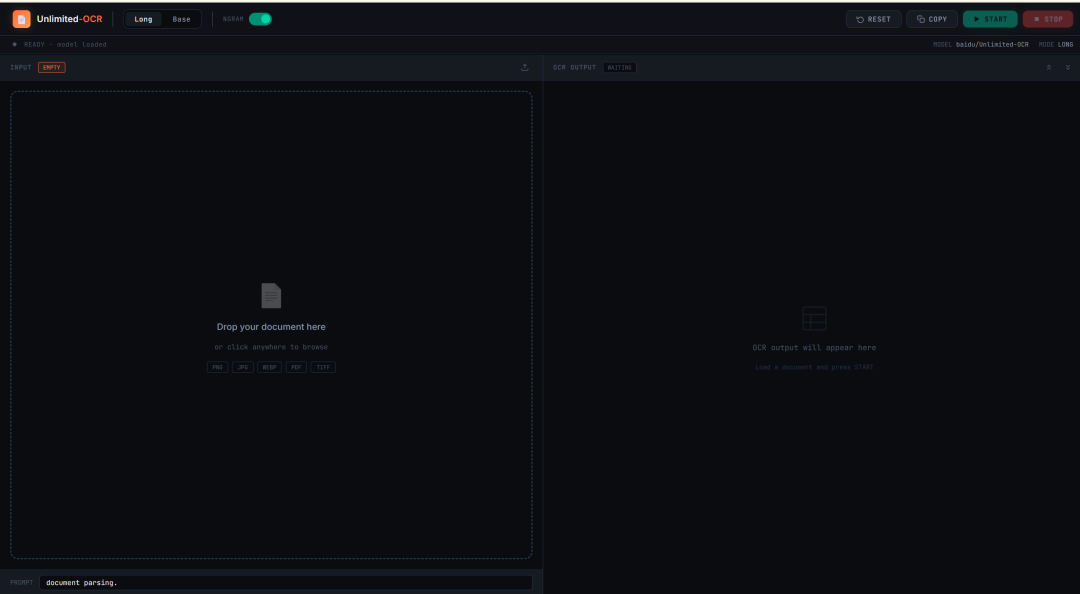
9. Unlimited-OCR: OCR de documentos largos en una sola pasada y análisis de diseño
Unlimited-OCR es un proyecto de OCR y análisis de diseño documental lanzado por Baidu en 2026. Está diseñado para el análisis de documentos largos, no solo para el reconocimiento de páginas individuales.
El proyecto puede procesar imágenes de documentos individuales, imágenes multipágina y páginas convertidas desde archivos PDF. Es especialmente útil para artículos académicos, informes, documentos escaneados, tablas largas y materiales estructurados de varias páginas.
10. EdgeTAM: segmentación de imágenes y videos con prompts para dispositivos edge
EdgeTAM es un modelo Track Anything ejecutable en el dispositivo desarrollado por Meta Reality Labs y NTU S-Lab. Está diseñado para dispositivos con recursos limitados, manteniendo al mismo tiempo la capacidad de segmentación interactiva de los modelos de estilo SAM.
El modelo reduce el cuello de botella de atención de memoria de SAM 2 mediante un 2D Spatial Perceiver y una canalización de destilación. En la práctica, esto significa que puede admitir una segmentación con prompts
segmentación y seguimiento de objetos en video de forma más eficiente en hardware de borde.

11. Step-Audio-EditX: clonación de voz zero-shot y edición de audio expresiva
Step-Audio-EditX es un modelo de edición de audio de StepFun. Combina un modelo de audio basado en un LLM de 3.000 millones de parámetros con aprendizaje por refuerzo para admitir clonación de voz zero-shot y edición de audio expresiva.
El modelo puede trabajar con mandarín, inglés, sichuanés, cantonés, japonés y coreano. Está diseñado para tareas como control emocional, edición del estilo de habla, edición paralingüística y refinamiento iterativo de audio.

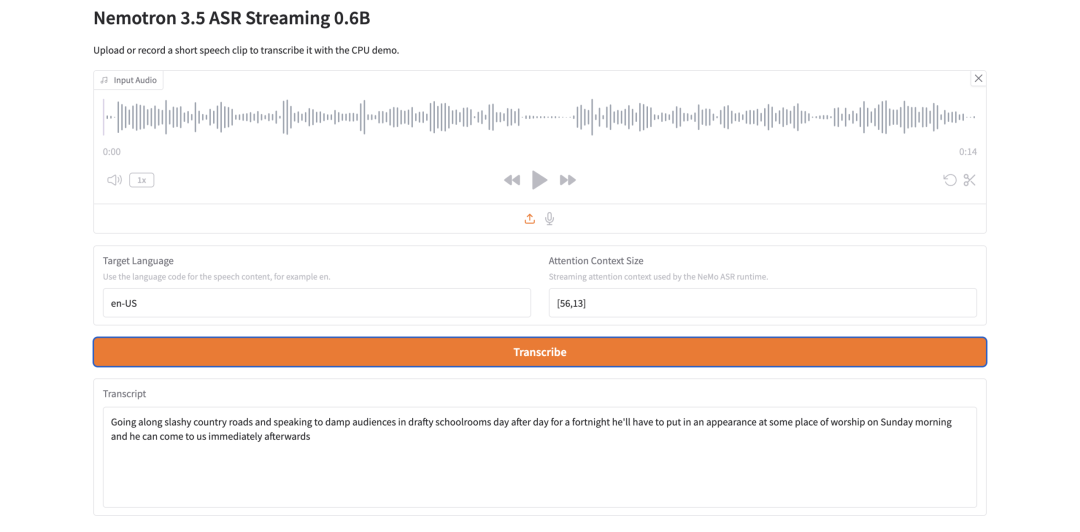
12. Nemotron 3.5 ASR Streaming 0.6B: reconocimiento de voz en streaming ligero
Nemotron 3.5 ASR Streaming 0.6B es un modelo de reconocimiento automático de voz de NVIDIA. Está diseñado para transcripción en streaming de baja latencia y utiliza una arquitectura FastConformer-RNNT consciente de la caché.
El diseño clave es la reutilización del contexto. Durante la inferencia en streaming, el modelo reutiliza el contexto del codificador en lugar de recalcular fragmentos de audio superpuestos, lo que ayuda a reducir el cálculo redundante y mejorar el rendimiento en tiempo real.
Entradas populares de la enciclopedia
HyperAI también destacó esta semana cinco entradas populares de su enciclopedia de IA:
- Modelo de lenguaje grande (LLM)
- Modelo de acción mundial (WAM)
- Media armónica
- Cribado virtual
- Aprendizaje por refuerzo a partir de retroalimentación de IA (RLAIF)
La wiki de HyperAI recopila cientos de conceptos y explicaciones relacionados con la IA. Es útil para lectores que desean una forma rápida de entender términos que aparecen con frecuencia en artículos, tutoriales y documentación de modelos.
Fechas límite de conferencias de IA en julio
La actualización original también enumera varias fechas límite de conferencias de IA e informática en julio. Todos los horarios de las fechas límite están marcados en hora AoE.
| Fecha | Hora | Conferencia |
|---|---|---|
| 09 de julio | 23:59:59 | POPL 2027 |
| 10 de julio | 23:59:59 | ICSE 2027 |
| 17 de julio | 23:59:59 | SIGMOD 2027 |
| 28 de julio | 23:59:59 | AAAI 2027 |
Acerca de HyperAI
HyperAI es una comunidad de inteligencia artificial y computación de alto rendimiento. Su sitio web ofrece recursos públicos para desarrolladores, investigadores y estudiantes de IA.
Según la fuente original, HyperAI ya ha recopilado o brindado soporte para:
- Más de 2.100 conjuntos de datos públicos con nodos de aceleración nacionales
- Más de 700 tutoriales en línea clásicos y populares
- Más de 300 estudios de caso de artículos de AI4Science
- Más de 700 entradas de enciclopedia relacionadas con la IA
- Un espejo completo de documentación en chino para Apache TVM
Preguntas frecuentes
¿Qué es Irodori-TTS-500M-v3?
Irodori-TTS-500M-v3 es un modelo abierto japonés de texto a voz basado en una arquitectura RF-DiT. Admite generación de voz en japonés, clonación de voz zero-shot con una referencia corta y control de estilo basado en emojis.
¿Puede Irodori-TTS clonar una voz sin ajuste fino?
Sí. La actualización original describe Irodori-TTS como compatible con clonación de voz zero-shot a partir de un breve fragmento de audio de referencia, normalmente de unos 3 a 10 segundos. El resultado sigue dependiendo de la calidad y claridad del audio de referencia.
¿Para qué se utiliza SAM-Audio?
SAM-Audio se utiliza para separación de fuentes de audio basada en prompts. Los usuarios pueden describir el sonido que desean extraer, proporcionar pistas visuales o especificar un intervalo de tiempo para aislar un sonido objetivo de una grabación mezclada.
¿Cuál es la diferencia entre matting de video y segmentación de video?
La segmentación de video suele separar objetos en regiones o máscaras, mientras que el matting de video estima un mapa alfa más detallado. El matting es especialmente importante para una extracción limpia del primer plano, detalles del cabello, bordes semitransparentes y composición.
¿Qué genera PrismAudio?
PrismAudio genera audio para video. Intenta alinear el sonido generado con el contenido semántico, el ritmo, la sensación estética y las pistas espaciales del video.
¿Por qué Unlimited-OCR es útil para documentos largos?
Unlimited-OCR está diseñado para análisis de largo alcance, no solo para OCR aislado de una sola página. Puede ser útil al trabajar con artículos, informes, archivos escaneados, tablas largas o imágenes derivadas de PDF de varias páginas.
¿Nemotron 3.5 ASR Streaming 0.6B es adecuado para la transcripción de voz en tiempo real?
Sí, está diseñado para transcripción de voz de baja latencia.
ASR en streaming. Su arquitectura FastConformer-RNNT con caché reutiliza el contexto durante la inferencia en streaming, lo que ayuda a reducir el cálculo redundante.
Herramientas relacionadas
- Irodori-TTS: TTS japonés de código abierto con clonación de voz mediante audio de referencia y control de estilo.
- Irodori-TTS-500M-v3 en Hugging Face: Página del modelo para el checkpoint de TTS japonés 500M v3.
- SAM-Audio: Repositorio de Meta para inferencia y ejemplos de Segment Anything in Audio.
- MatAnyone 2: Página del proyecto del framework de matting de vídeo MatAnyone 2.
- InSpatio-World: Página del proyecto para simulación interactiva en tiempo real de mundos 4D.
- DiaMoE-TTS: Repositorio de GitHub para síntesis de voz multidialectal basada en IPA.
- PrismAudio: Página del proyecto para generación de audio a partir de vídeo con CoT descompuesto y recompensas multidimensionales.
- DreamOmni2: Proyecto de código abierto para edición y generación de imágenes multimodal basada en instrucciones.
- PixelRefer: Framework de Alibaba DAMO Academy para la comprensión detallada de objetos en imágenes y vídeos.
- Unlimited-OCR: Proyecto de Baidu para OCR de largo alcance y análisis de documentos.
- EdgeTAM: Modelo de Meta para segmentación de imágenes y vídeos en el dispositivo, capaz de rastrear cualquier cosa mediante prompts.
- Step-Audio-EditX: Modelo de StepFun para clonación de voz zero-shot y edición de audio expresiva.
- Nemotron 3.5 ASR Streaming 0.6B: Página del modelo de NVIDIA en Hugging Face para ASR en streaming de baja latencia.
Enlaces relacionados
- Artículo original de BAAI Hub: Artículo fuente de esta actualización semanal de HyperAI.
- Sitio web oficial de HyperAI: Portal principal de tutoriales, artículos, conjuntos de datos y recursos de IA de HyperAI.
- HyperAI Wiki: Portal enciclopédico de IA que cubre conceptos comunes y términos de investigación.
- Rastreador de conferencias de HyperAI: Rastreador de fechas límite de conferencias de IA e informática.
- Página de investigación de Meta SAM-Audio: Página oficial de investigación de Segment Anything Model Audio.
- Artículo de SAM-Audio en arXiv: Artículo de investigación que describe el modelo fundacional SAM-Audio.
- Artículo de MatAnyone 2 en arXiv: Artículo sobre MatAnyone 2 y su evaluador aprendido de calidad de matting.
- Artículo de Unlimited-OCR en arXiv: Informe técnico sobre Unlimited OCR y análisis de largo alcance.
Resumen
Esta actualización semanal reúne un conjunto útil de nuevas demos de IA y recursos de modelos, especialmente en torno a la generación de audio, el reconocimiento de voz, el procesamiento de vídeo, la comprensión de imágenes y el OCR de documentos largos.
Las entradas más prácticas son Irodori-TTS para generación de voz en japonés, SAM-Audio para separación de sonido basada en prompts, MatAnyone 2 para matting de vídeo limpio, Unlimited-OCR para documentos largos y Nemotron 3.5 ASR para reconocimiento de voz en streaming.
En conjunto, este resumen es útil para lectores que quieren descubrir rápidamente qué nuevos modelos de IA vale la pena probar, qué hace cada uno y dónde probarlos.