HyperAI週間AIモデルアップデート:Irodori-TTS、SAM-Audio、MatAnyone 2、PrismAudioほか
今週のアップデートでは、音声生成、音声認識、動画処理、画像理解、長文書OCRを中心に、新しいAIデモとモデルリソースを実用的にまとめています。 特に実用性が高い項目は、日本語音声生成向けのIrodori-TTS、プロンプトベースの音分離に対応するSAM-Audio、きれいな動画マッティングを実現するMatAnyone 2、長文書向けのUnlimited-OCR、ストリーミング音声認識向けのNemotron 3.5 ASRです。 **全体として、このまとめは、試す価値のある新しいAIモデル、それぞれの機能、そして試用できる場所をすばやく把握したい読者に役立ちます。**

HyperAI 週間 AI モデルアップデート:Irodori-TTS、SAM-Audio、MatAnyone 2、PrismAudio ほか
はじめに
今週の HyperAI アップデートでは、音声、動画、画像理解、OCR、音声認識モデルを幅広く取り上げます。注目プロジェクトは Irodori-TTS-500M-v3 です。これは、高音質な 48 kHz 音声生成、ゼロショット音声クローニング、絵文字アノテーションによるきめ細かなスタイル制御を組み合わせた、オープンな日本語テキスト読み上げモデルです。
今回のアップデートには、プロンプトベースの音声分離、動画マッティング、4D ワールドシミュレーション、動画から音声への生成、文書 OCR、オンデバイスセグメンテーション、表現豊かな音声編集、低遅延ストリーミング ASR などのツールも含まれています。以下は、元の週間まとめを整理し、公開用に整えたバージョンで、有用なスクリーンショットは元の文脈のまま残しています。
ソース注記
この記事は、BAAI Hub / HyperAI が公開した週間アップデートに基づいています。元ページでは、記事の出典が WeChat であること、また著作権上の懸念がある場合は画像を削除できることが明記されています。
QR コード、プロモーションポスター、グループ招待画像、無関係な推薦バナーは意図的に削除しました。DiaMoE-TTS と DreamOmni2 の画像リンクは元の位置に保持していますが、確認時にプレビューリクエストがタイムアウトしたため、完全に検証済みのスクリーンショットとしてではなく、その旨をここに記載しています。
週間 HyperAI アップデート概要
6 月 27 日から 7 月 3 日にかけて、HyperAI は公式サイト上で複数の公開リソースを更新しました。
- 厳選公開チュートリアル 12 件
- 人気 AI 百科事典エントリ 5 件
- 7 月の AI カンファレンス締切 4 件
今週の主なテーマは実践的な実験です。ほとんどの項目は単なる論文紹介ではなく、オンラインデモや実行可能なノートブックを提供しており、ユーザーがモデルの挙動を素早く試せるようになっています。
厳選公開チュートリアル
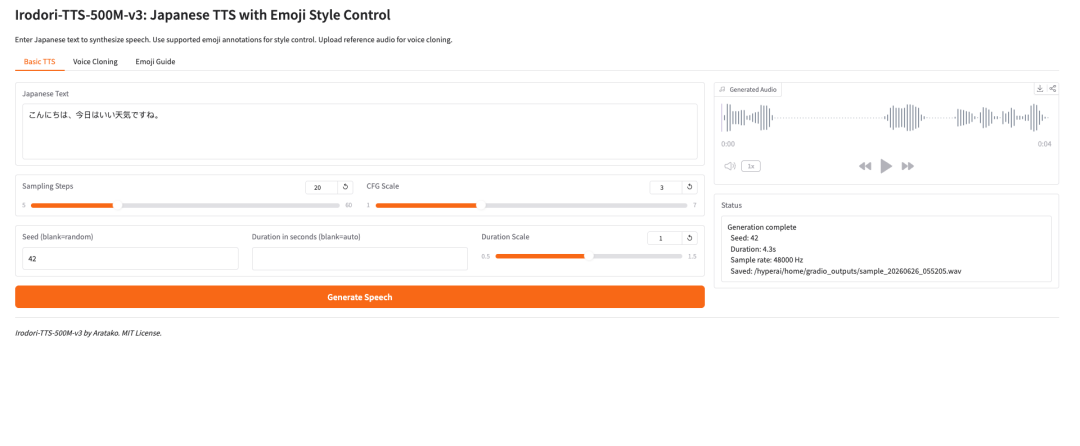
1. Irodori-TTS-500M-v3:絵文字スタイル制御に対応した日本語 TTS
Irodori-TTS は、開発者 Aratako によって 2026 年に公開されたオープンソースの日本語テキスト読み上げプロジェクトです。今回取り上げるモデル Irodori-TTS-500M-v3 は、日本語音声合成、ゼロショット音声クローニング、絵文字による音声スタイル制御向けに設計されています。
このモデルは Rectified Flow Diffusion Transformer(RF-DiT) アーキテクチャを中心に構築されており、連続的な DACVAE 潜在空間で音声を生成します。実用面で最も興味深い点は、通常 3〜10 秒程度の短い参照クリップだけで、追加のファインチューニングなしにターゲット音声をクローンできることです。
また、絵文字アノテーションによるスタイル制御にも対応しています。これにより、基本的な TTS システムよりも柔軟性が高まり、ユーザーはトーン、感情、テンポ、微妙な非言語表現をより軽量な方法で誘導できます。
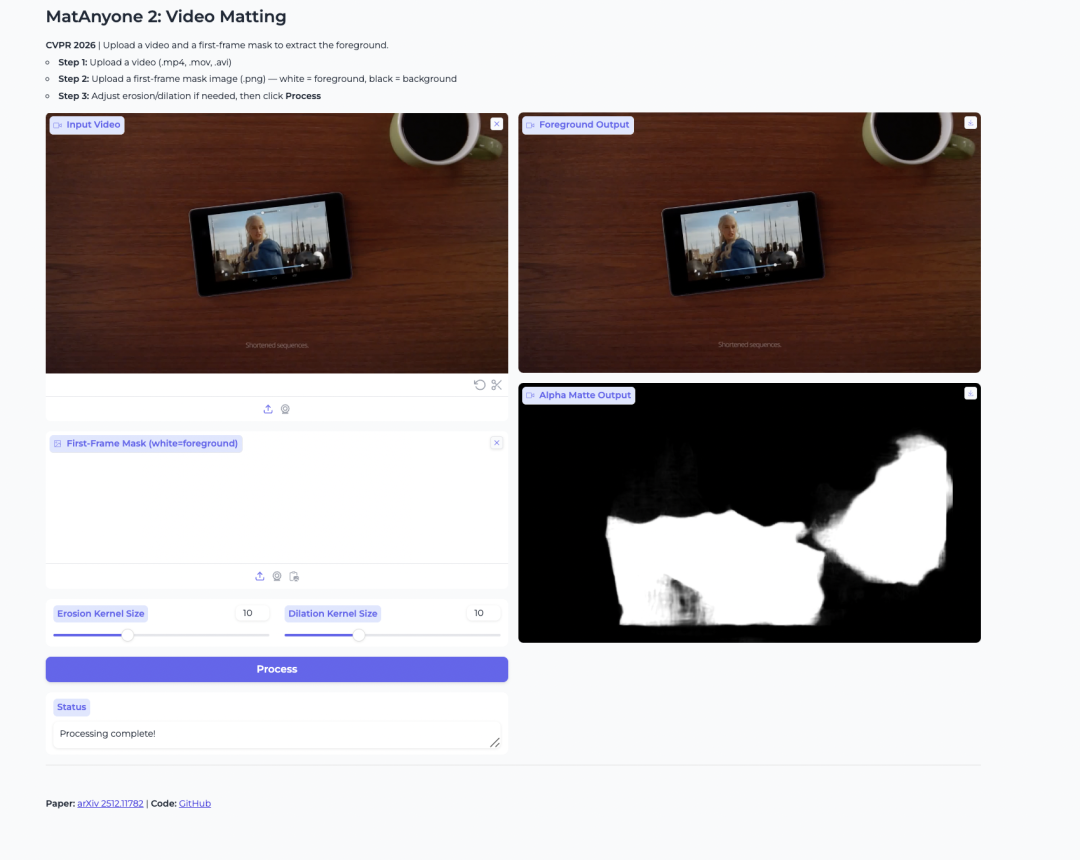
2. MatAnyone 2:前景抽出のための動画マッティング
MatAnyone 2 は、NTU S-Lab と SenseTime によって公開された動画マッティングモデルです。動画から人物の前景を抽出し、アルファマットを生成するために構築されています。
このモデルは、学習済みの品質評価器を用いることで安定性を向上させています。これにより、境界部分のアーティファクトを減らし、髪の毛、半透明のエッジ、前景の輪郭といった細部を保持しやすくなります。また、複数人が映る動画の中から特定の人物を分離したい場合にも有用です。
オンラインデモ:
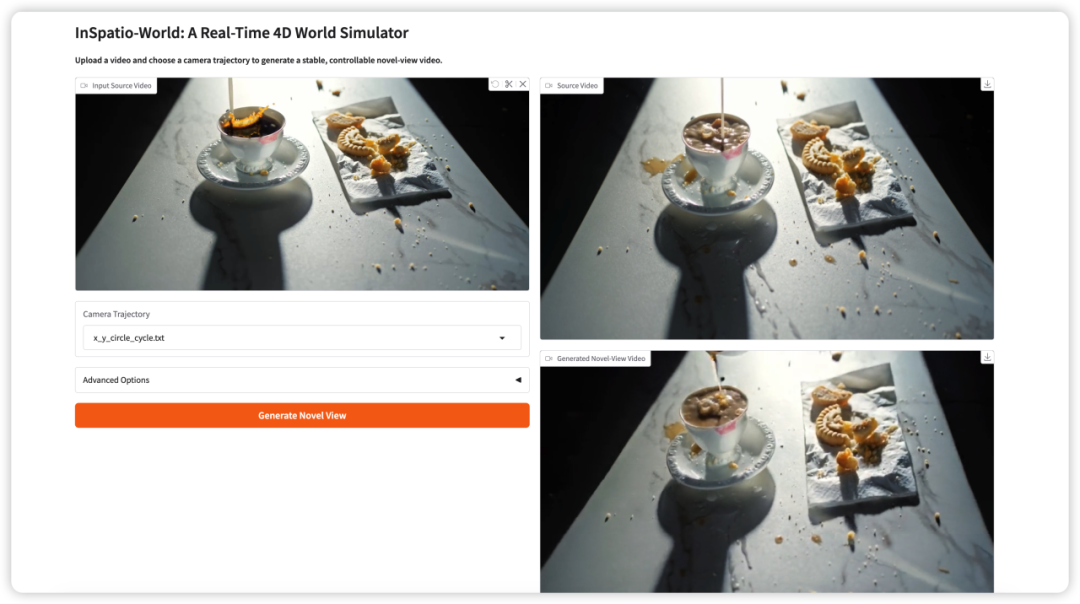
3. InSpatio-World:リアルタイム 4D ワールドシミュレーション
InSpatio-World は、InSpatio チームが 2026 年に公開したリアルタイム 4D ワールドシミュレーターです。入力動画と指定されたカメラ軌道を受け取り、安定した新視点動画を生成できます。
中核となる考え方は、動画シーンをより制御しやすくすることです。固定されたカメラ視点を受動的に見るのではなく、ユーザーはカメラの動きを定義し、時間的一貫性を保ちながら新しい視点からシーンを探索できます。
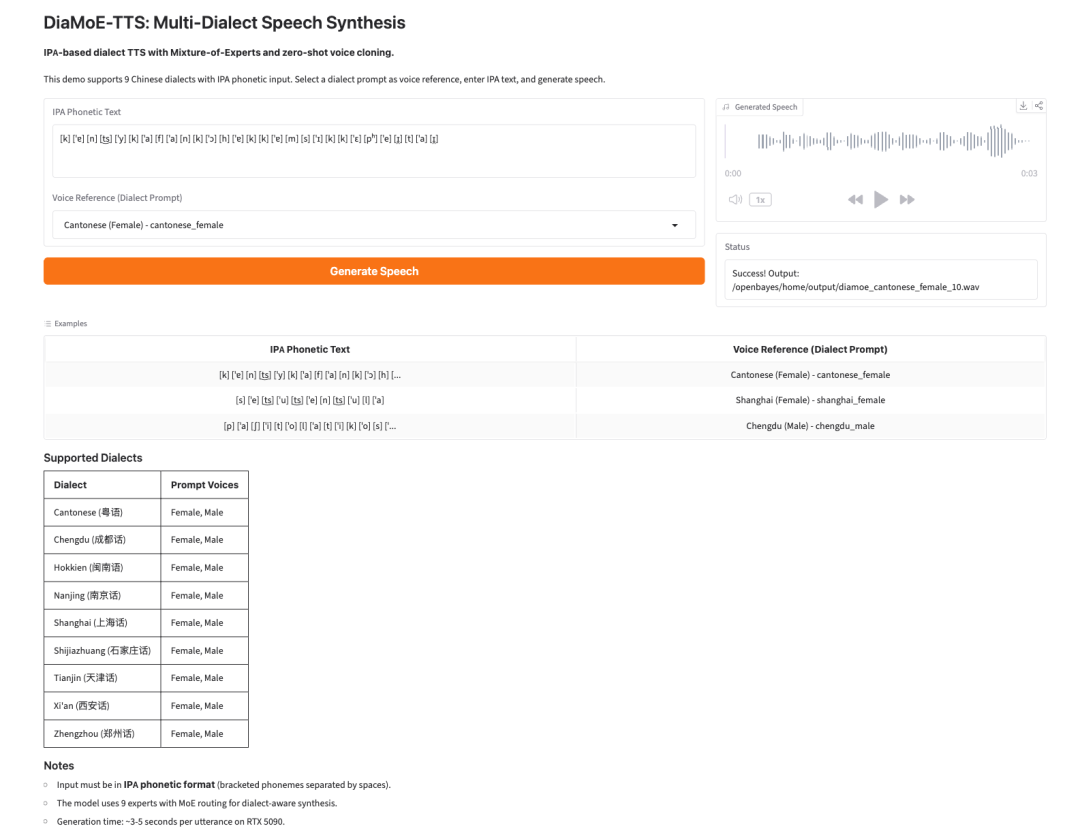
4. DiaMoE-TTS:IPA ベースの多方言音声合成
DiaMoE-TTS は、Giant AI Lab による多方言音声合成フレームワークです。方言音声生成のための統一フロントエンドとして、国際音声記号、すなわち IPA を使用します。
このモデルは、Mixture-of-Experts 設計と、LoRA や条件付けアダプターなどのパラメータ効率の高い適応手法を組み合わせています。これにより、利用可能なデータが限られている場合でも、システムは新しい方言により迅速に適応できます。
![画像は、DiaMoE-TTS: Multi-Dialect Speech Synthesis のインターフェースを示している。]
上部には、IPAベースのMixture-of-Experts設計と、LoRAや条件付きアダプターのようなパラメータ効率の高い適応手法の紹介があります。中央には「Generate Speech」ボタンがあり、下部にはサンプルテキスト入力欄が配置され、9種類の中国語方言に対応しています。右側には生成された音声波形と音声リファレンス(方言プロンプト)が表示されます。最下部には対応方言と対応するプロンプト音声が一覧表示され、モデルがKPLモデルを用いて方言音声合成を行うことや生成時間などの情報も示されています。この図は、ドキュメントで紹介されているDiaMoE-TTSモデルの内容に関連しており、その操作画面と機能を直感的に示しています。](https://we0-cms.oss-cn-beijing.aliyuncs.com/cms-assets/image/2026/07/094c618c-2830-4af5-9cdc-ca950fe12565-05-c0ba34b2-8a4a-4e6a-9d15-517f152cb52a.png)
{kind=link}
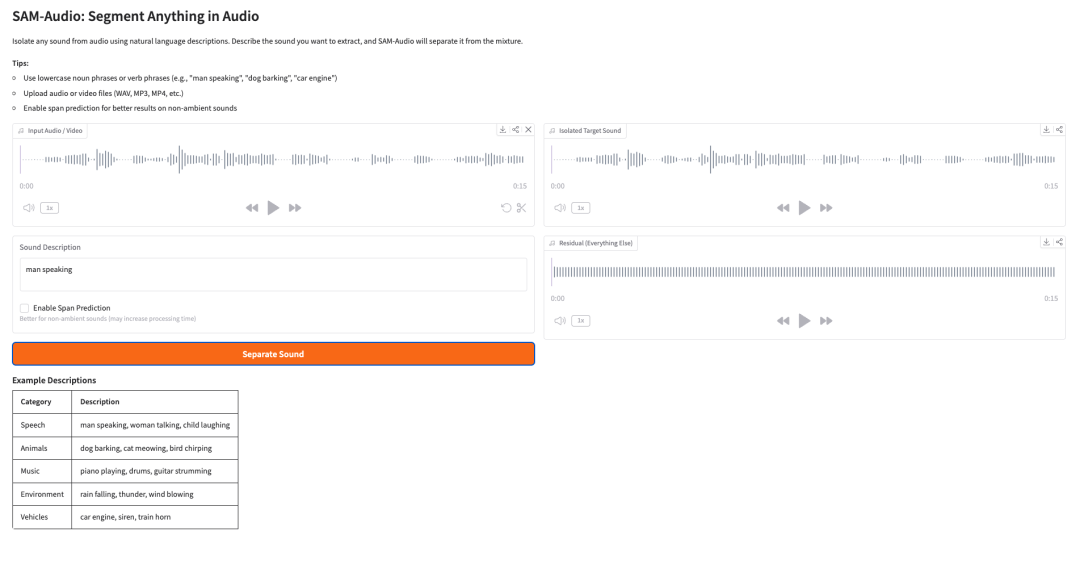
5. SAM-Audio: 音声におけるSegment Anything
SAM-Audioは、Metaの音声ソース分離基盤モデルです。自然言語による説明、動画からの視覚的手がかり、または選択された時間範囲を用いて、混合音声信号から対象の音を分離できます。
たとえば、ユーザーは分離したい音を「男性が話している」「犬が吠えている」「車のエンジン」「ピアノ演奏」などと説明できます。するとモデルは、混合音の中から対象音声を他の音から分離しようとします。
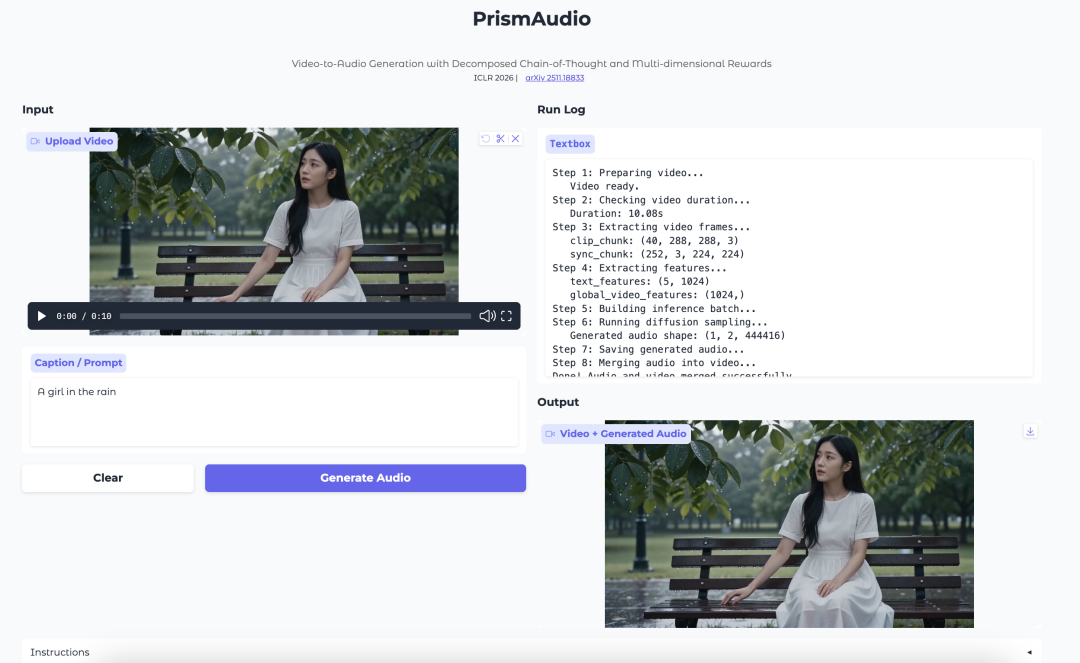
6. PrismAudio: 分解されたCoTと多次元報酬による動画から音声への生成
PrismAudioは、Tongyi Labによる動画から音声を生成するモデルです。動画の視覚シーン、タイミング、雰囲気、空間的な感覚に合った音声を生成することに重点を置いています。
このモデルは、分解されたChain-of-Thought計画プロセスを導入しています。動画から音声への生成を単一の推論ステップとして扱うのではなく、意味、時間、美的、空間の各次元にプロセスを分離します。各次元には、強化学習のための対象を絞った報酬信号が組み合わされています。
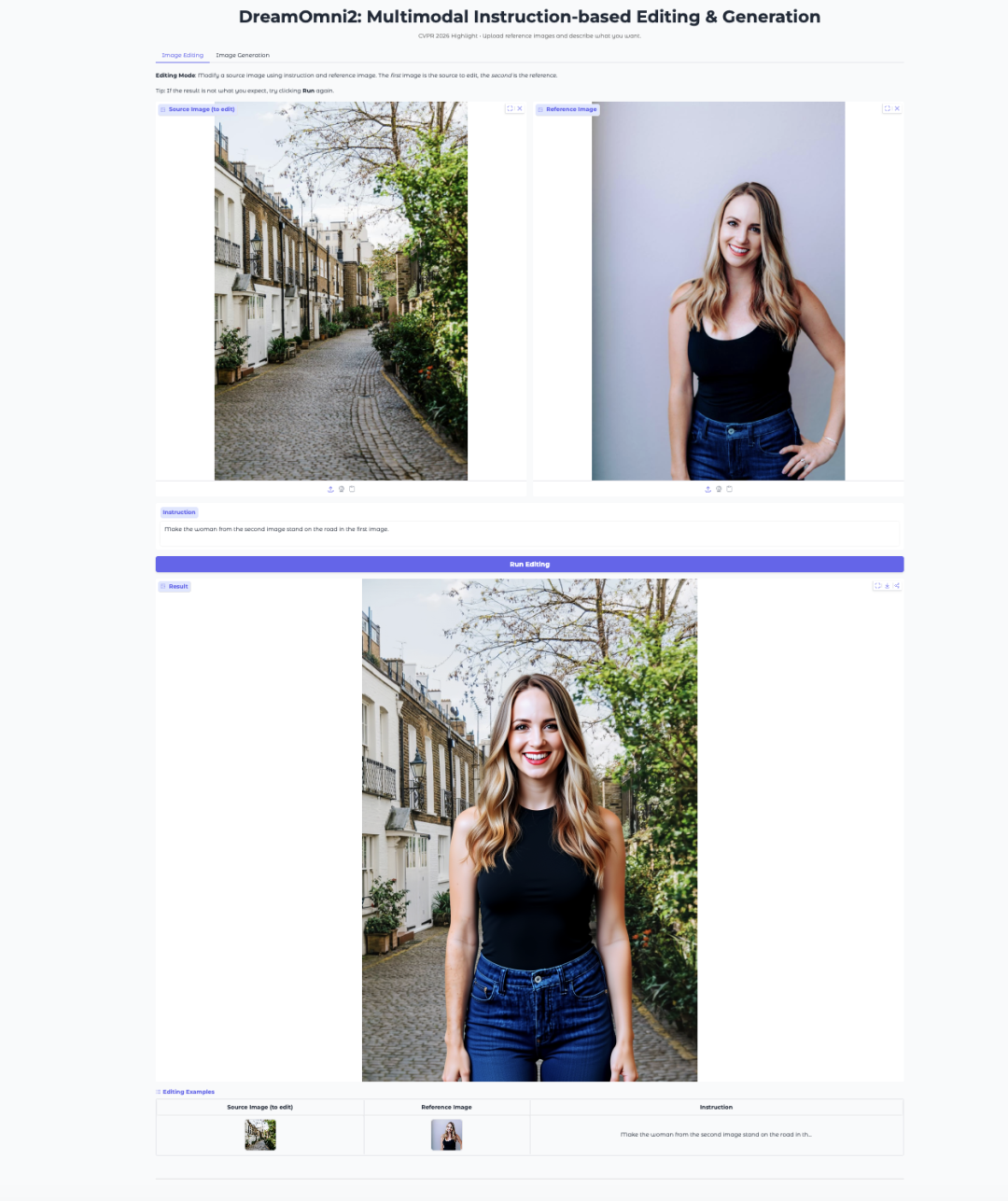
7. DreamOmni2: マルチモーダル指示に基づく画像編集と生成
DreamOmni2は、CUHK JIA Labによるマルチモーダル画像編集・生成モデルです。CVPR 2026にHighlight論文として採択されています。
このモデルはFLUX.1-Kontext-devを基盤として構築され、指示を処理するためにファインチューニングされたQwen2.5-VL-7B視覚言語モデルを使用しています。自然言語プロンプトと参照画像を併用できるため、オブジェクト置換、スタイル変換、ポーズ模倣、コンセプト駆動生成などのタスクに適しています。
8. PixelRefer: 画像と動画のためのきめ細かなオブジェクト理解
PixelReferは、Alibaba DAMO Academyによる統合型の画像・動画オブジェクト理解フレームワークです。シーン全体を説明するだけでなく、オブジェクト中心のきめ細かな理解に重点を置いています。
このフレームワークは、領域レベルの指示、キャプション生成、質問応答をサポートしています。また、スケール適応型オブジェクトトークナイザーと、より軽量なPixelRefer-Liteバリアントを導入し、オブジェクト表現をよりコンパクトかつ効率的にしています。

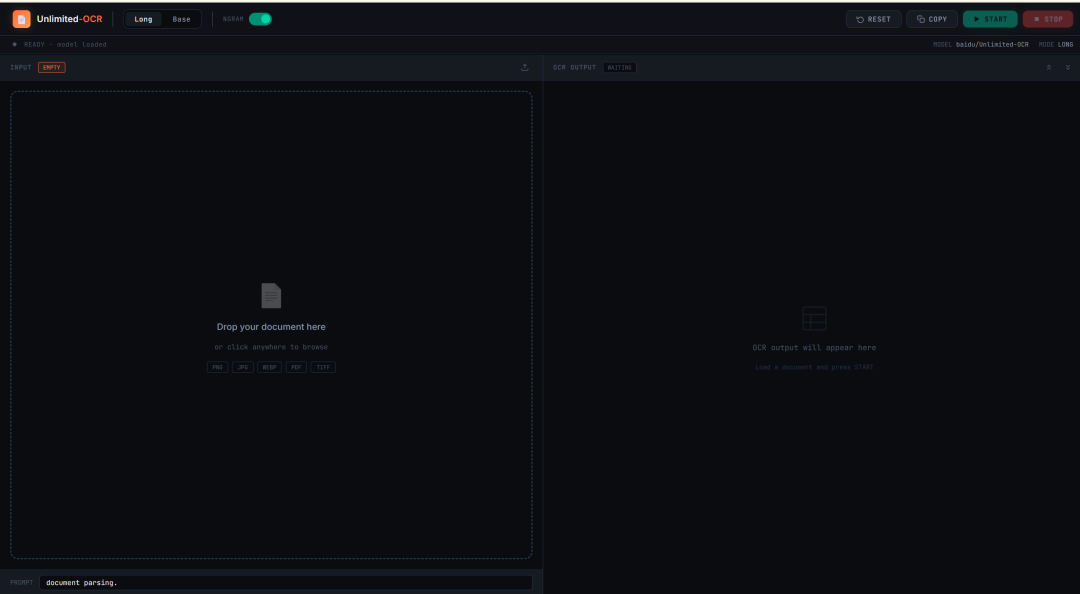
9. Unlimited-OCR: ワンショット長文書OCRとレイアウト解析
Unlimited-OCRは、Baiduが2026年に公開したOCRおよび文書レイアウト解析プロジェクトです。単一ページ認識だけでなく、長文書の解析を目的として設計されています。
このプロジェクトは、単一の文書画像、複数ページの画像、PDFから変換されたページを処理できます。論文、レポート、スキャン文書、長い表、複数ページにわたる構造化資料に特に有用です。
10. EdgeTAM: エッジデバイス向けのプロンプト可能な画像・動画セグメンテーション
EdgeTAMは、Meta Reality LabsとNTU S-Labが開発したオンデバイスのTrack Anything Modelです。リソースが限られたデバイス向けに設計されており、SAMスタイルのモデルが持つインタラクティブなセグメンテーション能力を維持しています。
このモデルは、2D Spatial Perceiverと蒸留パイプラインによって、SAM 2のメモリアテンションのボトルネックを軽減します。実用上、これはプロンプト可能なセグメンテーションをサポートできることを意味します。
エッジハードウェア上で、セグメンテーションと動画オブジェクト追跡をより効率的に実行できます。

11. Step-Audio-EditX: ゼロショット音声クローニングと表現豊かな音声編集
Step-Audio-EditX は、StepFunの音声編集モデルです。30億パラメータのLLMベース音声モデルと強化学習を組み合わせ、ゼロショット音声クローニングと表現豊かな音声編集をサポートします。
このモデルは、標準中国語、英語、四川語、広東語、日本語、韓国語に対応しています。感情制御、話し方の編集、パラ言語的編集、反復的な音声改善などのタスク向けに構築されています。

12. Nemotron 3.5 ASR Streaming 0.6B: 軽量ストリーミング音声認識
Nemotron 3.5 ASR Streaming 0.6B は、NVIDIAの自動音声認識モデルです。低遅延のストリーミング文字起こし向けに構築されており、キャッシュを意識したFastConformer-RNNTアーキテクチャを使用しています。
主要な設計はコンテキストの再利用です。ストリーミング推論中、モデルは重複する音声チャンクを再計算するのではなく、エンコーダーのコンテキストを再利用します。これにより、冗長な計算を削減し、リアルタイム性能を向上させることができます。
人気の百科事典項目
HyperAIは今週、人気のAI百科事典項目も5つ紹介しました。
- 大規模言語モデル(LLM)
- ワールドアクションモデル(WAM)
- 調和平均
- バーチャルスクリーニング
- AIフィードバックによる強化学習(RLAIF)
HyperAIのWikiは、AI関連の概念や解説を数百件収集しています。論文、チュートリアル、モデルドキュメントによく登場する用語をすばやく理解したい読者に役立ちます。
7月のAIカンファレンス締切
元の更新情報では、7月のAIおよびコンピュータサイエンス関連カンファレンスの締切もいくつか掲載されています。すべての締切時刻はAoE時間で表示されています。
| 日付 | 時刻 | カンファレンス |
|---|---|---|
| 7月09日 | 23:59:59 | POPL 2027 |
| 7月10日 | 23:59:59 | ICSE 2027 |
| 7月17日 | 23:59:59 | SIGMOD 2027 |
| 7月28日 | 23:59:59 | AAAI 2027 |
HyperAIについて
HyperAIは、人工知能と高性能コンピューティングのコミュニティです。同ウェブサイトは、開発者、研究者、AI学習者向けに公開リソースを提供しています。
元の情報源によると、HyperAIはすでに以下を収集またはサポートしています。
- 国内アクセラレーションノード付きの公開データセット2,100件以上
- 定番および人気のオンラインチュートリアル700件以上
- AI4Science論文ケーススタディ300件以上
- AI関連の百科事典項目700件以上
- Apache TVMの完全な中国語ドキュメントミラー
FAQ
Irodori-TTS-500M-v3とは何ですか?
Irodori-TTS-500M-v3は、RF-DiTアーキテクチャに基づくオープンな日本語テキスト音声合成モデルです。日本語音声生成、短い参照音声によるゼロショット音声クローニング、絵文字ベースのスタイル制御をサポートしています。
Irodori-TTSはファインチューニングなしで音声をクローニングできますか?
はい。元の更新情報では、Irodori-TTSは短い参照音声クリップ、通常3〜10秒程度からのゼロショット音声クローニングをサポートすると説明されています。ただし、その効果は参照音声の品質と明瞭さに依存します。
SAM-Audioは何に使われますか?
SAM-Audioは、プロンプトベースの音源分離に使用されます。ユーザーは抽出したい音を説明したり、視覚的な手がかりを提供したり、時間範囲を指定したりして、混合録音から対象音を分離できます。
動画マッティングと動画セグメンテーションの違いは何ですか?
動画セグメンテーションは通常、オブジェクトを領域またはマスクに分離します。一方、動画マッティングはより詳細なアルファマットを推定します。マッティングは、きれいな前景抽出、髪の毛のディテール、半透明のエッジ、合成において特に重要です。
PrismAudioは何を生成しますか?
PrismAudioは動画向けの音声を生成します。生成される音を、動画の意味内容、タイミング、美的感覚、空間的手がかりと整合させようとします。
Unlimited-OCRはなぜ長文書に有用ですか?
Unlimited-OCRは、単に孤立した1ページのOCRではなく、長期的な文書解析向けに設計されています。論文、レポート、スキャンファイル、長い表、複数ページのPDF由来画像を扱う際に役立ちます。
Nemotron 3.5 ASR Streaming 0.6Bはリアルタイム音声文字起こしに適していますか?
はい。低遅延向けに設計されています。
ストリーミング ASR。そのキャッシュ対応 FastConformer-RNNT アーキテクチャは、ストリーミング推論中にコンテキストを再利用することで、冗長な計算の削減に役立ちます。
関連ツール
- Irodori-TTS: 参照音声によるボイスクローニングとスタイル制御に対応した、オープンソースの日本語 TTS。
- Irodori-TTS-500M-v3 on Hugging Face: 500M v3 日本語 TTS チェックポイントのモデルページ。
- SAM-Audio: 音声における Segment Anything の推論とサンプルを提供する Meta のリポジトリ。
- MatAnyone 2: MatAnyone 2 動画マッティングフレームワークのプロジェクトページ。
- InSpatio-World: リアルタイム対話型 4D 世界シミュレーションのプロジェクトページ。
- DiaMoE-TTS: IPA ベースの多方言音声合成の GitHub リポジトリ。
- PrismAudio: 分解された CoT と多次元報酬を用いた動画から音声生成のプロジェクトページ。
- DreamOmni2: 指示ベースのマルチモーダル画像編集・生成を行うオープンソースプロジェクト。
- PixelRefer: きめ細かな画像・動画オブジェクト理解のための Alibaba DAMO Academy のフレームワーク。
- Unlimited-OCR: Baidu による長期文脈 OCR と文書解析プロジェクト。
- EdgeTAM: プロンプト可能な画像・動画セグメンテーション向けの、Meta によるオンデバイスの track-anything モデル。
- Step-Audio-EditX: ゼロショット音声クローニングと表現豊かな音声編集のための StepFun のモデル。
- Nemotron 3.5 ASR Streaming 0.6B: 低遅延ストリーミング ASR 向け NVIDIA の Hugging Face モデルページ。
関連リンク
- Original BAAI Hub Article: 今回の HyperAI 週間アップデートの元記事。
- HyperAI Official Website: HyperAI のチュートリアル、論文、データセット、AI リソースのメインポータル。
- HyperAI Wiki: 一般的な概念や研究用語を網羅する AI 百科事典ポータル。
- HyperAI Conference Tracker: AI およびコンピューターサイエンス分野の学会締切トラッカー。
- Meta SAM-Audio Research Page: Segment Anything Model Audio の公式研究ページ。
- SAM-Audio Paper on arXiv: SAM-Audio 基盤モデルを説明した研究論文。
- MatAnyone 2 Paper on arXiv: MatAnyone 2 と学習ベースのマッティング品質評価器に関する論文。
- Unlimited-OCR Paper on arXiv: Unlimited OCR と長期文脈解析に関する技術レポート。
まとめ
今回の週間アップデートでは、音声生成、音声認識、動画処理、画像理解、長文書 OCR を中心に、新しい AI デモやモデルリソースが役立つ形でまとめられています。
特に実用性が高いものとして、日本語音声生成向けの Irodori-TTS、プロンプトベースの音源分離向けの SAM-Audio、高品質な動画マッティング向けの MatAnyone 2、長文書向けの Unlimited-OCR、ストリーミング音声認識向けの Nemotron 3.5 ASR が挙げられます。
全体として、このまとめは、試す価値のある新しい AI モデル、それぞれの機能、そして試用できる場所を素早く把握したい読者にとって有用です。