تحديث HyperAI الأسبوعي لنماذج الذكاء الاصطناعي: Irodori-TTS وSAM-Audio وMatAnyone 2 وPrismAudio والمزيد
يجمع هذا التحديث الأسبوعي مجموعة مفيدة من عروض الذكاء الاصطناعي الجديدة وموارد النماذج، لا سيما في مجالات توليد الصوت، والتعرّف على الكلام، ومعالجة الفيديو، وفهم الصور، والتعرّف البصري على الحروف في المستندات الطويلة. أبرز الأدوات العملية هي Irodori-TTS لتوليد الأصوات باللغة اليابانية، وSAM-Audio لفصل الأصوات اعتمادًا على الموجّهات، وMatAnyone 2 لعزل العناصر في الفيديو بدقة، وUnlimited-OCR للمستندات الطويلة، وNemotron 3.5 ASR للتعرّف على الكلام أثناء البث. **بشكل عام، تُعد هذه الجولة مفيدة للقراء الذين يرغبون في اكتشاف نماذج الذكاء الاصطناعي الجديدة الجديرة بالتجربة بسرعة، ومعرفة ما يفعله كل نموذج، وأين يمكن تجربته.**

تحديث HyperAI الأسبوعي لنماذج الذكاء الاصطناعي: Irodori-TTS وSAM-Audio وMatAnyone 2 وPrismAudio والمزيد
مقدمة
يركّز تحديث HyperAI لهذا الأسبوع على مزيج قوي من نماذج الصوت والفيديو وفهم الصور والتعرّف الضوئي على الحروف (OCR) والتعرّف على الكلام. المشروع الأبرز هو Irodori-TTS-500M-v3، وهو نموذج مفتوح لتحويل النص الياباني إلى كلام، يجمع بين توليد كلام عالي الدقة بتردد 48 كيلوهرتز، واستنساخ الصوت دون تدريب مسبق على المثال، والتحكم الدقيق في الأسلوب عبر تعليقات الرموز التعبيرية.
يتضمن التحديث أيضًا أدوات لفصل الصوت بالاعتماد على التعليمات النصية، وعزل العناصر في الفيديو، ومحاكاة العوالم رباعية الأبعاد، وتوليد الصوت من الفيديو، والتعرّف الضوئي على المستندات، والتجزئة على الجهاز، وتحرير الصوت التعبيري، والتعرّف الآني منخفض التأخير على الكلام المتدفق. فيما يلي نسخة منقّحة وجاهزة للنشر من الملخص الأسبوعي الأصلي، مع الحفاظ على لقطات الشاشة المفيدة في سياقها الأصلي.
ملاحظة المصدر
تستند هذه المقالة إلى التحديث الأسبوعي الصادر عن BAAI Hub / HyperAI والمنشور في . وتشير الصفحة الأصلية إلى أن مصدر المقالة من WeChat، وأن الصور يمكن إزالتها في حال وجود مخاوف متعلقة بحقوق النشر.
تمت إزالة رموز QR والملصقات الترويجية وصور دعوات المجموعات ولافتات التوصيات غير ذات الصلة عمدًا. تم الإبقاء على روابط صور DiaMoE-TTS وDreamOmni2 في مواضعها الأصلية، لكن طلبات معاينتها انتهت مهلتها أثناء الفحص، لذلك جرى التنويه إليها هنا بدلًا من التعامل معها كلقطات شاشة موثّقة بالكامل.
نظرة عامة على تحديث HyperAI الأسبوعي
من 27 يونيو إلى 3 يوليو، حدّثت HyperAI عدة موارد عامة على موقعها الرسمي:
- 12 درسًا تعليميًا عامًا مختارًا
- 5 إدخالات شائعة في موسوعة الذكاء الاصطناعي
- 4 مواعيد نهائية لمؤتمرات الذكاء الاصطناعي في يوليو
الموضوع الرئيسي لهذا الأسبوع هو التجريب العملي. فمعظم الإدخالات ليست مجرد أوصاف لأوراق بحثية؛ بل توفر عروضًا تجريبية عبر الإنترنت أو دفاتر قابلة للتشغيل كي يتمكن المستخدمون من اختبار سلوك النماذج بسرعة.
دروس عامة مختارة
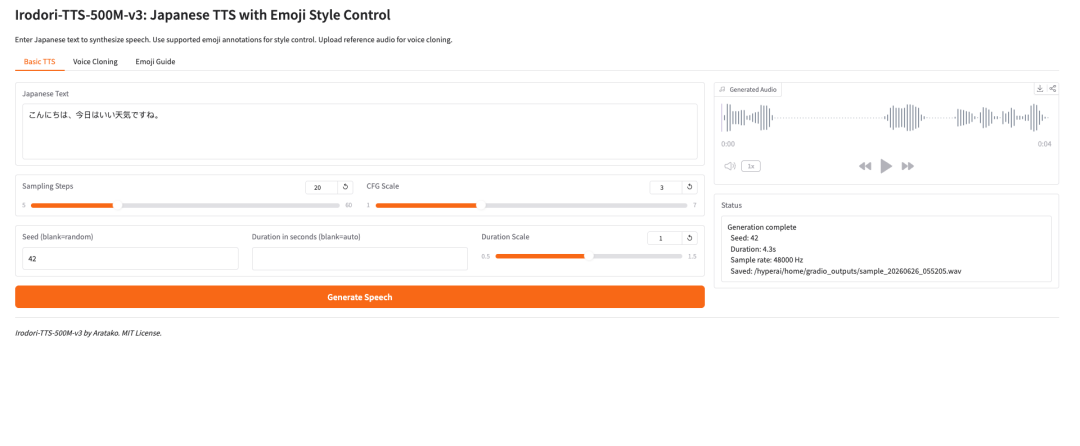
1. Irodori-TTS-500M-v3: تحويل النص الياباني إلى كلام مع التحكم في الأسلوب عبر الرموز التعبيرية
Irodori-TTS هو مشروع مفتوح المصدر لتحويل النص الياباني إلى كلام، أصدره المطوّر Aratako في عام 2026. النموذج المميز، Irodori-TTS-500M-v3، مصمم لتوليف الكلام الياباني، واستنساخ الصوت دون تدريب مسبق على المثال، والتحكم في أسلوب الصوت بالاسترشاد بالرموز التعبيرية.
يعتمد النموذج على بنية Rectified Flow Diffusion Transformer (RF-DiT) ويولّد الكلام ضمن فضاء كامن مستمر لـ DACVAE. ومن الناحية العملية، تتمثل أكثر نقاطه إثارة للاهتمام في قدرته على استنساخ صوت مستهدف من مقطع مرجعي قصير فقط، عادةً في حدود 3 إلى 10 ثوانٍ، دون الحاجة إلى ضبط دقيق إضافي.
كما يدعم التحكم في الأسلوب عبر تعليقات الرموز التعبيرية. وهذا يجعل النموذج أكثر مرونة من نظام أساسي لتحويل النص إلى كلام: إذ يمكن للمستخدمين توجيه النبرة والعاطفة والإيقاع والتعبيرات غير اللفظية الدقيقة بطريقة أخف وزنًا.
2. MatAnyone 2: عزل عناصر الفيديو لاستخراج المقدمة
MatAnyone 2 هو نموذج لعزل عناصر الفيديو أصدره NTU S-Lab وSenseTime. صُمم لاستخراج مقدمة تحتوي على أشخاص وتوليد خرائط ألفا من مقاطع الفيديو.
يحسّن النموذج الاستقرار باستخدام مقيّم جودة متعلّم. ويساعد ذلك على تقليل تشوهات الحواف والحفاظ على التفاصيل مثل الشعر والحواف شبه الشفافة وحدود عناصر المقدمة. كما يكون مفيدًا عندما يرغب المستخدم في عزل شخص محدد في فيديو يضم عدة أشخاص.
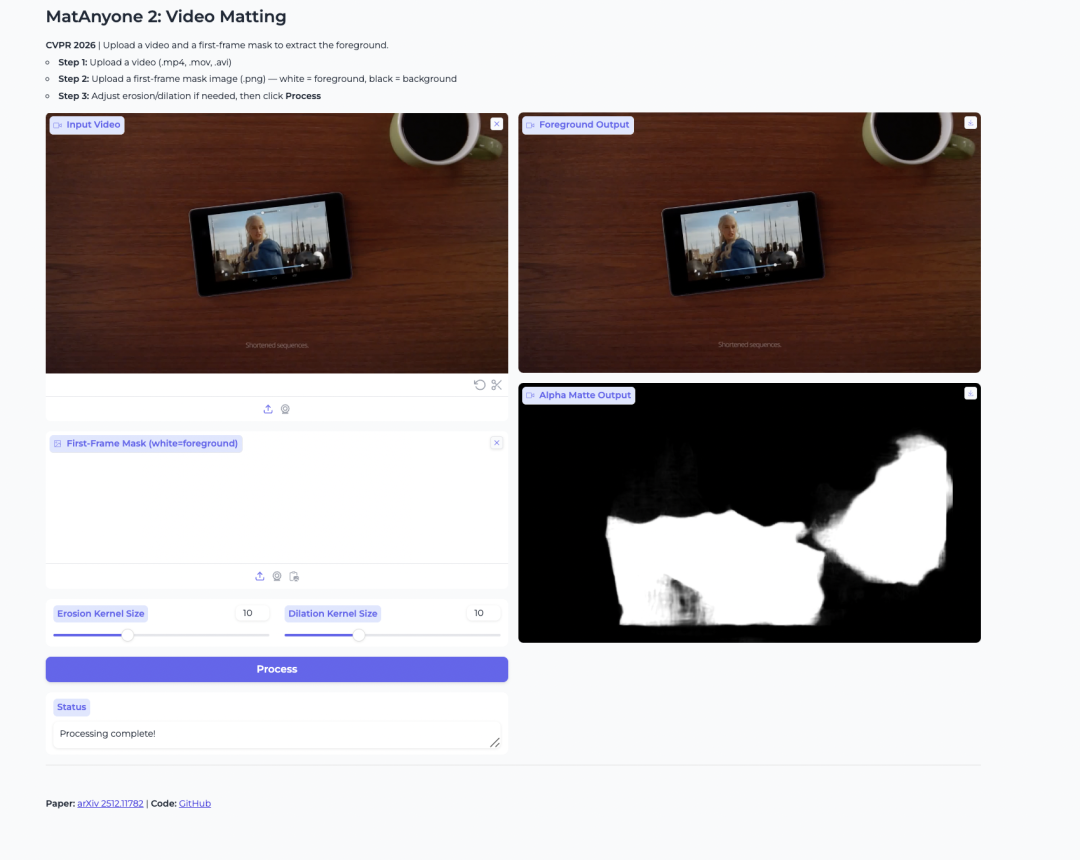
العرض التجريبي عبر الإنترنت:
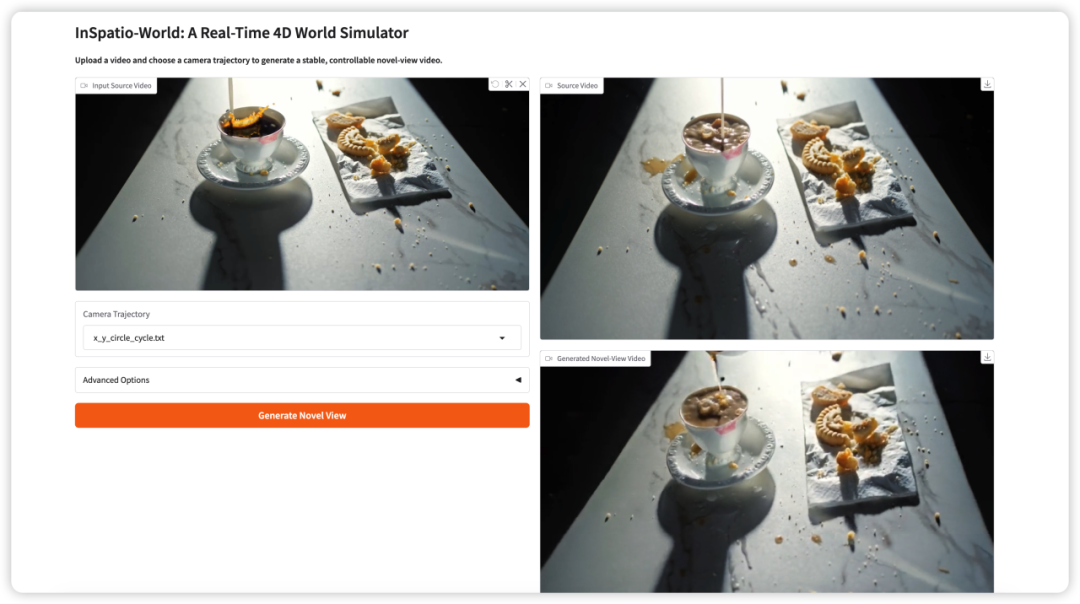
3. InSpatio-World: محاكاة عوالم رباعية الأبعاد في الزمن الحقيقي
InSpatio-World هو محاكي عوالم رباعية الأبعاد في الزمن الحقيقي أصدره فريق InSpatio في عام 2026. يمكنه أخذ فيديو مُدخل ومسار كاميرا محدد، ثم توليد فيديو مستقر من منظور جديد.
الفكرة الأساسية هي جعل مشاهد الفيديو أكثر قابلية للتحكم. فبدلًا من مشاهدة منظور كاميرا ثابت بشكل سلبي، يستطيع المستخدمون تحديد حركة الكاميرا واستكشاف المشهد من زوايا رؤية جديدة مع الحفاظ على الاتساق الزمني.
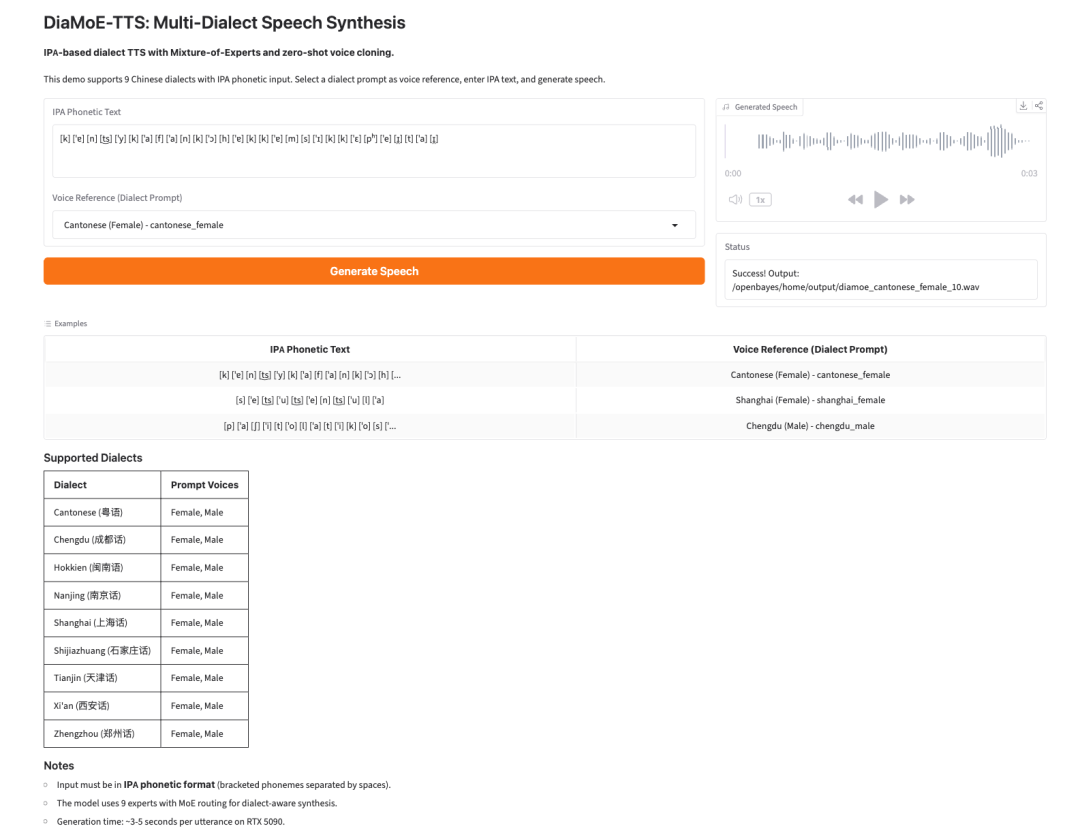
4. DiaMoE-TTS: توليف كلام متعدد اللهجات قائم على الأبجدية الصوتية الدولية
DiaMoE-TTS هو إطار لتوليف الكلام متعدد اللهجات من Giant AI Lab. يستخدم الأبجدية الصوتية الدولية، أو IPA، كواجهة موحدة لتوليد الكلام باللهجات.
يجمع النموذج بين تصميم خليط الخبراء وأساليب التكيّف ذات الكفاءة في المعلمات مثل LoRA ومحوّلات التهيئة. ويتيح ذلك للنظام التكيّف بسرعة أكبر مع اللهجات الجديدة، حتى عند توفر بيانات محدودة فقط.
{kind=link}
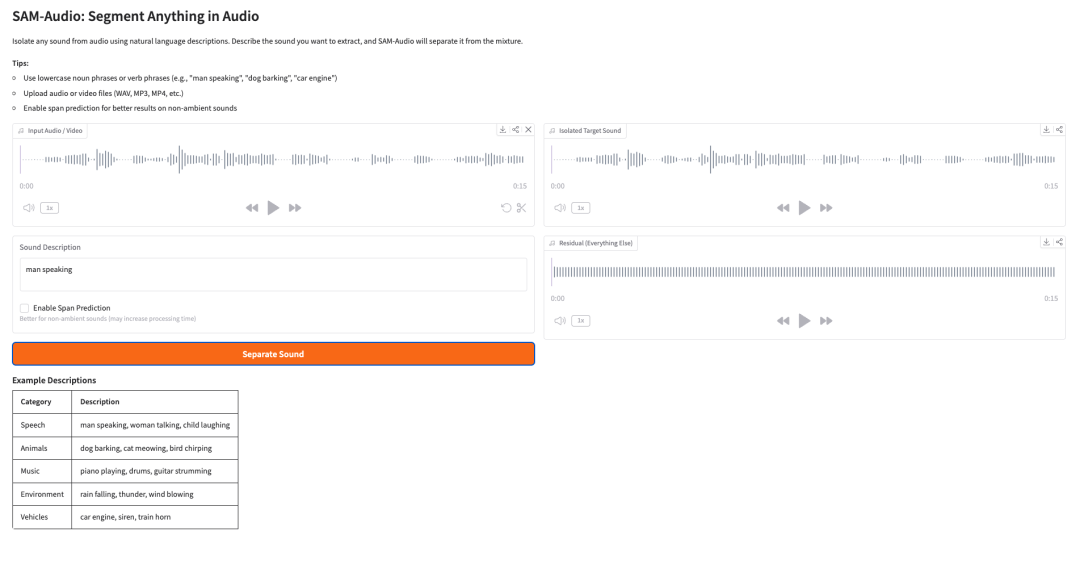
5. SAM-Audio: تجزئة أي شيء في الصوت
SAM-Audio هو نموذج أساسي من Meta لفصل مصادر الصوت. يمكنه عزل صوت مستهدف من إشارة صوتية مختلطة باستخدام أوصاف باللغة الطبيعية، أو إشارات بصرية من الفيديو، أو مقطع زمني محدد.
على سبيل المثال، يمكن للمستخدم وصف الصوت الذي يريد فصله، مثل “رجل يتحدث”، أو “كلب ينبح”، أو “محرك سيارة”، أو “عزف بيانو”. ثم يحاول النموذج فصل الصوت المستهدف عن كل ما عداه في المزيج.
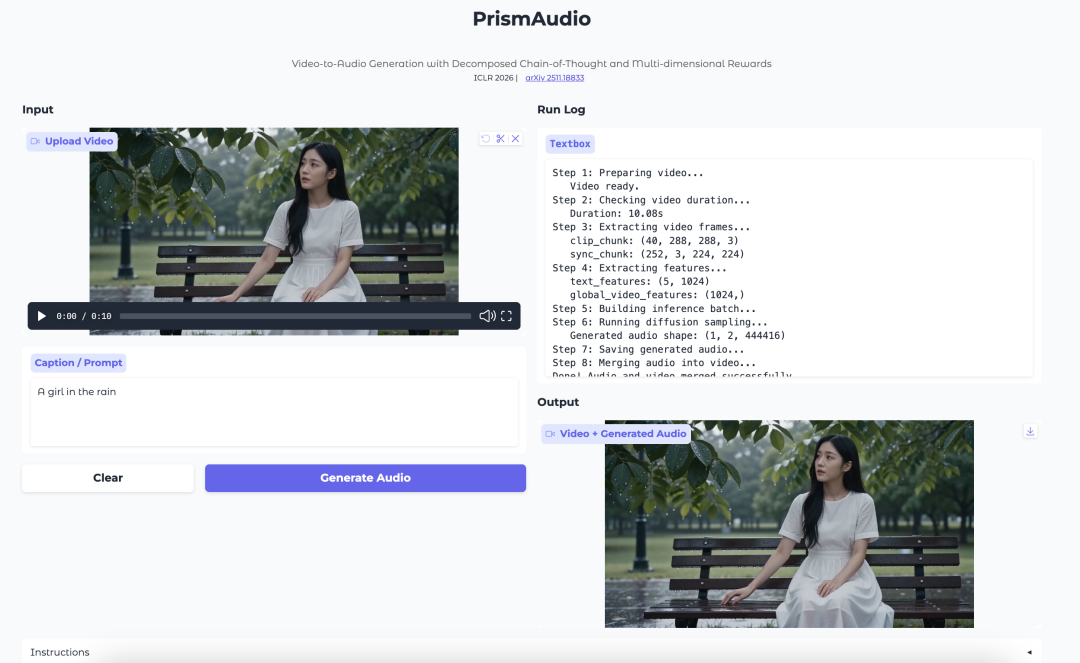
6. PrismAudio: توليد الصوت من الفيديو باستخدام سلسلة تفكير مفككة ومكافآت متعددة الأبعاد
PrismAudio هو نموذج لتوليد الصوت من الفيديو من Tongyi Lab. يركز على توليد صوت يطابق المشهد البصري والتوقيت والأجواء والإحساس المكاني للفيديو.
يقدّم النموذج عملية تخطيط مفككة قائمة على سلسلة التفكير. فبدلًا من التعامل مع توليد الصوت من الفيديو كخطوة استدلالية واحدة، يفصل العملية إلى أبعاد دلالية وزمنية وجمالية ومكانية. ويُقرن كل بُعد بإشارة مكافأة موجّهة للتعلّم المعزز.
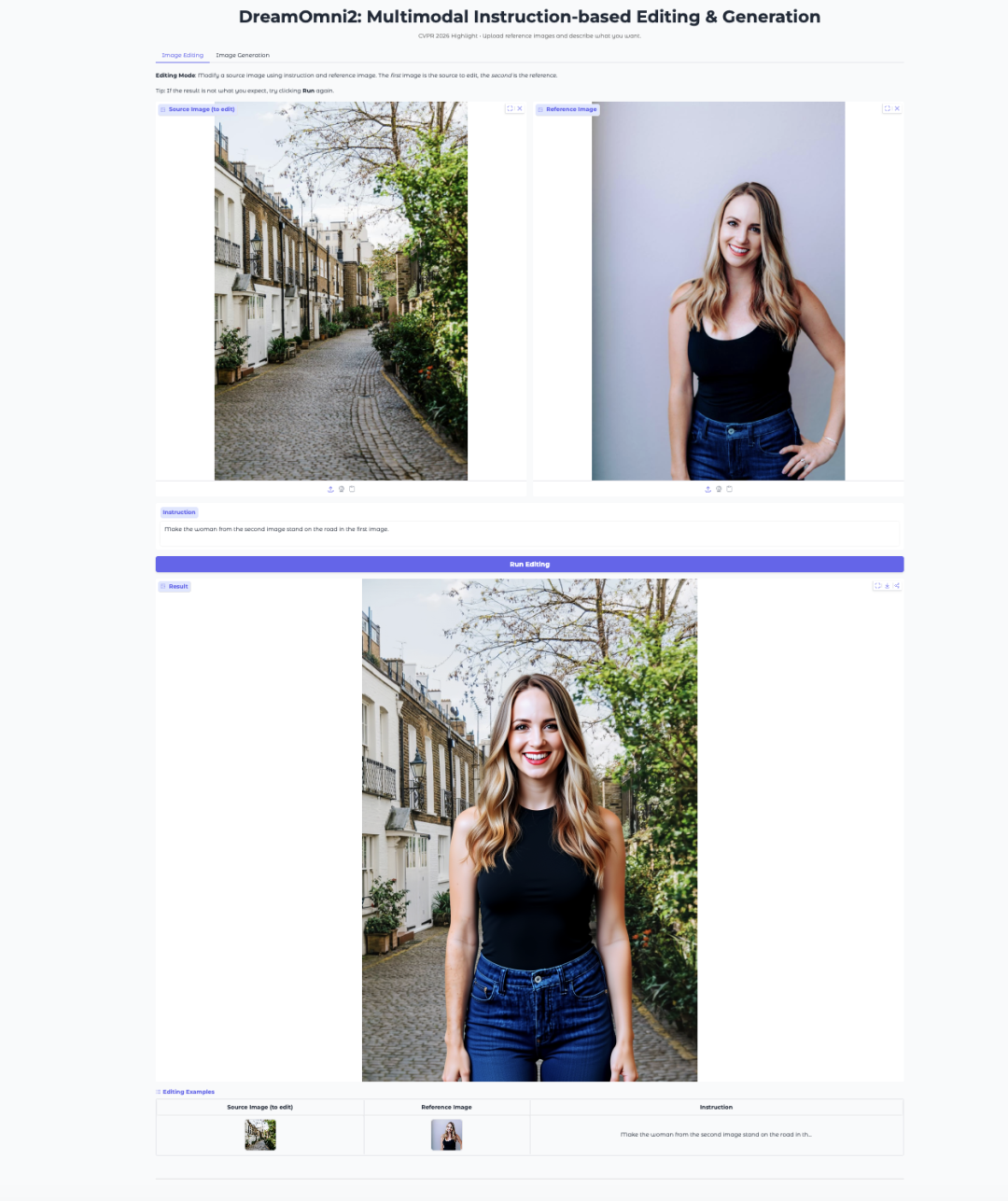
7. DreamOmni2: تحرير الصور وتوليدها متعدد الوسائط والقائم على التعليمات
DreamOmni2 هو نموذج متعدد الوسائط لتحرير الصور وتوليدها من CUHK JIA Lab. وقد قُبل في CVPR 2026 كورقة مميزة.
بُني النموذج على FLUX.1-Kontext-dev ويستخدم نموذج اللغة والرؤية Qwen2.5-VL-7B بعد ضبطه دقيقًا لمعالجة التعليمات. ويدعم التعليمات النصية باللغة الطبيعية إلى جانب الصور المرجعية، ما يجعله مناسبًا لمهام مثل استبدال الكائنات، ونقل الأسلوب، ومحاكاة الوضعيات، والتوليد الموجّه بالمفاهيم.
8. PixelRefer: فهم دقيق للكائنات في الصور والفيديوهات
PixelRefer هو إطار موحّد لفهم الكائنات في الصور والفيديوهات من Alibaba DAMO Academy. يركز على الفهم الدقيق المتمحور حول الكائنات، بدلًا من الاكتفاء بوصف المشهد بالكامل.
يدعم الإطار الإشارة على مستوى المناطق، والتعليق الوصفي، والإجابة عن الأسئلة. كما يقدّم مُرمِّز كائنات متكيّفًا مع المقياس، ونسخة أخف باسم PixelRefer-Lite لجعل تمثيل الكائنات أكثر اختصارًا وكفاءة.

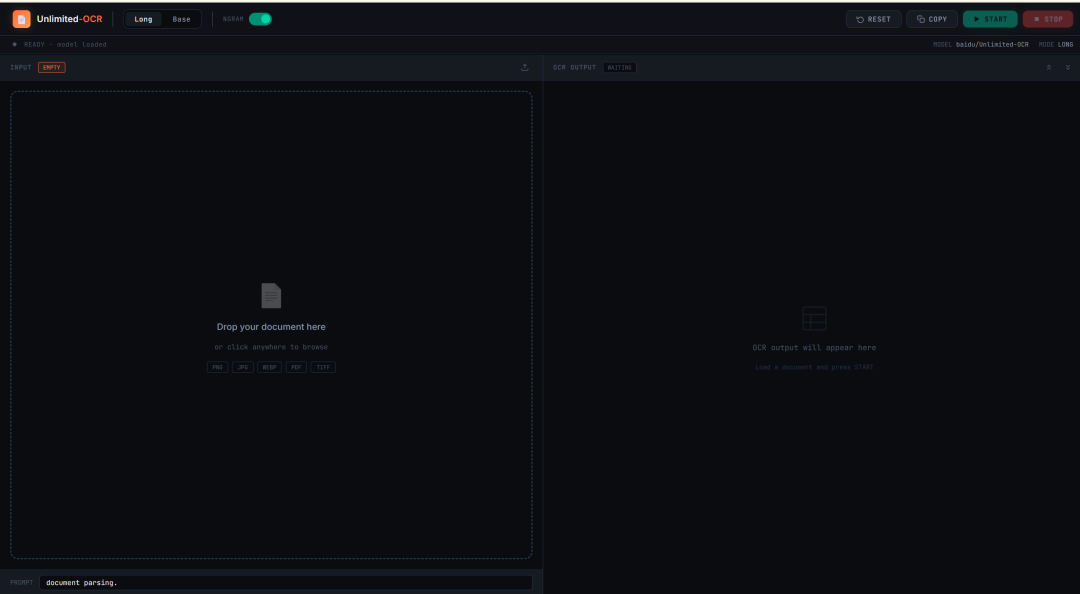
9. Unlimited-OCR: التعرف الضوئي على المستندات الطويلة وتحليل التخطيط دفعة واحدة
Unlimited-OCR هو مشروع للتعرف الضوئي على الحروف وتحليل تخطيط المستندات أصدرته Baidu في عام 2026. صُمم لتحليل المستندات الطويلة بدلًا من الاقتصار على التعرف على صفحة واحدة.
يمكن للمشروع معالجة صور المستندات المفردة، والصور متعددة الصفحات، والصفحات المحوّلة من ملفات PDF. وهو مفيد بشكل خاص للأبحاث والتقارير والمستندات الممسوحة ضوئيًا والجداول الطويلة والمواد المنظمة متعددة الصفحات.
10. EdgeTAM: تجزئة الصور والفيديوهات القابلة للتوجيه على الأجهزة الطرفية
EdgeTAM هو نموذج Track Anything يعمل على الجهاز، طوّرته Meta Reality Labs وNTU S-Lab. صُمم للأجهزة محدودة الموارد مع الحفاظ على قدرة التجزئة التفاعلية التي تتميز بها نماذج نمط SAM.
يقلل النموذج عنق الزجاجة في انتباه الذاكرة في SAM 2 من خلال 2D Spatial Perceiver وخط معالجة للتقطير. وعمليًا، يعني ذلك أنه يستطيع دعم التجزئة القابلة للتوجيه
تجزئة وتتبع كائنات الفيديو بكفاءة أكبر على عتاد الحافة.

11. Step-Audio-EditX: استنساخ الصوت دون أمثلة مسبقة وتحرير صوتي تعبيري
Step-Audio-EditX هو نموذج لتحرير الصوت من StepFun. يجمع بين نموذج صوتي قائم على نموذج لغوي كبير بعدد 3 مليارات معلمة والتعلم المعزز، لدعم استنساخ الصوت دون أمثلة مسبقة والتحرير الصوتي التعبيري.
يمكن للنموذج التعامل مع الماندرينية والإنجليزية ولهجة سيتشوان والكانتونية واليابانية والكورية. وقد بُني لمهام مثل التحكم في العاطفة، وتحرير أسلوب التحدث، وتحرير السمات شبه اللغوية، والتحسين التكراري للصوت.

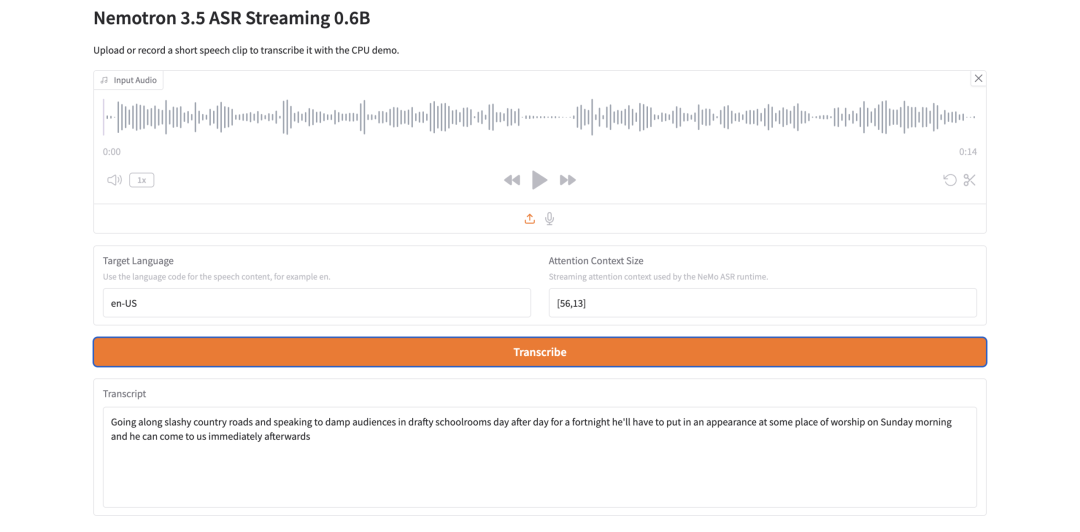
12. Nemotron 3.5 ASR Streaming 0.6B: تعرف خفيف على الكلام بالبث المتدفق
Nemotron 3.5 ASR Streaming 0.6B هو نموذج للتعرف الآلي على الكلام من NVIDIA. صُمم للنسخ النصي المتدفق بزمن استجابة منخفض، ويستخدم بنية FastConformer-RNNT واعية بالذاكرة المخبئية.
الفكرة التصميمية الأساسية هي إعادة استخدام السياق. أثناء الاستدلال المتدفق، يعيد النموذج استخدام سياق المرمّز بدلًا من إعادة حساب مقاطع الصوت المتداخلة، ما يساعد على تقليل الحسابات الزائدة وتحسين الأداء في الزمن الحقيقي.
مداخل موسوعية رائجة
سلّطت HyperAI الضوء أيضًا هذا الأسبوع على خمسة مداخل رائجة في موسوعة الذكاء الاصطناعي:
- النموذج اللغوي الكبير (LLM)
- نموذج الفعل العالمي (WAM)
- المتوسط التوافقي
- الفحص الافتراضي
- التعلم المعزز من تغذية راجعة صادرة عن الذكاء الاصطناعي (RLAIF)
تجمع ويكي HyperAI مئات المفاهيم والشروحات المتعلقة بالذكاء الاصطناعي. وهي مفيدة للقراء الذين يريدون طريقة سريعة لفهم المصطلحات التي تظهر كثيرًا في الأوراق البحثية والدروس التعليمية ووثائق النماذج.
مواعيد نهائية لمؤتمرات الذكاء الاصطناعي في يوليو
يسرد التحديث الأصلي أيضًا عدة مواعيد نهائية لمؤتمرات في الذكاء الاصطناعي وعلوم الحاسوب خلال يوليو. جميع أوقات المواعيد النهائية مذكورة بتوقيت AoE.
| التاريخ | الوقت | المؤتمر |
|---|---|---|
| 09 يوليو | 23:59:59 | POPL 2027 |
| 10 يوليو | 23:59:59 | ICSE 2027 |
| 17 يوليو | 23:59:59 | SIGMOD 2027 |
| 28 يوليو | 23:59:59 | AAAI 2027 |
نبذة عن HyperAI
HyperAI مجتمع للذكاء الاصطناعي والحوسبة عالية الأداء. يوفر موقعه موارد عامة للمطورين والباحثين ومتعلمي الذكاء الاصطناعي.
وفقًا للمصدر الأصلي، جمعت HyperAI أو دعمت بالفعل:
- أكثر من 2,100 مجموعة بيانات عامة مع عقد تسريع محلية
- أكثر من 700 درس تعليمي كلاسيكي وشائع على الإنترنت
- أكثر من 300 دراسة حالة لأوراق AI4Science
- أكثر من 700 مدخل موسوعي متعلق بالذكاء الاصطناعي
- مرآة كاملة للوثائق الصينية الخاصة بـ Apache TVM
الأسئلة الشائعة
ما هو Irodori-TTS-500M-v3؟
Irodori-TTS-500M-v3 هو نموذج ياباني مفتوح لتحويل النص إلى كلام، قائم على بنية RF-DiT. يدعم توليد الكلام الياباني، واستنساخ الصوت دون أمثلة مسبقة باستخدام مرجع قصير، والتحكم في الأسلوب بالاعتماد على الرموز التعبيرية.
هل يستطيع Irodori-TTS استنساخ صوت دون ضبط دقيق؟
نعم. يصف التحديث الأصلي Irodori-TTS بأنه يدعم استنساخ الصوت دون أمثلة مسبقة من مقطع صوتي مرجعي قصير، عادةً بين 3 و10 ثوانٍ تقريبًا. ومع ذلك، تظل النتيجة معتمدة على جودة الصوت المرجعي ووضوحه.
فيمَ يُستخدم SAM-Audio؟
يُستخدم SAM-Audio لفصل مصادر الصوت بالاعتماد على المطالبات. يمكن للمستخدمين وصف الصوت الذي يريدون استخراجه، أو تقديم إشارات بصرية، أو تحديد نطاق زمني لعزل صوت مستهدف من تسجيل مختلط.
ما الفرق بين التثبيت غير الحاد للفيديو وتجزئة الفيديو؟
عادةً ما تفصل تجزئة الفيديو الكائنات إلى مناطق أو أقنعة، بينما يقدّر التثبيت غير الحاد للفيديو قناع ألفا أكثر تفصيلًا. ويكون التثبيت غير الحاد مهمًا على وجه الخصوص لاستخراج المقدمة بشكل نظيف، والحفاظ على تفاصيل الشعر، والحواف شبه الشفافة، والدمج التركيبي.
ماذا يولد PrismAudio؟
يولد PrismAudio صوتًا للفيديو. ويحاول مواءمة الصوت المولد مع المحتوى الدلالي للفيديو وتوقيته وإحساسه الجمالي وإشاراته المكانية.
لماذا يُعد Unlimited-OCR مفيدًا للوثائق الطويلة؟
صُمم Unlimited-OCR للتحليل طويل المدى، وليس فقط للتعرف الضوئي على الحروف في صفحة واحدة معزولة. ويمكن أن يكون مفيدًا عند التعامل مع الأوراق البحثية أو التقارير أو الملفات الممسوحة ضوئيًا أو الجداول الطويلة أو الصور المشتقة من ملفات PDF متعددة الصفحات.
هل Nemotron 3.5 ASR Streaming 0.6B مناسب للنسخ النصي للكلام في الزمن الحقيقي؟
نعم، فقد صُمم بزمن استجابة منخفض.
التعرّف الآلي على الكلام عبر البث المباشر. تعيد بنية FastConformer-RNNT الواعية بالذاكرة المؤقتة استخدام السياق أثناء الاستدلال بالبث، مما يساعد على تقليل الحسابات المكررة.
أدوات ذات صلة
- Irodori-TTS: نظام ياباني مفتوح المصدر لتحويل النص إلى كلام، يدعم استنساخ الصوت اعتمادًا على صوت مرجعي والتحكم في الأسلوب.
- Irodori-TTS-500M-v3 على Hugging Face: صفحة النموذج الخاصة بنقطة تحقق تحويل النص الياباني إلى كلام بإصدار 500M v3.
- SAM-Audio: مستودع Meta للاستدلال والأمثلة الخاصة بنموذج Segment Anything in Audio.
- MatAnyone 2: صفحة مشروع إطار عمل MatAnyone 2 لعزل العناصر في الفيديو.
- InSpatio-World: صفحة مشروع لمحاكاة عوالم رباعية الأبعاد تفاعلية في الزمن الحقيقي.
- DiaMoE-TTS: مستودع GitHub لتوليد الكلام متعدد اللهجات اعتمادًا على الأبجدية الصوتية الدولية IPA.
- PrismAudio: صفحة مشروع لتوليد الصوت من الفيديو باستخدام سلسلة تفكير مفككة ومكافآت متعددة الأبعاد.
- DreamOmni2: مشروع مفتوح المصدر لتوليد الصور وتحريرها متعدد الوسائط والقائم على التعليمات.
- PixelRefer: إطار عمل أكاديمية Alibaba DAMO لفهم الكائنات في الصور والفيديوهات بدقة تفصيلية.
- Unlimited-OCR: مشروع Baidu للتعرّف البصري على النصوص وتحليل المستندات طويلة الأمد.
- EdgeTAM: نموذج Meta على الجهاز لتتبّع أي شيء، مخصص لتجزئة الصور والفيديوهات القابلة للتوجيه بالمطالبات.
- Step-Audio-EditX: نموذج StepFun لاستنساخ الصوت دون أمثلة مسبقة وتحرير الصوت التعبيري.
- Nemotron 3.5 ASR Streaming 0.6B: صفحة نموذج NVIDIA على Hugging Face للتعرّف الآلي على الكلام عبر البث بزمن استجابة منخفض.
روابط ذات صلة
- مقال BAAI Hub الأصلي: المقال المصدر لهذا التحديث الأسبوعي من HyperAI.
- الموقع الرسمي لـ HyperAI: البوابة الرئيسية لدروس HyperAI والأوراق البحثية ومجموعات البيانات وموارد الذكاء الاصطناعي.
- HyperAI Wiki: بوابة موسوعية للذكاء الاصطناعي تغطي المفاهيم الشائعة والمصطلحات البحثية.
- متتبّع مؤتمرات HyperAI: متتبّع لمواعيد تسليم مؤتمرات الذكاء الاصطناعي وعلوم الحاسوب.
- صفحة أبحاث Meta SAM-Audio: صفحة البحث الرسمية لنموذج Segment Anything Model Audio.
- ورقة SAM-Audio على arXiv: ورقة بحثية تصف النموذج الأساسي SAM-Audio.
- ورقة MatAnyone 2 على arXiv: ورقة MatAnyone 2 ومقيّم جودة العزل المُتعلَّم الخاص به.
- ورقة Unlimited-OCR على arXiv: تقرير تقني عن Unlimited OCR والتحليل طويل الأمد.
الملخص
يجمع هذا التحديث الأسبوعي مجموعة مفيدة من عروض الذكاء الاصطناعي وموارد النماذج الجديدة، ولا سيما في مجالات توليد الصوت، والتعرّف على الكلام، ومعالجة الفيديو، وفهم الصور، والتعرّف البصري على النصوص في المستندات الطويلة.
أبرز الأدوات العملية هي Irodori-TTS لتوليد الأصوات اليابانية، وSAM-Audio لفصل الأصوات اعتمادًا على المطالبات، وMatAnyone 2 لعزل الفيديوهات بدقة ونظافة، وUnlimited-OCR للمستندات الطويلة، وNemotron 3.5 ASR للتعرّف على الكلام عبر البث.
عمومًا، هذه الجولة مفيدة للقراء الذين يريدون اكتشاف نماذج الذكاء الاصطناعي الجديدة الجديرة بالتجربة بسرعة، ومعرفة ما يفعله كل نموذج، وأين يمكن تجربته.