DiffusionGemma explicado: o Google está substituindo a previsão do próximo token por geração de texto com IA mais rápida?
DiffusionGemma é o modelo experimental aberto de geração de texto do Google DeepMind e do Google AI que usa difusão discreta em vez de decodificação autorregressiva puramente token a token. Este artigo explica como o DiffusionGemma funciona, por que ele pode gerar texto mais rapidamente em GPUs, o que significa a tela de 256 tokens, como ele difere da previsão do próximo token e por que o Google ainda não está simplesmente substituindo o Gemma padrão ou os LLMs tradicionais. Conheça os trade-offs para desenvolvedores, equipes de produtos de IA, inferência local, edição interativa, geração de código e fluxos de trabalho rápidos com IA.

DiffusionGemma explicado: o Google está substituindo a previsão do próximo token por uma geração de texto por IA mais rápida?
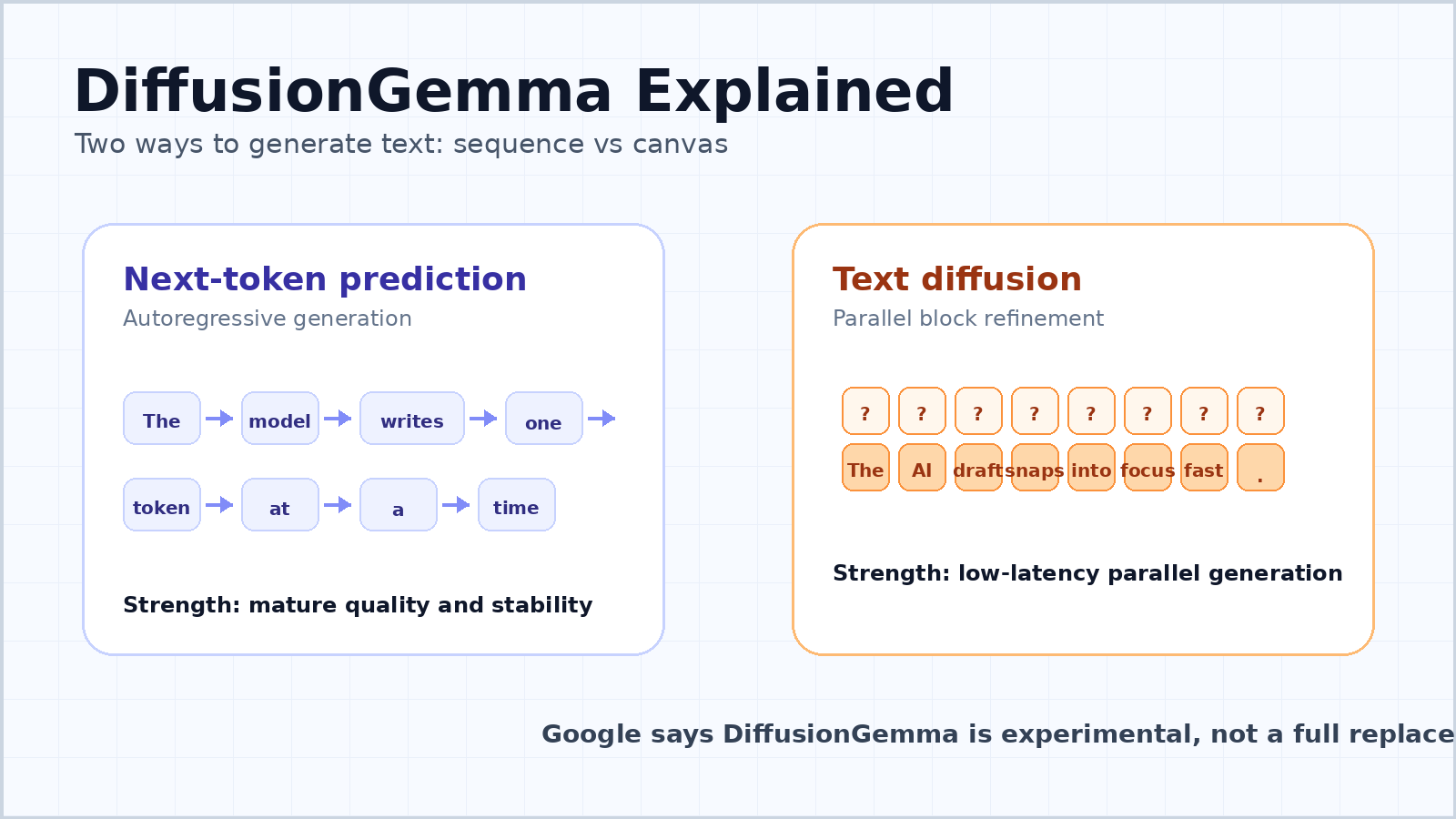
A resposta curta: não, mas a direção importa
DiffusionGemma não é o Google declarando a morte da previsão do próximo token. É melhor entendê-lo como um sinal experimental sério: o Google está testando um caminho diferente para a geração de texto por IA, no qual velocidade, paralelismo e fluxos de trabalho locais interativos importam mais do que o ritmo familiar de um token por vez dos LLMs padrão.
O Google descreve o DiffusionGemma como um modelo aberto experimental baseado em difusão de texto. Em vez de produzir texto estritamente da esquerda para a direita, ele gera blocos de texto refinando uma tela de tokens ruidosos ou de espaço reservado. A promessa prática é simples: se um modelo consegue trabalhar em muitas posições ao mesmo tempo, ele pode usar a computação da GPU com mais eficiência e reduzir a latência de inferência em alguns casos de uso.
Mas isso não significa que os modelos de linguagem autorregressivos serão substituídos amanhã. A própria publicação de lançamento do Google é cuidadosa quanto ao compromisso envolvido. Ela afirma que os modelos Gemma 4 padrão continuam sendo a recomendação para aplicações que exigem a máxima qualidade de produção. Essa frase importa. O DiffusionGemma é um modelo de pesquisa e desenvolvimento focado em velocidade, não um substituto universal para o paradigma dominante dos LLMs.
Por que a previsão do próximo token se tornou o padrão
A maioria dos chatbots e grandes modelos de linguagem modernos é autorregressiva. Eles leem o prompt, depois preveem o próximo token, depois o token seguinte, e continuam até que a resposta esteja completa. Esse é o modelo mental simples por trás da previsão do próximo token.
O motivo pelo qual isso se tornou dominante não é acidental. Modelos autorregressivos são flexíveis, estáveis e fáceis de escalar. Eles conseguem gerar texto de comprimento variável, preservar a coerência da esquerda para a direita e funcionar bem em chat, programação, tradução, resumo, raciocínio e uso de ferramentas. A abordagem também se alinha naturalmente à forma como a linguagem escrita se desenvolve.
O ponto fraco é a latência. Um modelo token a token tem uma dependência sequencial: o token 100 depende dos tokens 1 a 99, e o token 101 depende do token 100. Mesmo quando a GPU é poderosa, o modelo precisa avançar pela sequência. Para um usuário fazendo uma pergunta, grande parte do hardware pode permanecer subutilizada porque o modelo está esperando a movimentação de memória e a decodificação sequencial.
O que o DiffusionGemma faz de diferente
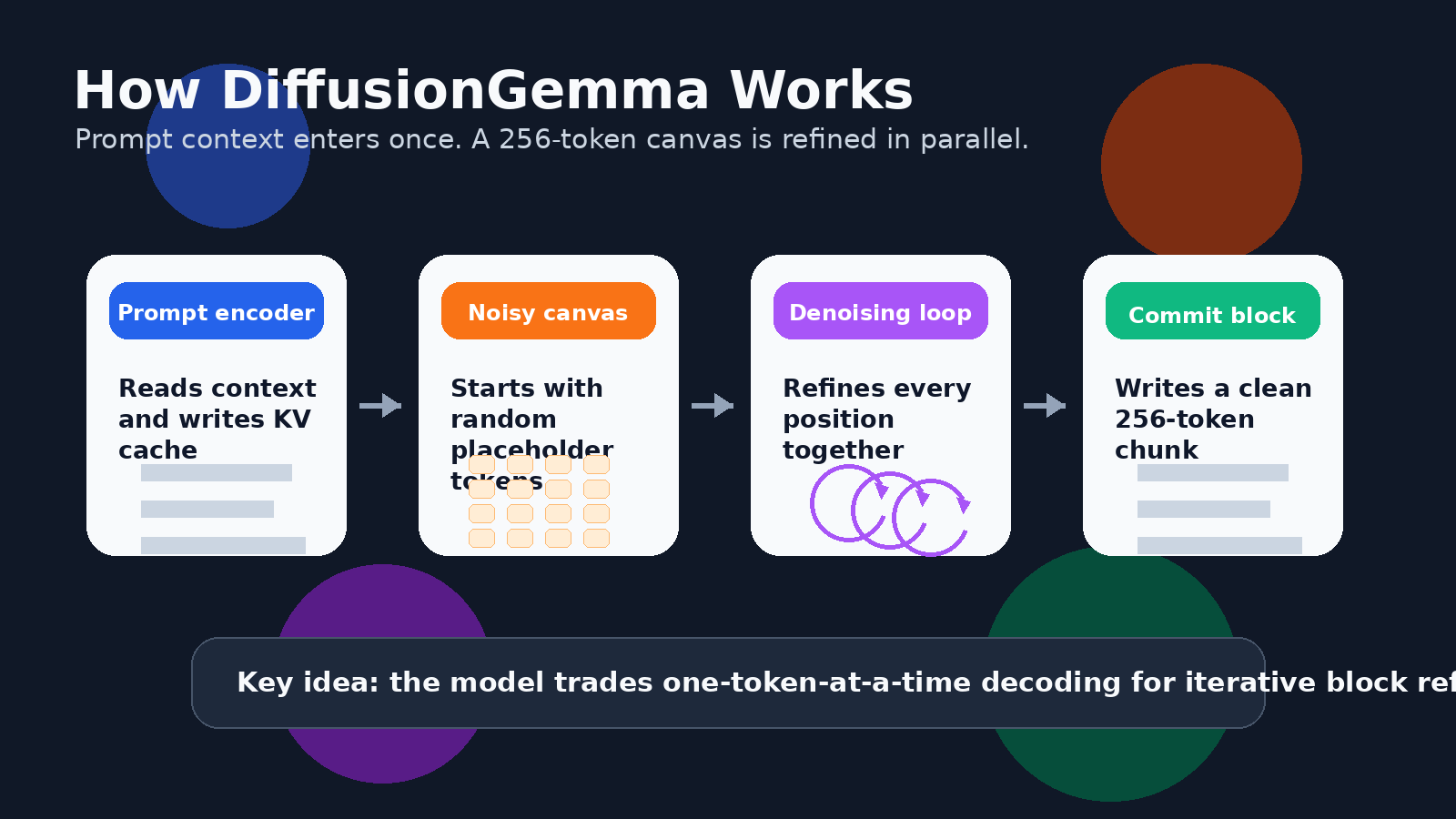
DiffusionGemma se inspira nos modelos de difusão, a família de modelos generativos que ficou famosa na geração de imagens e vídeos. Em vez de desenhar a resposta um token por vez, um modelo de difusão começa com ruído ou incerteza e a refina gradualmente até obter uma saída coerente.
Para texto, isso significa que o modelo pode trabalhar em um bloco de tokens em paralelo. O guia para desenvolvedores do Google descreve uma tela de 256 tokens. O modelo começa com uma tela de tokens aleatórios de espaço reservado e, em seguida, remove repetidamente o ruído de todo o bloco. Posições de tokens confiantes tornam-se âncoras, posições incertas são refinadas novamente, e o bloco gradualmente ganha nitidez.
Isso não é o mesmo que gerar um ensaio longo inteiro de uma só vez. O DiffusionGemma usa uma abordagem autorregressiva em blocos para saídas mais longas. Depois que um bloco de 256 tokens é totalmente refinado, ele é confirmado no cache KV, e o modelo passa para o próximo bloco. Portanto, ele ainda tem uma estrutura da esquerda para a direita entre blocos, mas dentro de cada bloco consegue refinar muitos tokens em conjunto.
Por que ele pode ser mais rápido
A questão da velocidade está relacionada ao gargalo de hardware. Modelos autorregressivos tradicionais podem ser limitados pela largura de banda da memória, porque o modelo carrega repetidamente os pesos enquanto gera um token por vez. O DiffusionGemma tenta deslocar mais trabalho para a computação, dando à GPU uma carga de trabalho paralela maior dentro de cada bloco.
O Google afirma que o DiffusionGemma pode oferecer geração de tokens até quatro vezes mais rápida em GPUs dedicadas, com exemplos que incluem mais de 1000 tokens por segundo em uma única NVIDIA H100 e mais de 700 tokens por segundo em uma RTX 5090. Esses números não são uma promessa universal para todas as tarefas, dispositivos ou tamanhos de lote. Eles são um sinal sobre um padrão de geração específico e favorável ao hardware.
É por isso que o DiffusionGemma é especialmente interessante para fluxos de trabalho locais e interativos. Se um usuário está pedindo edições rápidas, preenchimentos de código, rascunhos estruturados ou iterações velozes, a GPU pode ter capacidade de computação ociosa que um modelo autorregressivo não consegue aproveitar totalmente. Um modelo de linguagem por difusão pode ser uma opção mais adequada para esse tipo de carga de trabalho com lote pequeno e sensível à velocidade.
O papel da atenção bidirecional e da autocorreção
Uma das diferenças mais importantes é a atenção bidirecional. Durante a remoção de ruído, os tokens na tela podem prestar atenção a outras posições no bloco, não apenas aos tokens anteriores. Isso muda a sensação da geração. O modelo pode usar contexto dos dois lados de um trecho ausente ou incerto.
Isso é especialmente útil para problemas de texto não lineares. O Google aponta edição em linha, preenchimento de código, grafos matemáticos e até geração restrita no estilo Sudoku como exemplos em que posições futuras importam. Um modelo autorregressivo padrão pode ser forte em muitas tarefas, mas, uma vez que emite um token inicial, geralmente fica preso a ele. A remoção de ruído no estilo de difusão cria espaço para revisão antes que o bloco seja finalizado.
É também por isso que a expressão autocorreção aparece com frequência em torno do DiffusionGemma. O modelo não está apenas digitando. Ele avalia repetidamente toda a tela, mantém posições confiantes, substitui as incertas e refina o bloco até convergir.
O que significa o design MoE de 26B
O DiffusionGemma é baseado em um design Mixture of Experts de 26B da família Gemma 4, com apenas um subconjunto ativo menor usado durante a inferência. A documentação de IA do Google o descreve como um modelo de 26B com cerca de 4B de parâmetros ativos, enquanto o guia do desenvolvedor explica que o modelo foi projetado para caber dentro de limites de 18 GB de VRAM quando quantizado.
A ideia central é eficiência. Um modelo MoE esparso pode ter uma grande contagem total de parâmetros enquanto ativa apenas especialistas selecionados para um determinado token ou tarefa. Isso pode melhorar a capacidade sem exigir que o modelo completo esteja ativo em cada etapa.
Para desenvolvedores, isso importa porque o DiffusionGemma não é apenas uma demonstração de laboratório. Ele é lançado como um modelo de pesos abertos sob uma licença Apache 2.0, com documentação para vLLM, Hugging Face, Google Cloud Model Garden e outros caminhos de implantação. O Google está claramente convidando o ecossistema a testar se a geração baseada em difusão pode se tornar prática em aplicações reais.
Onde o DiffusionGemma faz sentido

Os melhores casos de uso não são necessariamente a escrita premium de formato longo. São tarefas críticas em velocidade nas quais o usuário se beneficia de iterações rápidas. A edição em linha é um exemplo. Em vez de esperar que um modelo reescreva um parágrafo token por token, um modelo de difusão pode refinar rapidamente um trecho inteiro.
O preenchimento de código é outro forte candidato. Um desenvolvedor pode precisar que um modelo preencha o meio de uma função ou ajuste um bloco de código com consciência do que vem antes e depois. A atenção bidirecional é útil aqui porque o modelo pode raciocinar sobre os dois lados da seção ausente.
A geração estruturada e restrita também é interessante. Se a saída tem múltiplas dependências, como uma tabela, quebra-cabeça, modelo ou esquema formal, o refinamento em bloco pode dar ao modelo mais espaço para coordenar posições. É por isso que o DiffusionGemma não se resume a ser mais rápido. Ele também aponta para um estilo diferente de interação na geração.
Onde os modelos autorregressivos ainda vencem
A contrapartida é a qualidade. O Google afirma explicitamente que o DiffusionGemma prioriza velocidade e geração de layout em paralelo, e que sua qualidade geral de saída é inferior à do Gemma 4 padrão. Esse é o principal motivo pelo qual ele não deve ser descrito como uma substituição direta da previsão do próximo token.
Modelos autorregressivos ainda têm grandes vantagens. Eles são profundamente otimizados para produção, fortes em muitas tarefas de uso geral e apoiados por pilhas de serviço maduras. Eles também funcionam naturalmente para fluxos conversacionais em que o modelo estende o texto em uma sequência contínua.
O futuro realista provavelmente não é um método de decodificação substituindo o outro. É mais provável que sistemas de IA encaminhem diferentes tarefas para diferentes estratégias de geração. Modelos autorregressivos podem continuar sendo o padrão para chats gerais e raciocínio de alta qualidade, enquanto modelos de linguagem por difusão podem impulsionar edição rápida, geração local, preenchimento de código e outras cargas de trabalho interativas.
O que os desenvolvedores devem acompanhar a seguir
A maior questão é se os modelos de linguagem por difusão conseguem reduzir a diferença de qualidade mantendo a vantagem de latência. Só a velocidade não é suficiente se a saída precisar de correções demais. Mas, se a qualidade melhorar, a arquitetura poderá se tornar muito importante para IA local, assistentes de IDE, edição de documentos e interfaces em tempo real.
A segunda questão é a infraestrutura de serviço. O suporte ao vLLM é importante porque os modelos de linguagem por difusão exigem um comportamento de decodificação diferente: atenção bidirecional, remoção iterativa de ruído, amostragem personalizada e lógica de confirmação em nível de bloco. Se os frameworks de inferência facilitarem isso, mais desenvolvedores farão experimentos.
A terceira questão é o design de produto. Um modelo de texto por difusão não é apenas um chatbot mais rápido. Sua interface natural pode ser mais parecida com um editor inteligente que revisa uma tela de trabalho, preenche lacunas e melhora rascunhos no próprio lugar. Isso poderia mudar a forma como os usuários vivenciam as ferramentas de escrita e programação com IA.
Conclusão final
O DiffusionGemma não significa que o Google esteja substituindo a previsão do próximo token hoje. Significa que o Google está tornando a difusão de texto prática o suficiente para que desenvolvedores a testem em fluxos de trabalho reais.
A mudança importante não é apenas texto mais rápido. É a ideia de que a geração de linguagem nem sempre precisa se parecer com um modelo digitando da esquerda para a direita. Às vezes, a melhor interação é uma tela de trabalho que é refinada em paralelo.
Se esse padrão melhorar, a geração de texto por IA poderá se tornar mais rápida, mais interativa e mais adequada a dispositivos locais. Mas, por enquanto, o DiffusionGemma deve ser entendido como um modelo aberto experimental com uma mensagem muito clara: o futuro da geração de linguagem pode incluir mais de um caminho de decodificação.
Comparação rápida
Pergunta | LLMs autorregressivos | DiffusionGemma |
Padrão de geração | Prevê o próximo token sequencialmente | Refina uma tela de tokens em paralelo |
Ponto forte | Saídas de produção de alta qualidade | Geração interativa de baixa latência |
Fluxo de contexto | Principalmente da esquerda para a direita durante a decodificação | Bidirecional dentro de cada tela de remoção de ruído |
Melhor aplicação | Chat geral, raciocínio, serviço maduro | Edição, preenchimento de código, fluxos de trabalho locais rápidos |
Status | Paradigma dominante em produção | Modelo aberto experimental |
CTA
Se você está criando produtos de IA, não trate o DiffusionGemma como um simples modelo substituto. Trate-o como um novo padrão de geração a ser testado onde a latência de inferência, a responsividade local e a edição não linear são mais importantes.
Para equipes que criam ferramentas para desenvolvedores, assistentes de escrita, fluxos de trabalho de programação ou experiências de IA no dispositivo, esse é o tipo de arquitetura que vale a pena avaliar cedo.
FAQ
O que é o DiffusionGemma?
O DiffusionGemma é o modelo aberto experimental de geração de texto do Google que usa difusão discreta para refinar blocos de tokens em paralelo, em vez de depender apenas da geração token por token.
O Google está substituindo a previsão do próximo token?
Não. O Google ainda recomenda o Gemma 4 padrão para obter a máxima qualidade em produção. O DiffusionGemma é experimental e otimizado para fluxos de trabalho em que a velocidade é crítica.
Por que o DiffusionGemma é mais rápido?
Ele trabalha em uma tela de 256 tokens em paralelo, deslocando mais trabalho para a computação em GPU em vez de gerar estritamente um token por vez.
O que é uma tela de 256 tokens?
É um bloco de posições de tokens que o modelo inicializa, remove ruído, refina e então confirma antes de passar para o próximo bloco.
Quem deve testar o DiffusionGemma?
Desenvolvedores que trabalham com inferência local, edição inline, preenchimento de código, elaboração rápida e outras ferramentas de IA interativas de baixa latência devem prestar atenção.
Ferramentas relacionadas
- vLLM
- Colab
- Kaggle
Fontes
- DeepMind