DiffusionGemma解説:Googleは次トークン予測をより高速なAIテキスト生成に置き換えようとしているのか?
DiffusionGemmaは、Google DeepMindとGoogle AIによる実験的なオープンテキスト生成モデルで、純粋なトークン単位の自己回帰デコードではなく離散拡散を使用します。本記事では、DiffusionGemmaの仕組み、GPU上でテキストをより高速に生成できる理由、256トークンのキャンバスが何を意味するのか、次トークン予測とどう異なるのか、そしてGoogleが標準のGemmaや従来型LLMをまだ単純に置き換えようとしているわけではない理由を解説します。開発者、AIプロダクトチーム、ローカル推論、インタラクティブ編集、コード生成、高速なAIワークフローにとってのトレードオフを学べます。

DiffusionGemma解説:Googleは次トークン予測をより高速なAIテキスト生成に置き換えようとしているのか?
短い答え:いいえ、ただしその方向性は重要
DiffusionGemmaは、Googleが次トークン予測の終焉を宣言しているものではありません。むしろ、重要な実験的シグナルとして理解するほうが適切です。Googleは、標準的なLLMでおなじみの1トークンずつ生成するリズムよりも、速度、並列性、インタラクティブなローカルワークフローを重視するAIテキスト生成の別の道を試しているのです。
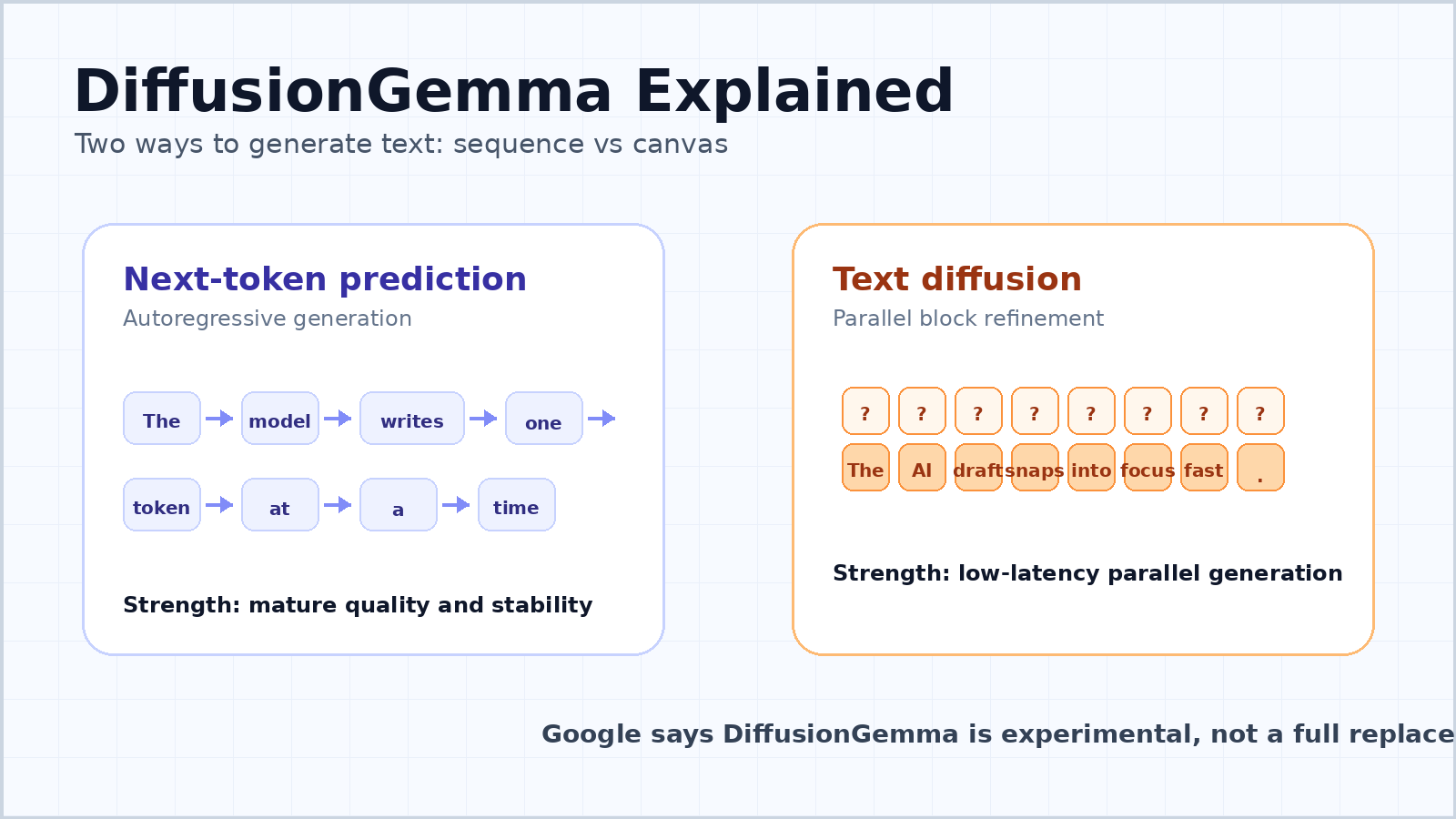
GoogleはDiffusionGemmaを、テキスト拡散を中心に構築された実験的なオープンモデルと説明しています。テキストを厳密に左から右へ生成するのではなく、ノイズを含む、またはプレースホルダーのトークンでできたキャンバスを洗練していくことで、テキストのブロックを生成します。実用面での約束はシンプルです。モデルが多くの位置を同時に処理できれば、GPU計算をより効率的に使い、一部のユースケースで推論レイテンシを削減できるということです。
しかし、それは自己回帰言語モデルが明日にも置き換えられることを意味しません。Google自身の発表記事も、そのトレードオフについて慎重です。最高の本番品質が求められるアプリケーションには、標準のGemma 4モデルが引き続き推奨されると述べています。この一文は重要です。DiffusionGemmaは速度重視の研究・開発者向けモデルであり、支配的なLLMパラダイムの万能な代替ではありません。
なぜ次トークン予測が標準になったのか
現代のチャットボットや大規模言語モデルのほとんどは自己回帰型です。プロンプトを読み取り、次のトークンを予測し、その次のトークンを予測し、回答が完成するまで続けます。これが次トークン予測の背後にあるシンプルな考え方です。
それが主流になったのは偶然ではありません。自己回帰モデルは柔軟で、安定しており、スケールしやすいからです。可変長のテキストを生成でき、左から右への一貫性を保ち、チャット、コーディング、翻訳、要約、推論、ツール利用など幅広い用途でうまく機能します。このアプローチは、書き言葉が展開していく自然な流れともよく一致しています。
弱点はレイテンシです。トークンごとに生成するモデルには逐次的な依存関係があります。トークン100はトークン1から99に依存し、トークン101はトークン100に依存します。GPUが強力であっても、モデルはシーケンスを順番に処理しなければなりません。1人のユーザーが1つの質問をする場合、モデルがメモリ移動と逐次デコードを待っているため、多くのハードウェアが十分に活用されないことがあります。
DiffusionGemmaは何が違うのか
DiffusionGemmaは、画像や動画生成で有名になった生成モデルの系統である拡散モデルから着想を得ています。答えを1トークンずつ描き出すのではなく、拡散モデルはノイズや不確実性から始め、それを徐々に一貫した出力へと洗練していきます。
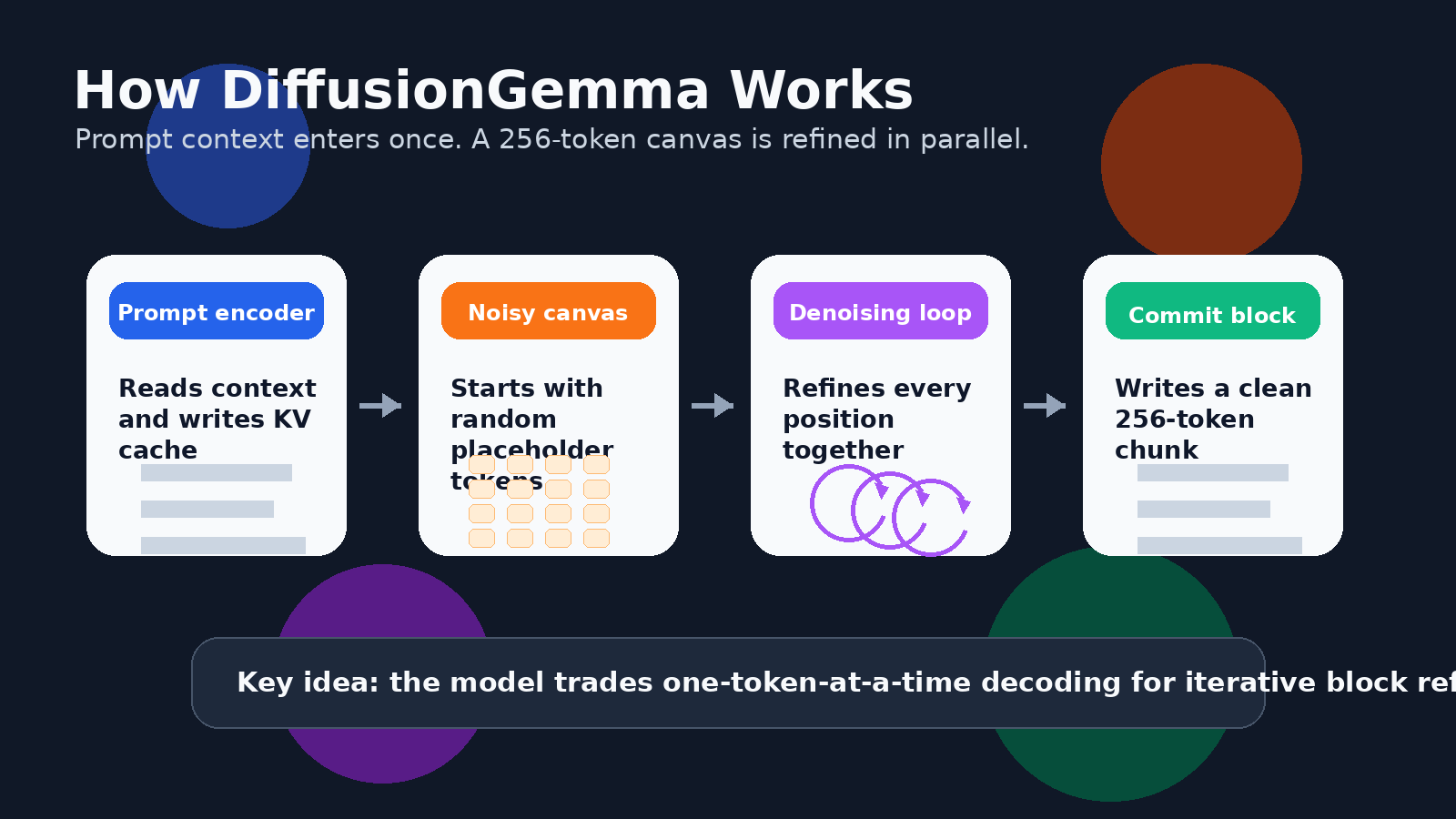
テキストの場合、これはモデルがトークンのブロックを並列に処理できることを意味します。Googleの開発者ガイドでは、256トークンのキャンバスについて説明されています。モデルはランダムなプレースホルダートークンで構成されたキャンバスから開始し、その後ブロック全体を繰り返しノイズ除去します。確信度の高いトークン位置はアンカーとなり、不確実な位置は再度洗練され、ブロックは徐々に明確な形になります。
これは、長いエッセイ全体を一度に生成するのと同じではありません。DiffusionGemmaは、長い出力に対してブロック自己回帰アプローチを使用します。256トークンのブロックが完全に洗練されると、それはKVキャッシュにコミットされ、モデルは次のブロックへ進みます。つまり、ブロック間では依然として左から右への構造を持っていますが、各ブロック内では多くのトークンをまとめて洗練できます。
なぜ高速化できるのか
速度の話は、ハードウェアのボトルネックに関係しています。従来の自己回帰モデルは、1トークンずつ生成するたびにモデルの重みを繰り返し読み込むため、メモリ帯域幅に制約されることがあります。DiffusionGemmaは、各ブロック内でGPUにより大きな並列ワークロードを与えることで、処理のより多くを計算側へ移そうとしています。
Googleによると、DiffusionGemmaは専用GPU上で最大4倍高速なトークン生成を実現でき、例として単一のNVIDIA H100で毎秒1000トークン超、RTX 5090で毎秒700トークン超が挙げられています。これらの数値は、すべてのタスク、デバイス、バッチサイズに対する一律の約束ではありません。特定のハードウェアに適した生成パターンを示すシグナルです。
これが、DiffusionGemma がローカルかつインタラクティブなワークフローで特に興味深い理由です。ユーザーが高速な編集、コード補完、構造化された下書き、または素早い反復を求めている場合、GPU には autoregressive モデルでは十分に使い切れない余剰計算資源があるかもしれません。diffusion language model は、このような低バッチで速度が重視されるワークロードにより適している可能性があります。
双方向アテンションと自己修正の役割
最も重要な違いの一つは bidirectional attention です。ノイズ除去の過程では、キャンバス上のトークンは、それ以前のトークンだけでなく、ブロック内の他の位置にも注意を向けることができます。これにより、生成の感覚が変わります。モデルは、欠落している、または不確実な範囲の両側から文脈を利用できます。
これは、非線形なテキスト問題に特に有用です。Google は、将来の位置が重要になる例として、インライン編集、コード補完、数学的グラフ、さらには数独のような制約付き生成を挙げています。標準的な autoregressive モデルは多くのタスクで強力ですが、一度初期のトークンを出力すると、通常はそれに縛られます。拡散型のノイズ除去では、ブロックが確定する前に修正する余地が生まれます。
これこそが、DiffusionGemma の周辺で self-correction という表現が繰り返し登場する理由でもあります。モデルは単に文字を入力しているわけではありません。キャンバス全体を繰り返し評価し、確信度の高い位置を保持し、不確実な位置を置き換え、収束するまでブロックを洗練させていきます。
26B MoE 設計が意味するもの
DiffusionGemma は、Gemma 4 ファミリーの 26B Mixture of Experts 設計を基盤としており、推論時にはそのうち小さなアクティブサブセットのみが使用されます。Google の AI ドキュメントでは、約 4B のアクティブパラメータを持つ 26B モデルと説明されており、開発者ガイドでは、量子化時に 18GB VRAM の制限内に収まるよう設計されていると説明されています。
重要な考え方は効率性です。疎な MoE モデルは、総パラメータ数を大きく持ちながら、特定のトークンやタスクに対して選択されたエキスパートだけを有効化できます。これにより、各ステップでモデル全体をアクティブにする必要なく、能力を高められる可能性があります。
開発者にとってこれが重要なのは、DiffusionGemma が単なる研究室のデモではないからです。これは Apache 2.0 ライセンスの下でオープンウェイトモデルとして公開されており、vLLM、Hugging Face、Google Cloud Model Garden、その他のデプロイ経路向けのドキュメントも用意されています。Google は、拡散ベースの生成が実際のアプリケーションで実用化できるかどうかを、エコシステムに明確に試してほしいと促しています。
DiffusionGemma が適している場面

最適なユースケースは、必ずしも長文の高品質な文章作成ではありません。ユーザーが素早い反復から恩恵を受ける、速度が重要なタスクです。インライン編集はその一例です。モデルが段落をトークンごとに書き直すのを待つ代わりに、diffusion model は範囲全体を素早く洗練できます。
コード補完も有力な候補です。開発者は、関数の中間部分を埋めたり、前後にある内容を認識したうえでコードブロックを調整したりするモデルを必要とすることがあります。Bidirectional attention は、モデルが欠落部分の両側を踏まえて推論できるため、この場面で有用です。
構造化生成や制約付き生成も興味深い領域です。出力に、表、パズル、テンプレート、形式的スキーマのような複数の依存関係がある場合、block refinement によって、モデルは位置間の調整を行う余地をより多く得られます。だからこそ、DiffusionGemma は単に高速であることだけを意味するものではありません。生成における異なるインタラクションスタイルの可能性も示しています。
autoregressive モデルがまだ優位な場面
トレードオフは品質です。Google は、DiffusionGemma が速度と並列的なレイアウト生成を優先しており、全体的な出力品質は標準的な Gemma 4 より低いと明言しています。これが、next-token prediction を完全に置き換えるものとして説明すべきではない中心的な理由です。
Autoregressive モデルには、依然として大きな利点があります。本番環境向けに高度に最適化されており、多くの汎用タスクで強力で、成熟したサービングスタックに支えられています。また、モデルが一定の順序でテキストを拡張していく会話フローにも自然に適しています。
現実的な未来は、おそらく一方のデコーディング手法がもう一方を置き換えるものではありません。むしろ、AI システムが異なるタスクを異なる生成戦略にルーティングする可能性の方が高いでしょう。Autoregressive モデルは、高品質な一般チャットや推論のデフォルトであり続ける一方、diffusion language model は高速編集、ローカル生成、コード補完、その他のインタラクティブなワークロードを支える可能性があります。
開発者が次に注目すべきこと
最大の問いは、diffusion language modelがレイテンシの優位性を保ちながら品質の差を埋められるかどうかです。出力に多くの修正が必要であれば、速度だけでは十分ではありません。しかし品質が向上すれば、このアーキテクチャはローカルAI、IDEアシスタント、文書編集、リアルタイムインターフェースにとって非常に重要になる可能性があります。
2つ目の問いは、提供インフラです。vLLMのサポートが重要なのは、diffusion language modelが異なるデコード挙動を必要とするためです。具体的には、bidirectional attention、反復的なノイズ除去、カスタムサンプリング、ブロック単位のコミットロジックです。推論フレームワークがこれを容易にすれば、より多くの開発者が実験するようになるでしょう。
3つ目の問いは、プロダクト設計です。拡散テキストモデルは、単に高速なチャットボットではありません。その自然なインターフェースは、キャンバスを修正し、空白を埋め、下書きをその場で改善するスマートエディタに近いものかもしれません。それにより、ユーザーがAIライティングやコーディングツールを体験する方法が変わる可能性があります。
最終的な要点
DiffusionGemmaは、Googleが今日next-token predictionを置き換えるという意味ではありません。Googleがtext diffusionを、開発者が実際のワークフローでテストできるほど実用的にしているという意味です。
重要な変化は、単にテキストが速くなることだけではありません。言語生成は、常にモデルが左から右へ入力していくように見える必要はない、という考え方です。場合によっては、並列に洗練されていくキャンバスのほうが、より良いインタラクションになります。
このパターンが改善されれば、AI text generationはより高速で、よりインタラクティブになり、ローカルデバイスにもより適したものになる可能性があります。ただし現時点では、DiffusionGemmaは非常に明確なメッセージを持つexperimentalなopen modelとして理解すべきです。そのメッセージとは、言語生成の未来には複数のデコード経路が含まれる可能性があるということです。
簡単な比較
問い | 自己回帰型LLM | DiffusionGemma |
生成パターン | 次のトークンを順番に予測する | トークンのキャンバスを並列に洗練する |
強み | 高品質な本番向け出力 | 低レイテンシのインタラクティブ生成 |
コンテキストの流れ | デコード中は主に左から右へ | 各ノイズ除去キャンバス内で双方向 |
最適な用途 | 一般的なチャット、推論、成熟した提供環境 | 編集、コード補完、迅速なローカルワークフロー |
状況 | 本番環境で支配的なパラダイム | 実験的なオープンモデル |
CTA
AIプロダクトを構築しているなら、DiffusionGemmaを単純な置き換えモデルとして扱わないでください。inference latency、ローカルでの応答性、非線形編集が特に重要となる場面でテストすべき新しい生成パターンとして扱ってください。
開発者ツール、ライティングアシスタント、コーディングワークフロー、オンデバイスAI体験を構築するチームにとって、これは早期にベンチマークする価値のある種類のアーキテクチャです。
FAQ
DiffusionGemmaとは何ですか?
DiffusionGemmaは、トークンごとの生成のみに依存するのではなく、離散拡散を使ってトークンのブロックを並列に洗練する、Googleの実験的なオープンなテキスト生成モデルです。
Googleはnext-token predictionを置き換えるのですか?
いいえ。Googleは本番環境で最大限の品質を得るには、引き続き標準のGemma 4を推奨しています。DiffusionGemmaは実験的なものであり、速度が重要なワークフロー向けに最適化されています。
DiffusionGemmaはなぜ速いのですか?
256トークンのキャンバス上で並列に動作し、厳密に1トークンずつ生成するのではなく、より多くの処理をGPU計算へ移すためです。
256トークンのキャンバスとは何ですか?
モデルが初期化し、ノイズ除去し、洗練させてから、次のブロックに進む前に確定するトークン位置のブロックです。
DiffusionGemmaを試すべきなのは誰ですか?
ローカル推論、インライン編集、コード補完、迅速なドラフト作成、その他の低レイテンシの対話型AIツールに取り組む開発者は注目すべきです。
関連ツール
- vLLM
- Colab
- Kaggle
出典
- 開発者ガイド
- DeepMind
- HFモデル
- vLLMブログ
- NTP調査