DiffusionGemma 详解:Google 是否正在用更快的 AI 文本生成取代下一个词元预测?
DiffusionGemma 是 Google DeepMind 和 Google AI 推出的实验性开放文本生成模型,它使用离散扩散,而不是纯粹逐词元的自回归解码。本文解释 DiffusionGemma 的工作原理、它为何能在 GPU 上更快生成文本、256 词元画布意味着什么、它与下一个词元预测有何不同,以及为什么 Google 目前并不是简单地取代标准 Gemma 或传统 LLM。了解它对开发者、AI 产品团队、本地推理、交互式编辑、代码生成和快速 AI 工作流的取舍。

DiffusionGemma 解析:谷歌正在用更快的 AI 文本生成取代下一个词元预测吗?
简短回答:不是,但方向很重要
DiffusionGemma 并不是谷歌宣布 下一个词元预测 的终结。更准确地说,它是一个重要的 实验性 信号:谷歌正在测试一条不同的 AI 文本生成 路径,在这条路径中,速度、并行性以及交互式 本地工作流 比标准 LLM 那种熟悉的逐词元生成节奏更重要。
谷歌将 DiffusionGemma 描述为一个围绕 文本扩散 构建的 实验性 开放模型。它不是严格从左到右生成文本,而是通过细化由噪声或占位符词元组成的画布来生成文本块。其实际前景很简单:如果模型能够同时处理许多位置,它就能更高效地利用 GPU 计算资源,并在某些用例中降低 推理延迟。
但这并不意味着 自回归 语言模型明天就会被取代。谷歌自己的发布文章对其中的权衡非常谨慎。文章表示,对于要求最高 生产质量 的应用,标准 Gemma 4 模型仍然是推荐选择。这句话很重要。DiffusionGemma 是一个以速度为重点的研究与开发者模型,而不是对主流 LLM 范式的通用替代品。
为什么下一个词元预测成为默认方式
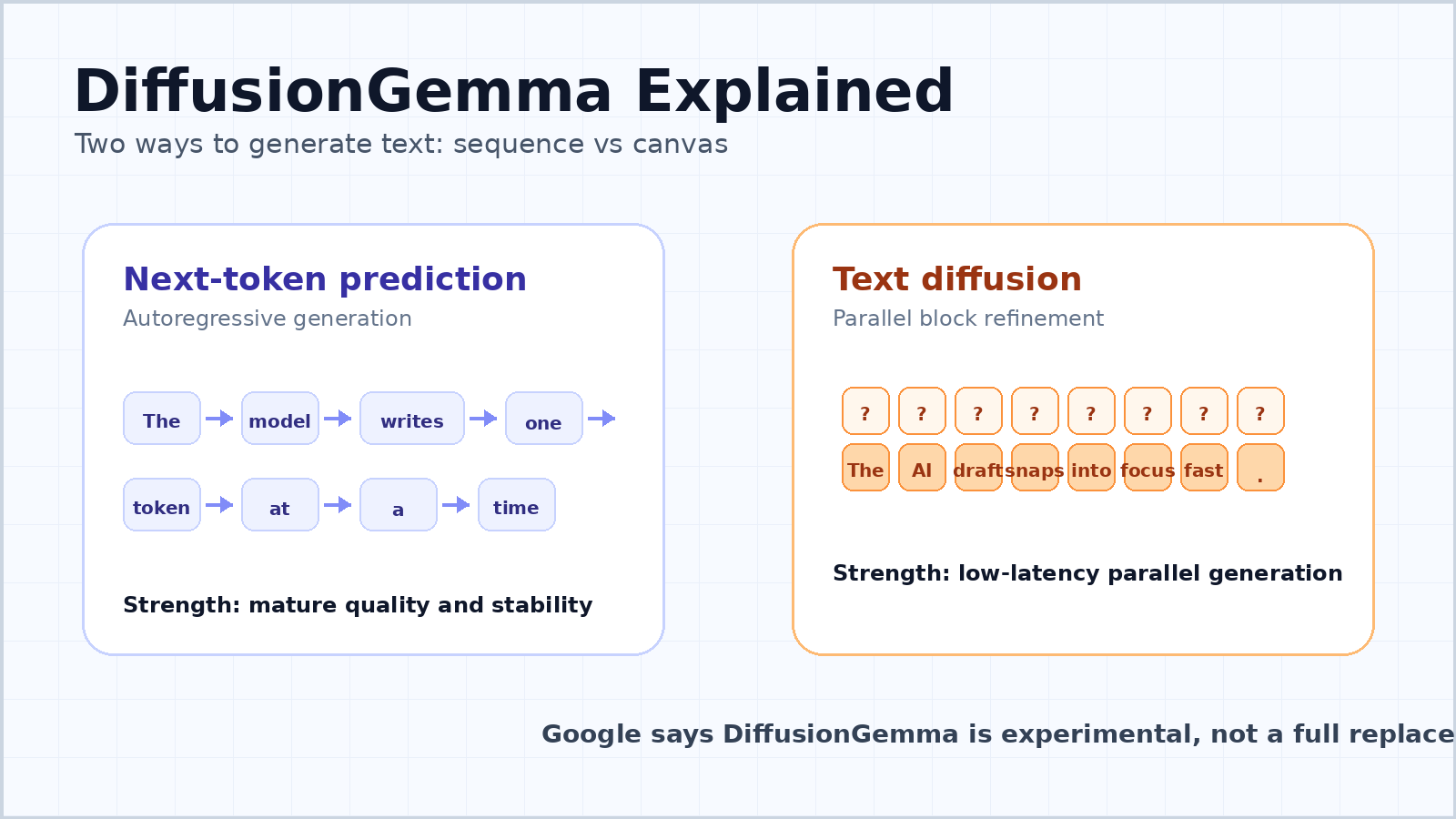
大多数现代聊天机器人和大型语言模型都是 自回归 的。它们读取提示,然后预测下一个词元,再预测其后的下一个词元,如此继续,直到答案完成。这就是 下一个词元预测 背后的简单思维模型。
它之所以成为主导方式并非偶然。自回归 模型灵活、稳定且易于扩展。它们可以生成可变长度文本,保持从左到右的一致性,并在聊天、编程、翻译、摘要、推理和工具使用等场景中表现良好。这种方法也与书面语言展开的方式天然契合。
其弱点是延迟。逐词元 模型具有顺序依赖:第 100 个词元依赖第 1 到第 99 个词元,而第 101 个词元又依赖第 100 个词元。即使 GPU 很强大,模型也必须逐步遍历序列。对于一个用户提出一个问题的情况,由于模型在等待内存移动和顺序解码,大量硬件可能处于未充分利用状态。
DiffusionGemma 有何不同
DiffusionGemma 的灵感来自 扩散模型,这是一类因图像和视频生成而出名的生成模型家族。扩散模型 不是一次绘制一个词元来生成答案,而是从噪声或不确定性开始,并逐步将其细化为连贯的输出。
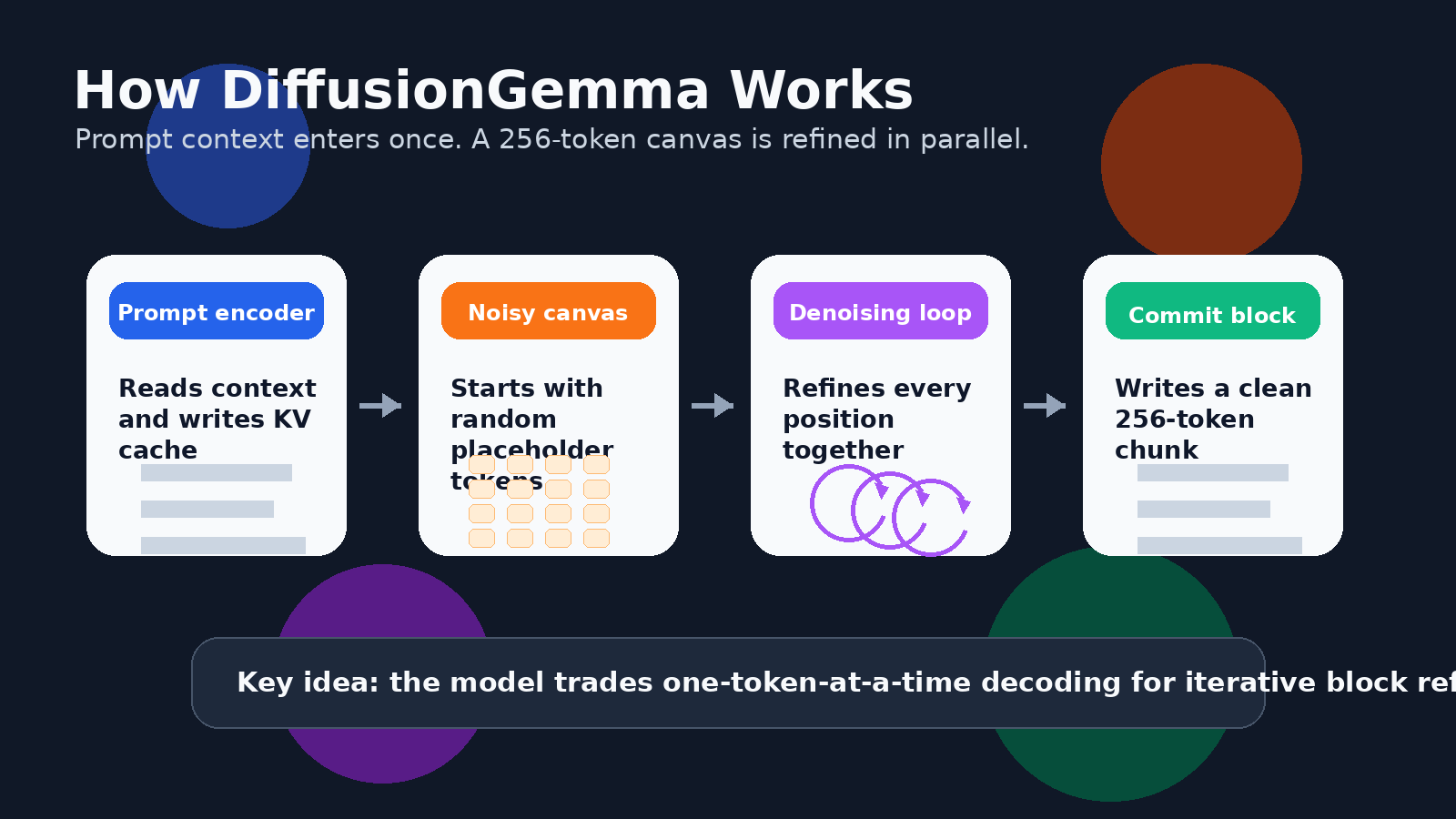
对于文本而言,这意味着模型可以并行处理一个词元块。谷歌的开发者指南描述了一个 256 词元画布。模型从由随机占位符词元组成的画布开始,然后反复对整个块进行去噪。置信度高的词元位置会成为锚点,不确定的位置会再次被细化,整个块也会逐渐清晰成形。
这并不等同于一次性生成一整篇长文章。DiffusionGemma 对较长输出采用 块自回归 方法。一旦一个 256 词元块被完全细化,它就会被提交到 KV 缓存,然后模型进入下一个块。因此,它在块与块之间仍然具有从左到右的结构,但在每个块内部,它可以同时细化许多词元。
为什么它可能更快
速度优势的核心在于硬件瓶颈。传统 自回归 模型可能受限于内存带宽,因为模型在逐词元生成时会反复加载权重。DiffusionGemma 试图通过在每个块内部为 GPU 提供更大的并行工作负载,将更多工作转向计算。
谷歌表示,DiffusionGemma 在专用 GPU 上可以实现最高四倍的词元生成速度,示例包括在单张 NVIDIA H100 上超过每秒 1000 个词元,以及在 RTX 5090 上超过每秒 700 个词元。这些数字并不是对每项任务、每台设备或每种批量大小的全面承诺。它们表明的是一种特定的、对硬件友好的生成模式。
这就是为什么 DiffusionGemma 对本地和交互式工作流尤其有意思。如果一个用户需要快速编辑、代码补全、结构化草稿或快速迭代,GPU 可能还有一些空闲算力,而自回归模型无法充分利用这些算力。对于这种低批量、对速度敏感的工作负载,扩散语言模型可能更匹配。
双向注意力和自我纠正的作用
最重要的区别之一是双向注意力。在去噪过程中,画布上的 token 可以关注块中其他位置,而不只是之前的 token。这改变了生成的感觉。模型可以利用缺失或不确定片段两侧的上下文。
这对于非线性文本问题尤其有用。Google 指出,行内编辑、代码补全、数学图以及类似数独的约束生成,都是未来位置很重要的例子。标准的自回归模型在许多任务上可以很强,但一旦它输出了早期 token,通常就会被它锁定。扩散式去噪在块最终确定之前为修订创造了空间。
这也是为什么自我纠正这个说法一直围绕着 DiffusionGemma 出现。模型并不只是打字。它会反复评估整个画布,保留有把握的位置,替换不确定的位置,并不断细化该块直到收敛。
26B MoE 设计意味着什么
DiffusionGemma 基于 Gemma 4 家族的 26B 专家混合设计,推理期间只使用较小的活跃子集。Google 的 AI 文档将其描述为一个约 4B 活跃参数的 26B 模型,而开发者指南解释称,该模型经过设计,在量化后可适配 18GB 显存限制。
核心理念是效率。稀疏 MoE 模型可以拥有很大的总参数量,同时只为给定 token 或任务激活选定的专家。这可以在不要求整个模型每一步都处于活跃状态的情况下提升能力。
对开发者来说,这一点很重要,因为 DiffusionGemma 不只是一个实验室演示。它以开放权重模型的形式发布,采用 Apache 2.0 许可证,并提供了面向 vLLM、Hugging Face、Google Cloud Model Garden 以及其他部署路径的文档。Google 显然是在邀请生态系统测试基于扩散的生成是否能在真实应用中变得实用。
DiffusionGemma 适合用在哪里

最佳用例不一定是长篇高端写作。它们是对速度要求很高、用户能从快速迭代中受益的任务。行内编辑就是一个例子。与其等待模型逐个 token 重写一个段落,扩散模型可以快速细化整个片段。
代码补全是另一个很有潜力的候选场景。开发者可能需要模型填充函数中间部分,或在理解前后内容的基础上调整一段代码。双向注意力在这里很有用,因为模型可以对缺失部分两侧进行推理。
结构化和约束式生成也很有意思。如果输出存在多个依赖关系,比如表格、谜题、模板或正式 schema,块级细化可以给模型更多空间在各个位置之间进行协调。这就是为什么 DiffusionGemma 不只是关于更快。它还指向了一种不同的生成交互方式。
自回归模型仍然胜出的地方
取舍在于质量。Google 明确表示,DiffusionGemma 优先考虑速度和并行布局生成,其整体输出质量低于标准 Gemma 4。这正是它不应被描述为彻底取代下一个 token 预测的核心原因。
自回归模型仍然有重大优势。它们已经针对生产环境进行了深度优化,在许多通用任务上表现强劲,并受到成熟服务栈的支持。它们也天然适合对话流程,因为模型可以按稳定的顺序延展文本。
现实的未来很可能不是一种解码方法取代另一种。更有可能的是,AI 系统会将不同任务路由到不同的生成策略。自回归模型可能仍然是高质量通用聊天和推理的默认选择,而扩散语言模型可能会驱动快速编辑、本地生成、代码补全以及其他交互式工作负载。
开发者接下来应该关注什么
最大的问题是,扩散语言模型能否在保持延迟优势的同时缩小质量差距。如果输出需要过多修正,仅有速度是不够的。但如果质量提升,这种架构可能会对本地 AI、IDE 助手、文档编辑和实时界面变得非常重要。
第二个问题是服务基础设施。vLLM 支持很重要,因为扩散语言模型需要不同的解码行为:双向注意力、迭代去噪、自定义采样以及块级提交逻辑。如果推理框架能让这些变得简单,更多开发者就会进行尝试。
第三个问题是产品设计。扩散文本模型不只是一个更快的聊天机器人。它的自然交互界面可能更像一个智能编辑器,可以修订画布、填补空缺,并在原处改进草稿。这可能会改变用户体验 AI 写作和编码工具的方式。
最终要点
DiffusionGemma 并不意味着 Google 今天正在取代下一个词元预测。这意味着 Google 正在让文本扩散变得足够实用,以便开发者在真实工作流中进行测试。
重要的转变不仅仅是更快的文本。它是这样一种理念:语言生成并不总是必须看起来像模型从左到右打字。有时,更好的交互是一块并行被精炼的画布。
如果这种模式得到改进,AI 文本生成可能会变得更快、更具交互性,并且更适合本地设备。但目前,DiffusionGemma 应被理解为一个实验性开放模型,传递出一个非常明确的信息:语言生成的未来可能包含不止一种解码路径。
快速比较
问题 | 自回归大语言模型 | DiffusionGemma |
生成模式 | 按顺序预测下一个词元 | 并行精炼词元画布 |
优势 | 高质量的生产级输出 | 低延迟交互式生成 |
上下文流动 | 解码期间大多从左到右 | 在每个去噪画布内部双向进行 |
最适合 | 通用聊天、推理、成熟服务 | 编辑、代码补全填充、快速本地工作流 |
状态 | 主导性的生产范式 | 实验性开放模型 |
行动号召
如果你正在构建 AI 产品,不要把 DiffusionGemma 视为一个简单的替代模型。应把它视为一种新的生成模式,在推理延迟、本地响应能力和非线性编辑最重要的场景中进行测试。
对于构建开发者工具、写作助手、编码工作流或端侧 AI 体验的团队来说,这是一种值得尽早基准测试的架构。
常见问题
什么是 DiffusionGemma?
DiffusionGemma 是 Google 的实验性开放文本生成模型,它使用离散扩散来并行精炼词元块,而不是只依赖逐词元生成。
Google 正在取代下一个词元预测吗?
不是。Google 仍建议使用标准 Gemma 4 以获得最高的生产质量。DiffusionGemma 是实验性的,并针对速度关键型工作流进行了优化。
为什么 DiffusionGemma 更快?
它在 256 个词元的画布上并行工作,将更多工作转向 GPU 计算,而不是严格地一次生成一个词元。
什么是 256-token 画布?
它是一组 token 位置块,模型会对其进行初始化、去噪、优化,然后在移动到下一个块之前提交。
谁应该测试 DiffusionGemma?
从事本地推理、内联编辑、代码补全、快速起草以及其他低延迟交互式 AI 工具开发的开发者应该关注。
相关工具
- Gemma 文档
- vLLM
- Colab
- Kaggle
来源
- 开发者指南
- Gemma 文档
- DeepMind
- HF 模型
- vLLM 博客
- NTP 综述