DiffusionGemma Explained: Is Google Replacing Next-Token Prediction with Faster AI Text Generation?
DiffusionGemma is Google DeepMind and Google AI’s experimental open text-generation model that uses discrete diffusion instead of pure token-by-token autoregressive decoding. This article explains how DiffusionGemma works, why it can generate text faster on GPUs, what the 256-token canvas means, how it differs from next-token prediction, and why Google is not simply replacing standard Gemma or traditional LLMs yet. Learn the trade-offs for developers, AI product teams, local inference, interactive editing, code generation, and fast AI workflows.

DiffusionGemma Explained: Is Google Replacing Next-Token Prediction with Faster AI Text Generation?
The short answer: no, but the direction matters
DiffusionGemma is not Google declaring the death of next-token prediction. It is better understood as a serious experimental signal: Google is testing a different path for AI text generation where speed, parallelism, and interactive local workflows matter more than the familiar one-token-at-a-time rhythm of standard LLMs.
Google describes DiffusionGemma as an experimental open model built around text diffusion. Instead of producing text strictly left to right, it generates blocks of text by refining a canvas of noisy or placeholder tokens. The practical promise is simple: if a model can work on many positions at once, it can use GPU compute more efficiently and reduce inference latency for some use cases.
But that does not mean autoregressive language models are being replaced tomorrow. Google’s own launch post is careful about the trade-off. It says standard Gemma 4 models remain the recommendation for applications that demand maximum production quality. That one sentence matters. DiffusionGemma is a speed-focused research and developer model, not a universal replacement for the dominant LLM paradigm.
Why next-token prediction became the default
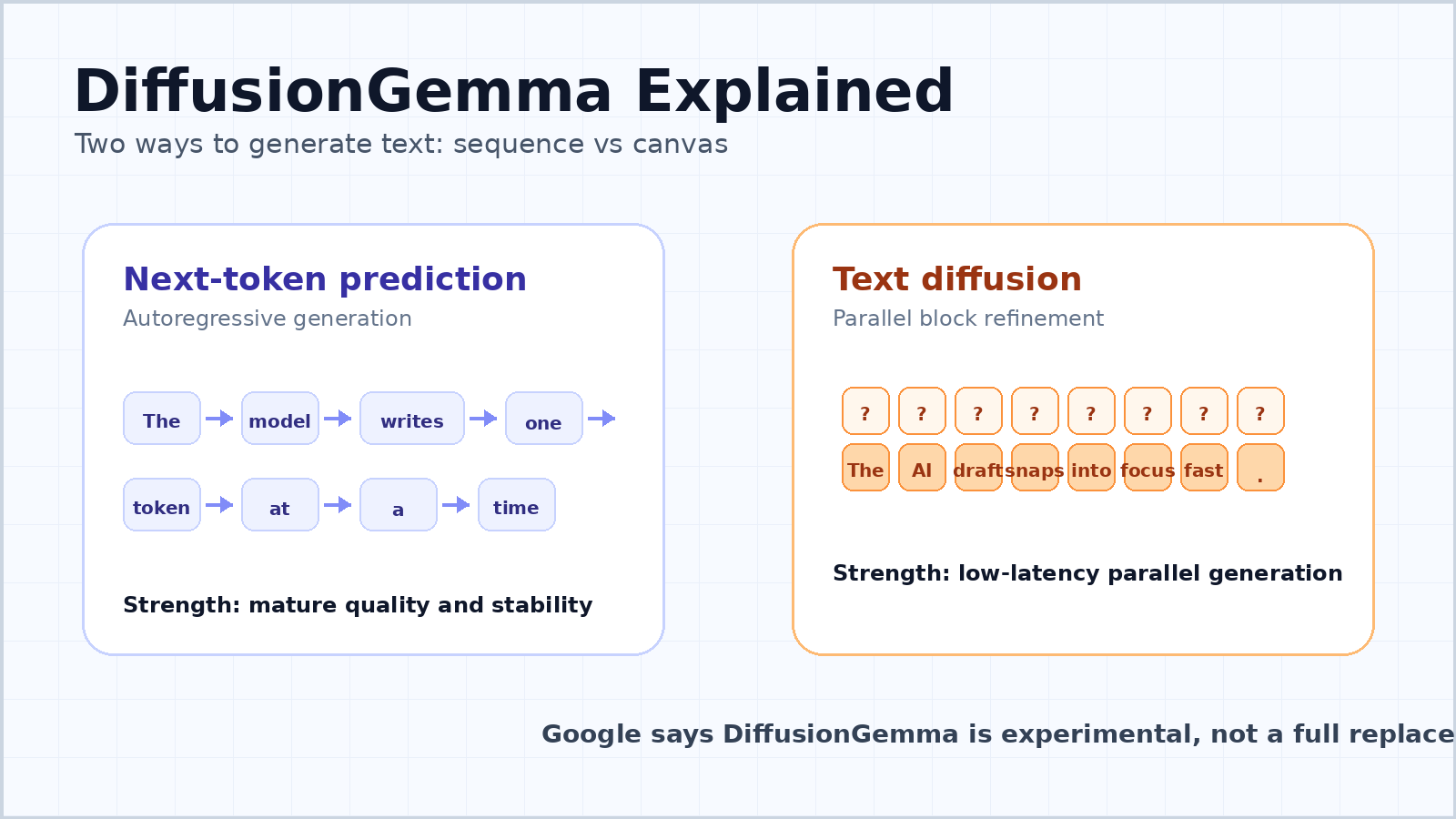
Most modern chatbots and large language models are autoregressive. They read the prompt, then predict the next token, then the next token after that, and continue until the answer is complete. This is the simple mental model behind next-token prediction.
The reason it became dominant is not accidental. Autoregressive models are flexible, stable, and easy to scale. They can generate variable-length text, preserve left-to-right coherence, and work well across chat, coding, translation, summarization, reasoning, and tool use. The approach also aligns naturally with how written language unfolds.
The weakness is latency. A token-by-token model has a sequential dependency: token 100 depends on tokens 1 through 99, and token 101 depends on token 100. Even when the GPU is powerful, the model has to step through the sequence. For one user asking one question, a lot of hardware can remain underused because the model is waiting on memory movement and sequential decoding.
What DiffusionGemma does differently
DiffusionGemma takes inspiration from diffusion models, the kind of generative model family that became famous in image and video generation. Instead of drawing the answer one token at a time, a diffusion model begins with noise or uncertainty and gradually refines it into a coherent output.
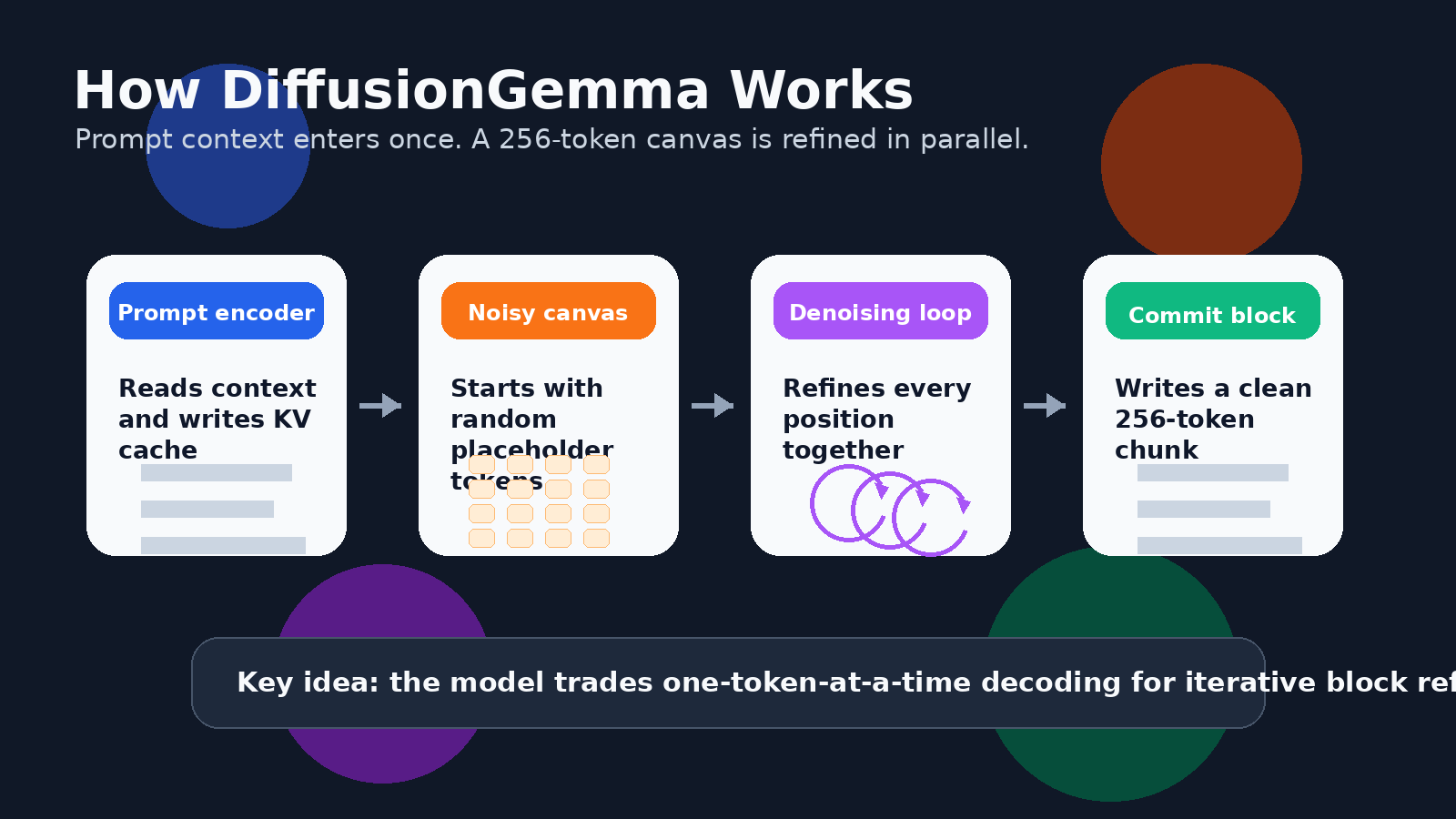
For text, that means the model can work on a block of tokens in parallel. Google’s developer guide describes a 256-token canvas. The model starts with a canvas of random placeholder tokens, then repeatedly denoises the whole block. Confident token positions become anchors, uncertain positions are refined again, and the block gradually snaps into focus.
This is not the same as generating an entire long essay in one pass. DiffusionGemma uses a block-autoregressive approach for longer outputs. Once a 256-token block is fully refined, it is committed to the KV cache, and the model moves to the next block. So it still has a left-to-right structure across blocks, but within each block it can refine many tokens together.
Why it can be faster
The speed story is about the hardware bottleneck. Traditional autoregressive models can be constrained by memory bandwidth because the model repeatedly loads weights while generating one token at a time. DiffusionGemma tries to move more of the work toward compute by giving the GPU a larger parallel workload inside each block.
Google says DiffusionGemma can deliver up to four times faster token generation on dedicated GPUs, with examples including more than 1000 tokens per second on a single NVIDIA H100 and more than 700 tokens per second on an RTX 5090. Those numbers are not a blanket promise for every task, device, or batch size. They are a signal about a specific hardware-friendly generation pattern.
This is why DiffusionGemma is especially interesting for local and interactive workflows. If one user is asking for rapid edits, code infills, structured drafts, or fast iterations, the GPU may have spare compute that an autoregressive model cannot fully use. A diffusion language model can be a better match for that kind of low-batch, speed-sensitive workload.
The role of bidirectional attention and self-correction
One of the most important differences is bidirectional attention. During denoising, tokens on the canvas can attend to other positions in the block, not just earlier tokens. That changes the feel of generation. The model can use context from both sides of a missing or uncertain span.
This is especially useful for non-linear text problems. Google points to inline editing, code infilling, mathematical graphs, and even Sudoku-style constrained generation as examples where future positions matter. A standard autoregressive model can be strong at many tasks, but once it emits an early token, it is usually stuck with it. Diffusion-style denoising creates room for revision before the block is finalized.
This is also why the phrase self-correction keeps appearing around DiffusionGemma. The model is not merely typing. It is repeatedly evaluating the whole canvas, keeping confident positions, replacing uncertain ones, and refining the block until it converges.
What the 26B MoE design means
DiffusionGemma is based on a 26B Mixture of Experts design from the Gemma 4 family, with only a smaller active subset used during inference. Google’s AI documentation describes it as a 26B model with roughly 4B active parameters, while the developer guide explains that the model is designed to fit within 18GB VRAM limits when quantized.
The key idea is efficiency. A sparse MoE model can have a large total parameter count while activating only selected experts for a given token or task. That can improve capability without requiring the full model to be active at every step.
For developers, this matters because DiffusionGemma is not just a lab demo. It is released as an open-weights model under an Apache 2.0 license, with documentation for vLLM, Hugging Face, Google Cloud Model Garden, and other deployment paths. Google is clearly inviting the ecosystem to test whether diffusion-based generation can become practical in real applications.
Where DiffusionGemma makes sense

The best use cases are not necessarily long-form premium writing. They are speed-critical tasks where the user benefits from rapid iteration. Inline editing is one example. Instead of waiting for a model to rewrite a paragraph token by token, a diffusion model can refine a whole span quickly.
Code infilling is another strong candidate. A developer may need a model to fill the middle of a function or adjust a block of code with awareness of what comes before and after. Bidirectional attention is useful here because the model can reason over both sides of the missing section.
Structured and constrained generation is also interesting. If the output has multiple dependencies, like a table, puzzle, template, or formal schema, block refinement can give the model more room to coordinate across positions. That is why DiffusionGemma is not just about being faster. It also points toward a different interaction style for generation.
Where autoregressive models still win
The trade-off is quality. Google explicitly says DiffusionGemma prioritizes speed and parallel layout generation, and that its overall output quality is lower than standard Gemma 4. That is the central reason it should not be described as replacing next-token prediction outright.
Autoregressive models still have major advantages. They are deeply optimized for production, strong across many general-purpose tasks, and supported by mature serving stacks. They also work naturally for conversational flows where the model extends text in a steady sequence.
The realistic future is probably not one decoding method replacing the other. It is more likely that AI systems will route different tasks to different generation strategies. Autoregressive models may remain the default for high-quality general chat and reasoning, while diffusion language models may power fast editing, local generation, code infilling, and other interactive workloads.
What developers should watch next
The biggest question is whether diffusion language models can close the quality gap while keeping the latency advantage. Speed alone is not enough if the output needs too much correction. But if quality improves, the architecture could become very important for local AI, IDE assistants, document editing, and real-time interfaces.
The second question is serving infrastructure. vLLM support is important because diffusion language models require different decoding behavior: bidirectional attention, iterative denoising, custom sampling, and block-level commit logic. If inference frameworks make this easy, more developers will experiment.
The third question is product design. A diffusion text model is not just a faster chatbot. Its natural interface may be more like a smart editor that revises a canvas, fills gaps, and improves drafts in place. That could change how users experience AI writing and coding tools.
Final takeaway
DiffusionGemma does not mean Google is replacing next-token prediction today. It means Google is making text diffusion practical enough for developers to test in real workflows.
The important shift is not just faster text. It is the idea that language generation does not always have to look like a model typing from left to right. Sometimes the better interaction is a canvas that gets refined in parallel.
If that pattern improves, AI text generation could become faster, more interactive, and better suited to local devices. But for now, DiffusionGemma should be understood as an experimental open model with a very clear message: the future of language generation may include more than one decoding path.
Quick comparison
Question | Autoregressive LLMs | DiffusionGemma |
Generation pattern | Predicts the next token sequentially | Refines a token canvas in parallel |
Strength | High-quality production outputs | Low-latency interactive generation |
Context flow | Mostly left-to-right during decoding | Bidirectional inside each denoising canvas |
Best fit | General chat, reasoning, mature serving | Editing, code infill, rapid local workflows |
Status | Dominant production paradigm | Experimental open model |
CTA
If you are building AI products, do not treat DiffusionGemma as a simple replacement model. Treat it as a new generation pattern to test where inference latency, local responsiveness, and non-linear editing matter most.
For teams building developer tools, writing assistants, coding workflows, or on-device AI experiences, this is the kind of architecture worth benchmarking early.
FAQ
What is DiffusionGemma?
DiffusionGemma is Google’s experimental open text-generation model that uses discrete diffusion to refine blocks of tokens in parallel instead of relying only on token-by-token generation.
Is Google replacing next-token prediction?
No. Google still recommends standard Gemma 4 for maximum production quality. DiffusionGemma is experimental and optimized for speed-critical workflows.
Why is DiffusionGemma faster?
It works on a 256-token canvas in parallel, shifting more work toward GPU compute instead of generating strictly one token at a time.
What is a 256-token canvas?
It is a block of token positions that the model initializes, denoises, refines, and then commits before moving to the next block.
Who should test DiffusionGemma?
Developers working on local inference, inline editing, code infilling, rapid drafting, and other low-latency interactive AI tools should pay attention.
Related Tools
- vLLM
- Colab
- Kaggle
Sources
- DeepMind
- HF Model