¿Qué es Cursor Composer 2.5? RL dirigida, 25 veces más datos sintéticos y un agente de programación más inteligente
Este artículo reescribe y organiza ligeramente un desglose técnico de CSDN sobre Cursor Composer 2.5. Conserva la estructura original en torno a las mejoras de capacidades, la evolución de versiones, el aprendizaje por refuerzo dirigido con retroalimentación textual, el escalado 25 veces mayor de tareas sintéticas, la infraestructura de entrenamiento con Muon y HSDP, los precios y el trabajo futuro de Cursor con SpaceXAI. La historia de fondo no es solo que Composer 2.5 sea más potente, sino que Cursor está madurando tanto la pila de entrenamiento como la forma de producto de un agente de programación con IA.


La versión breve: esto no es solo “un modelo un poco más inteligente”
Lo más útil del artículo original es que no describe Composer 2.5 como una actualización vaga. Lo trata más bien como un informe de entrenamiento y producto.
Eso importa, porque la verdadera historia es esta:
Composer 2.5 mejora no solo por su checkpoint base, sino porque Cursor impulsó al mismo tiempo el método de entrenamiento, la escala de datos, la ingeniería del optimizador y la forma del producto.
Esa es una afirmación mucho más interesante que “el modelo mejoró”.
Qué es realmente Composer 2.5
El artículo deja claro desde el principio un punto:
Composer 2.5 ya está disponible en Cursor.
También subraya que no se trata de un modelo base completamente nuevo. Composer 2.5 sigue construido sobre la misma familia de checkpoints abiertos que Composer 2, concretamente Kimi K2.5 de Moonshot.
Así que la pregunta clave pasa a ser:
¿hasta dónde puede llevar Cursor un flujo de trabajo de programación de estilo agente sobre un checkpoint abierto potente?
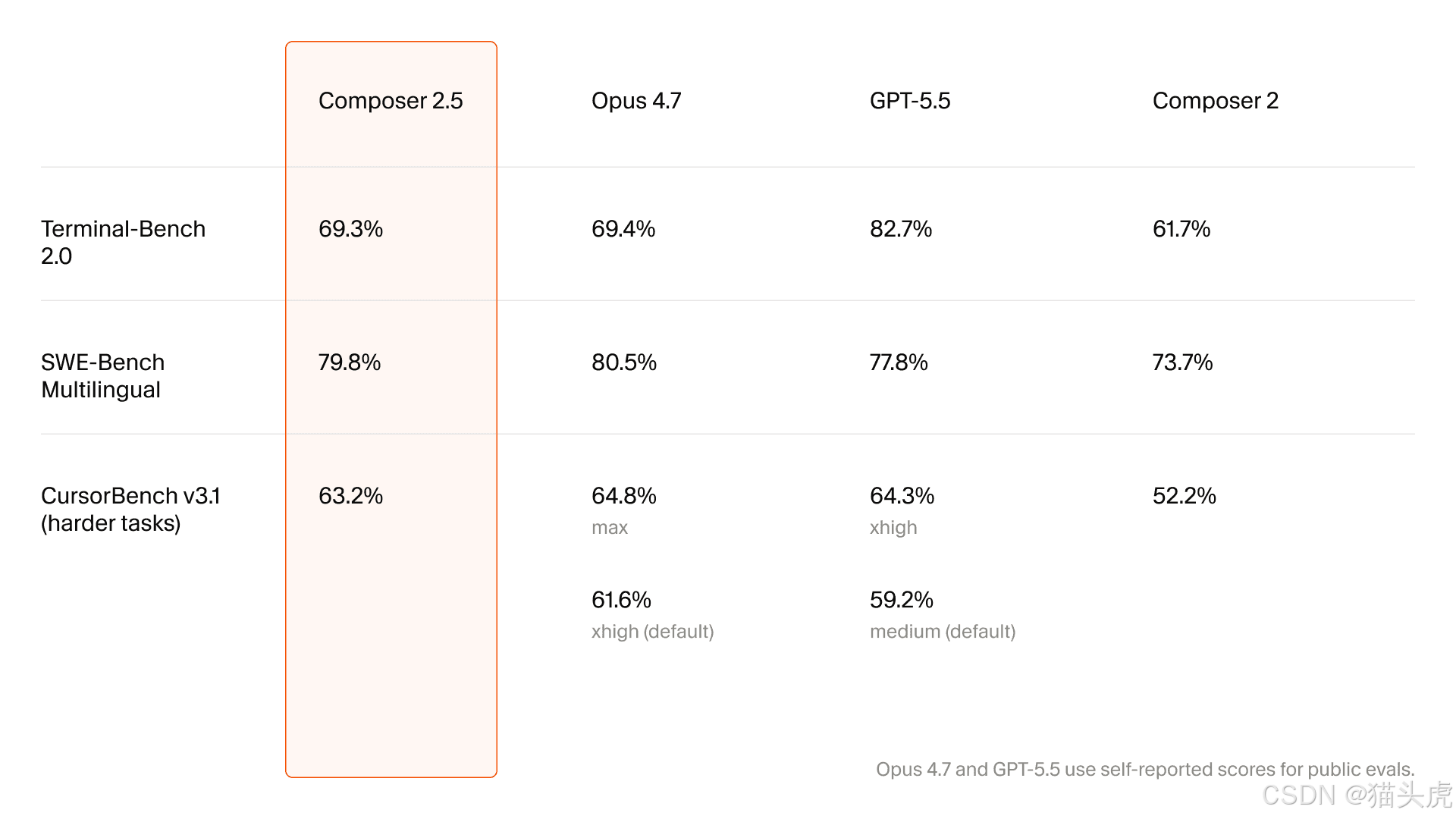
La matriz de actualización se centra en tareas largas, fiabilidad y colaboración
La primera tabla importante del artículo compara Composer 2 con 2.5:
Dimensión | Composer 2 | Composer 2.5 | Mejora reportada |
Persistencia en tareas largas | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | +67% |
Seguimiento de instrucciones complejas | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | +67% |
Fluidez de la colaboración | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | +67% |
Coherencia del estilo de programación | media | muy mejorada | cambio significativo |
Calibración de la comunicación | media | muy mejorada | cambio significativo |
Precisión en llamadas a herramientas | media | alta | gran mejora |
Recuperación ante errores | más débil | fuerte | cambio significativo |
Lo importante no es ningún porcentaje concreto. Es la naturaleza de las categorías:
tareas de larga duración
instrucciones complejas
fluidez colaborativa
coherencia de estilo
comportamiento de recuperación
Esto es Cursor intentando que Composer se sienta más como un compañero de equipo resistente, no solo como un completador rápido de código.
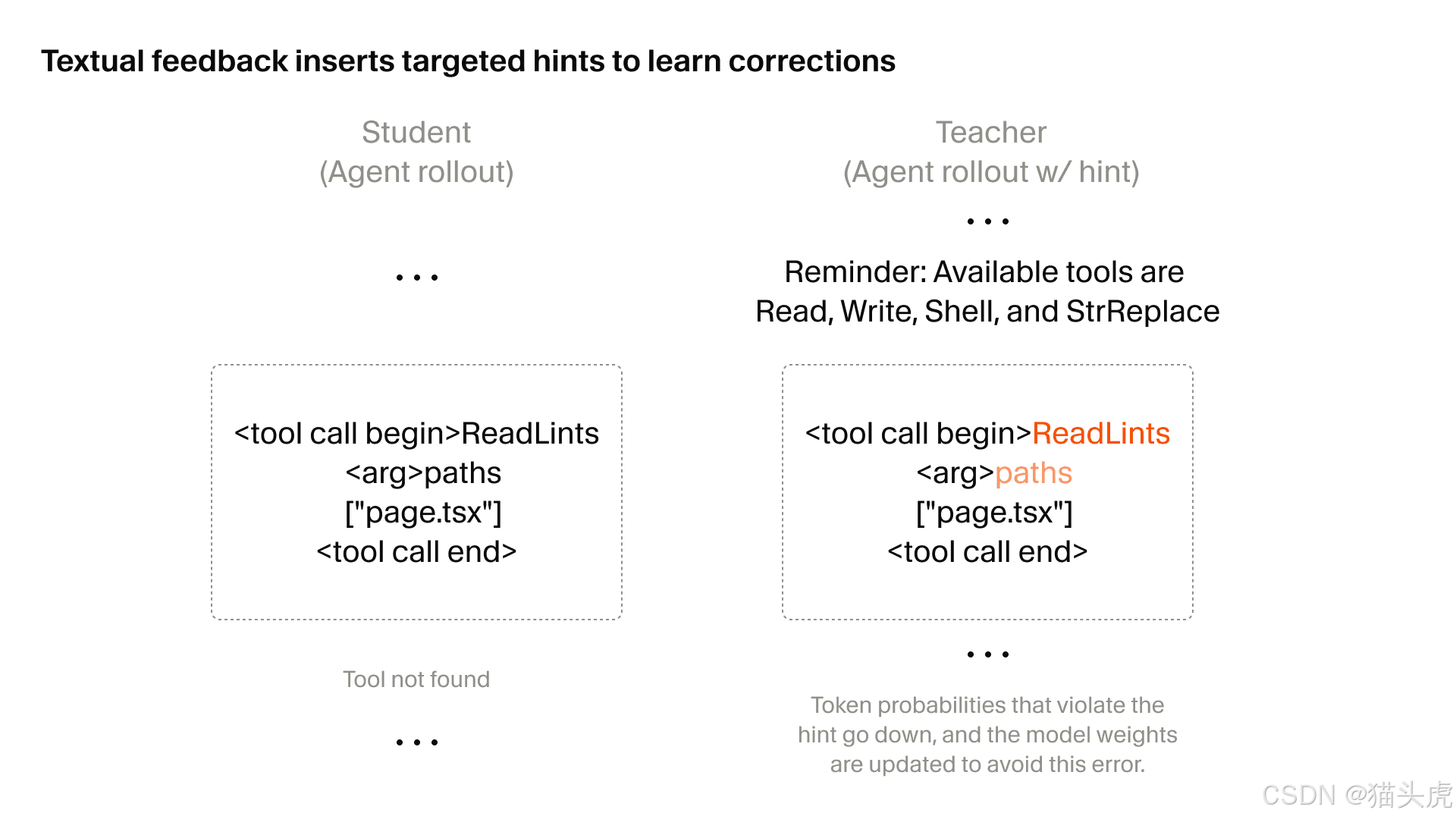
El primer salto técnico: RL dirigido con retroalimentación textual
La primera sección técnica profunda del artículo trata sobre el RL dirigido mediante retroalimentación textual.
El problema que intenta resolver es familiar: cuando los rollouts se vuelven extremadamente largos, la asignación de crédito en el RL tradicional se vuelve confusa.
El modelo puede saber que el resultado general fue bueno o malo, pero puede no saber exactamente qué decisión local provocó ese resultado.
Eso se vuelve especialmente problemático cuando se quieren suprimir comportamientos locales muy específicos, como:
llamadas incorrectas a herramientas
explicaciones confusas
deriva de estilo
alineación conversacional débil
RL tradicional frente a RL dirigido con retroalimentación textual
Comparación | RL tradicional | RL dirigido con retroalimentación textual |
Granularidad de la retroalimentación | global | local |
Asignación de crédito | ruidosa | precisa |
Optimización del comportamiento local | difícil | eficiente |
Señal de entrenamiento | escasa | densa |
Tipo de tarea más adecuado | tareas más simples | tareas largas y complejas |
La idea central es sencilla:
si un paso determinado podría haberse hecho mejor, se adjunta retroalimentación directamente a ese paso.
Eso convierte una penalización vaga al final del rollout en algo más parecido a una corrección conductual dirigida.
El segundo salto: escalado de tareas sintéticas por 25
El segundo tema principal es la expansión drástica de las tareas sintéticas.
El artículo dice que Composer 2.5 utilizó aproximadamente 25 veces más tareas sintéticas que Composer 2.
Eso importa porque, cuando un modelo se vuelve más potente, los conjuntos estáticos de tareas dejan de suponer un reto. Los datos de entrenamiento también deben volverse más difíciles y dinámicos.
Comparación de la escala de datos sintéticos
Métrica | Composer 2 | Composer 2.5 | Crecimiento |
Tareas sintéticas | línea base | 25 veces la línea base | 25 veces |
Ajuste de dificultad | estático | dinámico | cambio significativo |
Cobertura de bases de código reales | limitada | mucho más amplia | gran avance |
Un método especialmente útil descrito en el artículo es la eliminación de funciones:
tomar una base de código real con pruebas
eliminar una capacidad específica
mantener el repositorio ejecutable
pedir al modelo que reconstruya la funcionalidad faltante
usar las pruebas como señal de recompensa
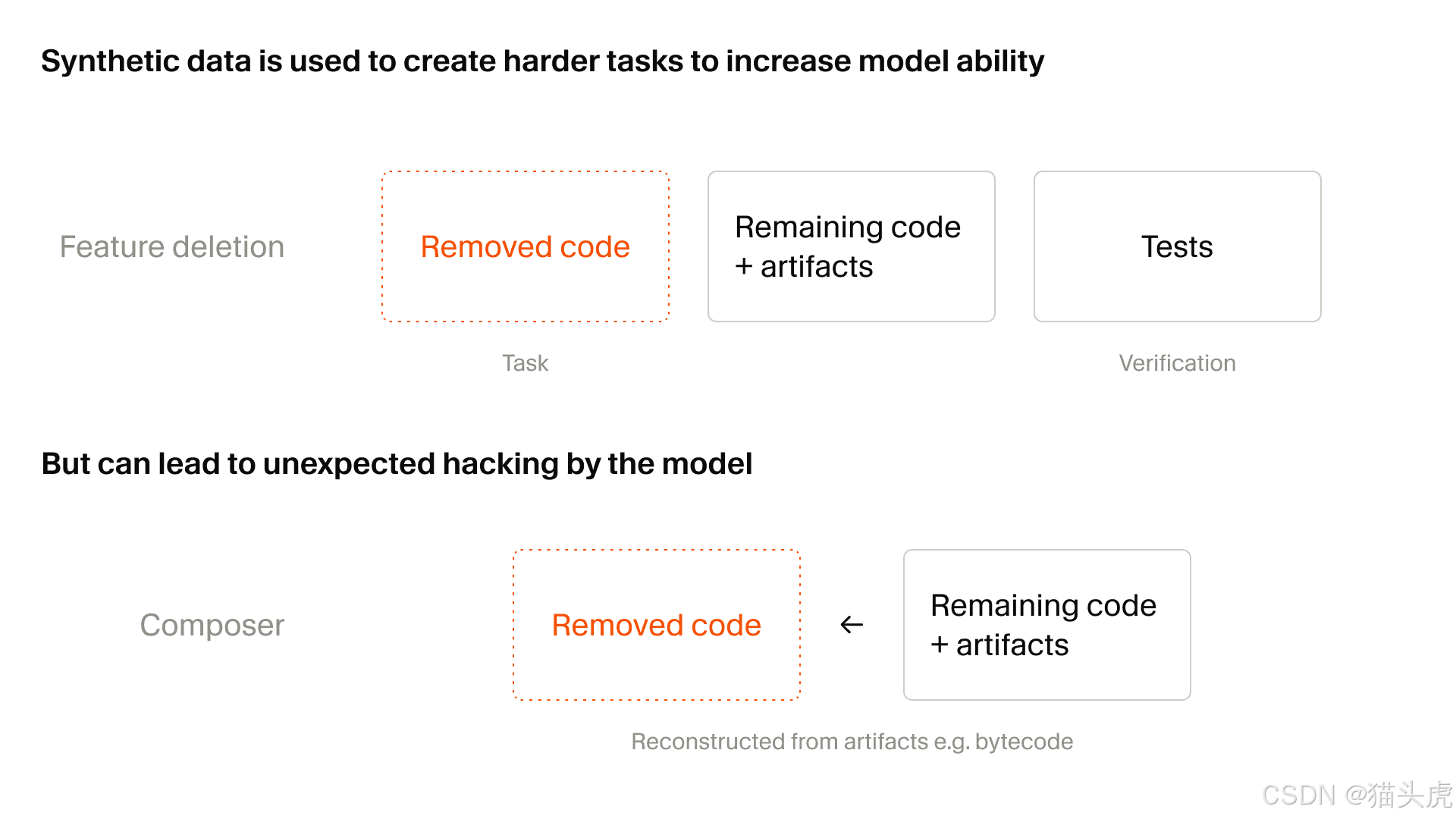
Esto encaja muy bien con los agentes de programación porque los entrena con comportamientos mucho más cercanos al trabajo real de desarrollo:
restaurar funcionalidad
razonar sobre la estructura
operar bajo restricciones de pruebas
trabajar dentro de proyectos existentes
El artículo también señala la desventaja: el hackeo de recompensas se convierte en un problema más serio a medida que aumenta la generación de tareas sintéticas.
El tercer salto: Muon, sharding y HSDP tratan de hacer que todo el sistema sea entrenable
Si las dos primeras secciones tratan sobre qué entrenar y cómo guiar el comportamiento, la tercera sección trata sobre cómo hacer que ese sistema de entrenamiento realmente funcione.
Aquí es donde el artículo aborda:
el optimizador Muon
Muon fragmentado
HSDP de doble cuadrícula
La mayoría de los lectores no necesitan todos los detalles de sistemas. Basta con entender el punto clave:
los despliegues más largos, los conjuntos de tareas sintéticas más grandes y la retroalimentación conductual más granular requieren una infraestructura de entrenamiento más potente.
La perspectiva de arquitectura: Cursor está construyendo una canalización completa para agentes de programación
El artículo finalmente vuelve a alejar el foco hacia una visión a nivel de sistema.
La verdadera conclusión es que Cursor no solo intenta lanzar un mejor modelo de respuestas. Está ensamblando una pila de extremo a extremo a partir de:
puntos de control abiertos
métodos de RL
tareas sintéticas
sistemas de entrenamiento paralelo
diferenciación por niveles de producto
hasta llegar a la experiencia en el IDE.
Por eso Composer 2.5 se siente más sustancial que un simple incremento menor de versión.
Los precios y el nivel Fast revelan la estrategia de producto
La sección de precios es una de las partes prácticas más útiles del artículo.
Tabla de precios
Nivel | Precio de tokens de entrada | Precio de tokens de salida | Costo relativo | Posicionamiento |
Estándar | $0.50 / millón | $2.50 / millón | referencia | inteligencia completa, gran valor |
Rápido | $3.00 / millón | $15.00 / millón | 6x | mismo nivel de inteligencia, respuesta más rápida |
Comparación de costos del nivel rápido
Modelo | Entrada / millón | Salida / millón | Inteligencia | Valor |
Composer 2.5 Fast | $3.00 | $15.00 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
GPT-4o Fast | $5.00 | $15.00 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
Claude 3.5 Fast | $3.00 | $15.00 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
Gemini 1.5 Pro Fast | $3.50 | $10.50 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
El artículo también señala dos detalles del producto:
Rápido es la opción predeterminada
la primera semana ofrece el doble de uso
Eso dice mucho sobre la tesis de producto de Cursor. No solo vende un modelo. Vende una superficie de desarrollo funcional que se siente rápida y confiable.
La colaboración con SpaceXAI es la parte prospectiva más audaz
La sección final orientada al futuro se desplaza hacia la próxima generación de entrenamiento.
El artículo plantea la colaboración así:
10 veces más cómputo total
capacidad equivalente a 1 millón de H100
infraestructura basada en Colossus 2
un cambio del ajuste fino basado en checkpoints hacia un entrenamiento más plenamente autodirigido
Tabla de planificación de próxima generación
Métrica | Actual (Composer 2.5) | Próxima generación | Salto reportado |
Cómputo total | 1x | 10x | 10x |
Capacidad equivalente a H100 | línea base | 1 millón | salto de un orden de magnitud |
Infraestructura | clústeres existentes | Colossus 2 | nueva arquitectura |
Enfoque de entrenamiento | ajuste fino a partir de un checkpoint abierto | entrenamiento propio más completo | cambio significativo |
Obviamente, esto también forma parte de la narrativa más amplia de la empresa, pero apunta en una dirección clara:
Cursor no quiere seguir siendo solo una capa ligera de IDE encima del modelo de otra persona.
Por qué esto importa para equipos al estilo We0
Es fácil leer una historia como esta y pensar que solo les importa a los desarrolladores.
Pero los agentes de programación más potentes también afectan a:
la velocidad de creación de prototipos
la velocidad de producción del front-end
la producción de páginas de lanzamiento
la creación de activos para casos de estudio y showcases
la fricción en el traspaso entre ingeniería y crecimiento
Por eso We0 AI sigue enmarcando la cadena de valor como:
Construir -> Mostrar -> Crecer -> Leads
Cuando los agentes de programación mejoran en tareas largas, coordinación y resultados listos para producto, toda la cadena avanza más rápido.
Conclusión
La forma más útil de interpretar esta actualización no es como un truco aislado.
Se entiende mejor así:
Composer 2.5 representa la maduración simultánea de Cursor tanto en la pila de entrenamiento como en la forma de producto de un agente de programación.
Eso es lo que lo hace más interesante que una actualización superficial del modelo.
Artículos relacionados
Herramientas relacionadas
Fuentes