什麼是 Cursor Composer 2.5?定向強化學習、25 倍合成資料,以及更聰明的程式碼代理
本文以較輕量的方式改寫並整理一篇 CSDN 對 Cursor Composer 2.5 的技術解析。內容保留原本圍繞能力提升、版本演進、定向文字回饋強化學習、25 倍合成任務擴展、Muon 與 HSDP 訓練基礎架構、定價,以及 Cursor 與 SpaceXAI 未來合作方向的結構。更大的重點不只是 Composer 2.5 變得更強,而是 Cursor 正在讓 AI 程式碼代理的訓練堆疊與產品形態同步走向成熟。


簡短版:這不只是「稍微聰明一點的模型」
原文最有用之處在於,它並沒有把 Composer 2.5 描述成一個模糊的升級。它更像是把它當成一份訓練與產品報告來看待。
這點很重要,因為真正的重點是:
Composer 2.5 的進步不只來自其基礎檢查點,而是因為 Cursor 同時推進了訓練方法、資料規模、最佳化器工程,以及產品形式。
這比「模型變更好了」有趣得多。
Composer 2.5 到底是什麼
文章一開始就清楚指出:
Composer 2.5 現已可在 Cursor 中使用。
它也強調,這並不是一個全新的基礎模型。Composer 2.5 仍然建立在與 Composer 2 相同的開放檢查點系列之上,也就是 Moonshot 的 Kimi K2.5。
所以關鍵問題變成:
Cursor 能在一個強大的開放檢查點之上,把代理式程式設計工作流程推進到什麼程度?
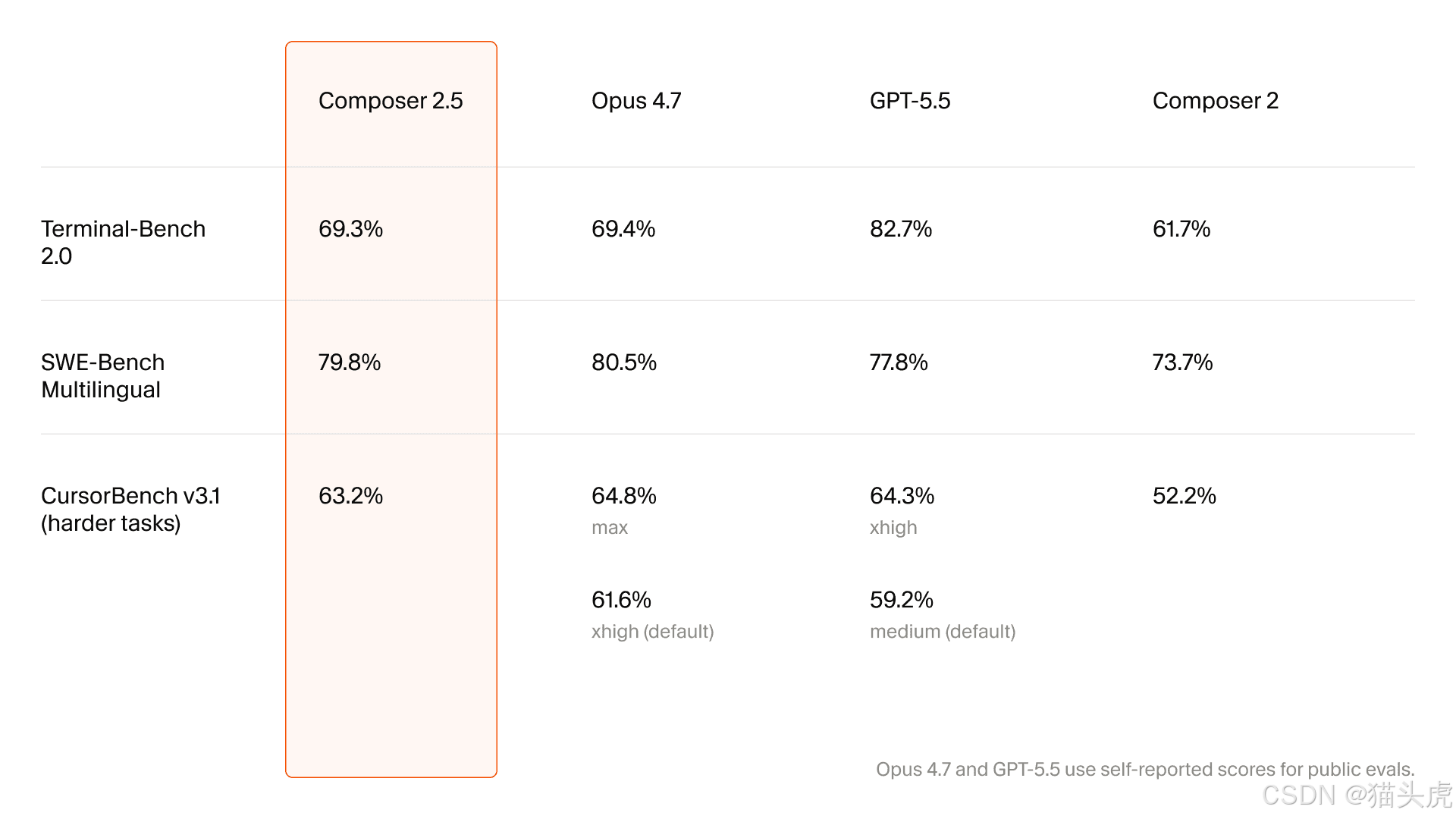
升級矩陣聚焦在長任務、可靠性與協作
文章的第一個主要表格比較了 Composer 2 與 2.5:
面向 | Composer 2 | Composer 2.5 | 回報提升 |
長任務持續性 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | +67% |
複雜指令遵循 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | +67% |
協作順暢度 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | +67% |
程式碼風格一致性 | 普通 | 大幅改善 | 階段性躍升 |
溝通校準 | 普通 | 大幅改善 | 階段性躍升 |
工具呼叫準確度 | 中等 | 高 | 重大提升 |
錯誤復原 | 較弱 | 強 | 階段性躍升 |
重要的不是任何單一百分比,而是這些分類本身的性質:
長時間執行的任務
複雜指令
協作順暢度
風格一致性
復原行為
這是 Cursor 試圖讓 Composer 感覺更像一位可靠耐用的隊友,而不只是快速的程式碼補完工具。
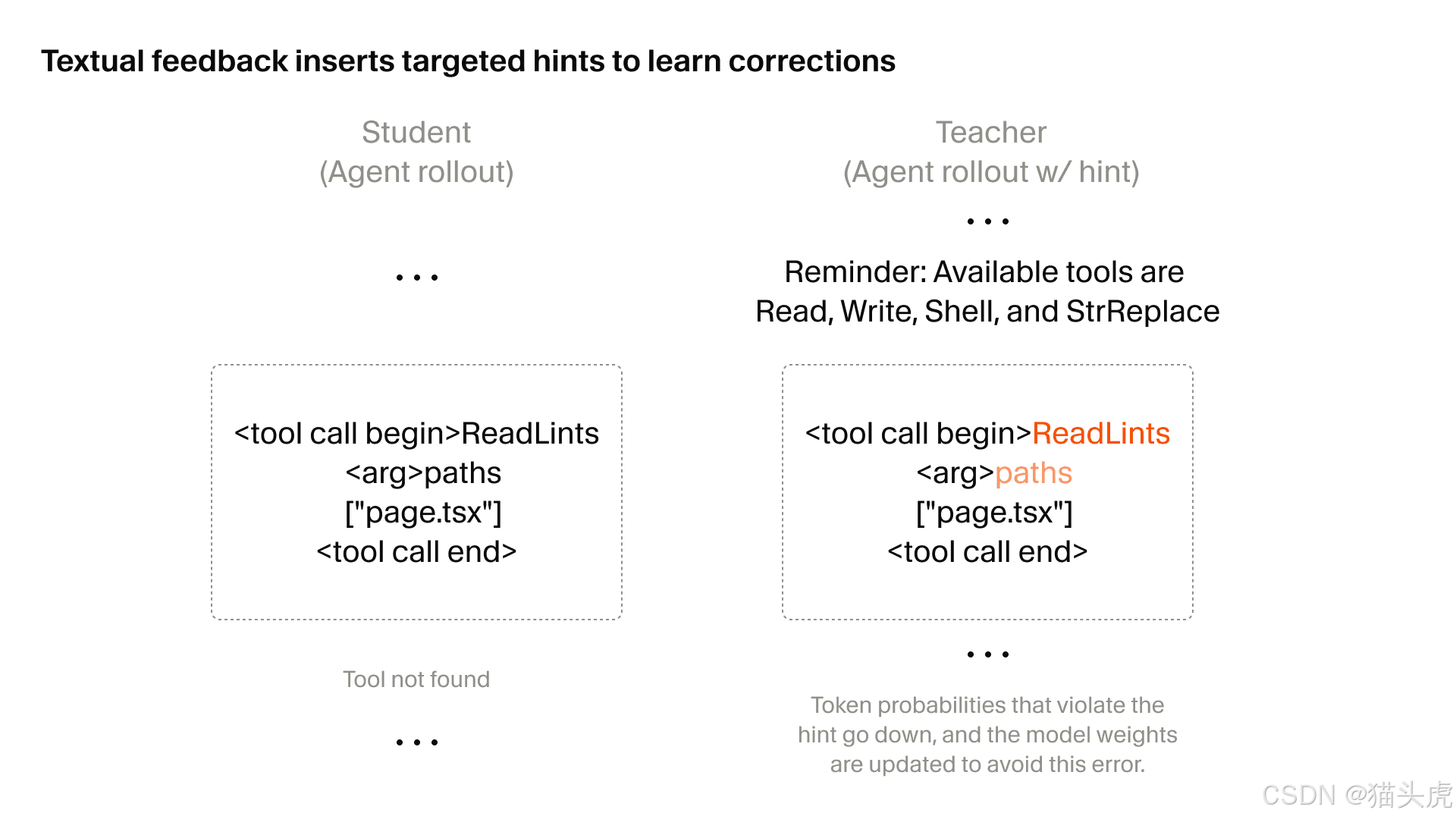
第一次技術躍進:導向式文字回饋 RL
文章第一個深入的技術章節是關於使用文字回饋的導向式 RL。
它試圖解決的問題很常見:一旦 rollout 變得極長,傳統 RL 中的信用分配就會變得混亂。
模型可能知道整體結果是好是壞,但可能不知道究竟是哪個局部選擇導致了該結果。
當你想抑制非常特定的局部行為時,這會變得特別棘手,例如:
錯誤的工具呼叫
令人困惑的解釋
風格偏移
薄弱的對話一致性
傳統 RL 與導向式文字回饋 RL
比較項目 | 傳統 RL | 導向式文字回饋 RL |
回饋粒度 | 全域 | 局部 |
信用分配 | 雜訊高 | 精確 |
局部行為最佳化 | 困難 | 高效 |
訓練訊號 | 稀疏 | 密集 |
最適合的任務類型 | 較簡單的任務 | 長且複雜的任務 |
核心想法很簡單:
如果某個步驟本可以做得更好,就直接把回饋附加到那個步驟上。
這會把模糊的 rollout 結尾懲罰,轉變成更像是有針對性的行為修正。
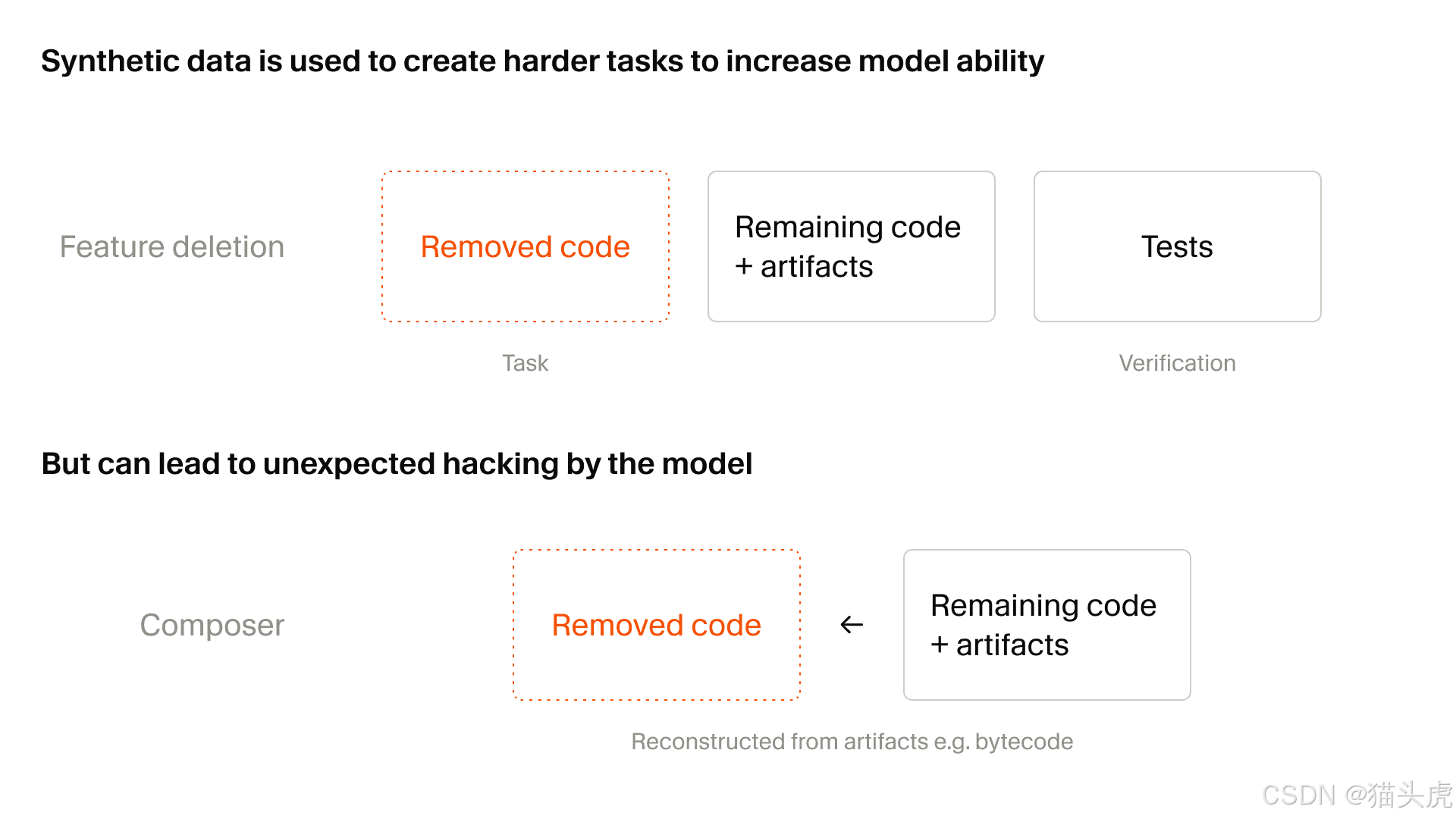
第二次躍進:合成任務擴展 25 倍
第二個主要主題是合成任務的大幅擴展。
文章表示,Composer 2.5 使用的合成任務大約是 Composer 2 的 25 倍。
這一點很重要,因為一旦模型變得更強,靜態任務池就不再足以挑戰它。訓練資料也必須變得更困難、更動態。
合成資料規模比較
指標 | Composer 2 | Composer 2.5 | 成長 |
合成任務 | 基準 | 25 倍基準 | 25 倍 |
難度調整 | 靜態 | 動態 | 階段性變化 |
真實程式碼庫涵蓋範圍 | 有限 | 廣泛許多 | 大幅提升 |
文中描述的一個特別有用的方法是 功能刪除:
取一個含有測試的真實程式碼庫
移除某項特定能力
保持儲存庫可執行
要求模型重建缺失的功能
使用測試作為獎勵訊號
這非常適合程式碼代理,因為它會用更接近真實開發工作的行為來訓練它們:
恢復功能
推理結構
在測試限制下運作
在現有專案中工作
文章也指出了缺點:隨著合成任務生成規模擴大,獎勵駭取會成為更嚴重的問題。
第三次躍進:Muon、分片與 HSDP 是為了讓整個系統可訓練
如果前兩節談的是要訓練什麼,以及如何引導行為,那麼第三節談的就是如何讓這套訓練系統真正跑起來。
這也是文章討論以下內容的地方:
Muon 最佳化器
分片式 Muon
雙網格 HSDP
大多數讀者不需要了解每個系統細節。掌握關鍵點就足夠了:
更長的 rollout、更大的合成任務池,以及更細緻的行為回饋,都需要更強大的訓練基礎架構。
架構視角:Cursor 正在打造完整的程式碼代理流程
文章最後拉回到系統層級的圖像。
真正的重點是,Cursor 不只是想推出一個更好的回答模型。它正在組建一套端到端堆疊,涵蓋:
開放檢查點
強化學習方法
合成任務
平行訓練系統
產品層級差異化
一路延伸到 IDE 體驗。
這就是為什麼 Composer 2.5 感覺不只是一次表面的版本小升級。
定價與 Fast 層級揭示了產品策略
定價部分是文章中最實用的部分之一。
定價表
等級 | 輸入 token 價格 | 輸出 token 價格 | 相對成本 | 定位 |
標準 | $0.50 / 百萬 | $2.50 / 百萬 | 基準 | 完整智慧,超值 |
快速 | $3.00 / 百萬 | $15.00 / 百萬 | 6 倍 | 相同智慧水準,更快回應 |
快速等級成本比較
模型 | 輸入 / 百萬 | 輸出 / 百萬 | 智慧 | 價值 |
Composer 2.5 Fast | $3.00 | $15.00 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
GPT-4o Fast | $5.00 | $15.00 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
Claude 3.5 Fast | $3.00 | $15.00 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
Gemini 1.5 Pro Fast | $3.50 | $10.50 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
文章也提到兩項產品細節:
快速是預設選項
第一週可獲得雙倍使用量
這充分說明了 Cursor 的產品主張。它賣的不只是一個模型,而是一個感覺快速且可靠的實用開發介面。
SpaceXAI 合作是最具前瞻性且最大膽的部分
最後的前瞻性段落轉向下一代訓練。
文章是這樣描述這項合作的:
總運算量 10 倍
100 萬 H100 等效容量
基於 Colossus 2 的基礎設施
從基於檢查點的微調,轉向更全面的自主訓練
下一代規劃表
指標 | 目前(Composer 2.5) | 下一代 | 據稱提升 |
總運算量 | 1 倍 | 10 倍 | 10 倍 |
H100 等效容量 | 基準 | 100 萬 | 數量級躍升 |
基礎設施 | 現有叢集 | Colossus 2 | 新架構 |
訓練方法 | 從開放檢查點進行微調 | 更全面地自我訓練 | 階段性變化 |
這顯然也是該公司更大敘事的一部分,但它指向了一個明確方向:
Cursor 不想只停留在別人模型之上的薄薄一層 IDE。
為什麼這對 We0 風格的團隊很重要
看到這樣的故事,很容易以為它只對開發者重要。
但更強的程式碼代理也會影響:
原型製作速度
前端產出速度
上線頁面製作
案例研究與展示素材創作
工程與成長團隊之間的交接摩擦
這就是為什麼 We0 AI 一直將價值鏈定位為:
建置 -> 展示 -> 成長 -> 潛在客戶
當程式碼代理在長任務、協作和可產品化輸出方面變得更好時,整個鏈條都會加速。
重點總結
理解這次升級最有用的方式,不是把它看成一個孤立的小技巧。
更好的理解是:
Composer 2.5 代表 Cursor 同時讓訓練堆疊與程式碼代理的產品形態走向成熟。
這正是它比表面的模型更新更有意思的地方。
相關文章
相關工具
來源