Cursor Composer 2.5 expliqué : RL dirigé, données synthétiques et montée en puissance des agents de codage IA
Cursor Composer 2.5 est une mise à niveau majeure du modèle propriétaire de codage IA de Cursor, axée sur des tâches de génie logiciel de longue durée plus fiables, un meilleur respect des consignes et une collaboration renforcée au sein des flux de travail de programmation. Ce guide explique ce qu’est Composer 2.5, comment fonctionne son apprentissage par renforcement ciblé avec retour textuel, pourquoi une multiplication par 25 des tâches synthétiques est importante, et comment ces changements font évoluer les assistants de codage IA vers des agents de codage IA plus performants. Il explique également ce que les fondateurs, les développeurs, les équipes produit et les travailleurs du savoir doivent comprendre sur la prochaine étape du développement logiciel assisté par l’IA.

Cursor Composer 2.5 expliqué : RL dirigé, données synthétiques et mise à niveau des agents de codage IA
Qu’est-ce que Cursor Composer 2.5 ?
Cursor Composer 2.5 est le modèle propriétaire amélioré de Cursor pour le travail de codage agentique. Ce n’est pas seulement une fonction d’autocomplétion, ni simplement un modèle de chat placé dans un éditeur. Il est conçu pour fonctionner dans l’environnement Cursor, utiliser des outils, lire du code, suivre des instructions et rester utile tout au long de tâches d’ingénierie logicielle plus longues.
Cursor affirme que Composer 2.5 représente une amélioration substantielle par rapport à Composer 2 en matière d’intelligence et de comportement. La publication officielle met en avant une meilleure continuité de travail sur les tâches de longue durée, un suivi plus fiable des instructions complexes et un style de collaboration plus agréable. C’est important, car le véritable travail de développement se résume rarement à un seul prompt. C’est une séquence désordonnée de lecture de fichiers, de compréhension des tests, de modifications, de débogage et d’explication des compromis.
La manière la plus simple de comprendre cette mise à niveau est la suivante : Cursor essaie de passer d’un assistant de codage IA à un agent de codage IA plus fiable. Un assistant de codage vous aide à écrire des extraits de code. Un agent de codage peut mener un travail sur de nombreuses étapes, utiliser des outils, vérifier les résultats et s’adapter lorsque le premier plan échoue.
Pourquoi Composer 2.5 est important
Le marché du codage par IA évolue rapidement. Les développeurs ne jugent plus les outils uniquement à l’apparence impressionnante d’une réponse isolée. Ils évaluent si le système peut travailler dans une véritable base de code sans perdre constamment le fil. Peut-il exécuter des tests ? Peut-il éviter les mauvais appels d’outils ? Peut-il respecter les exigences de style ? Peut-il expliquer ce qui a changé ? Peut-il continuer après une erreur au lieu de dériver ?
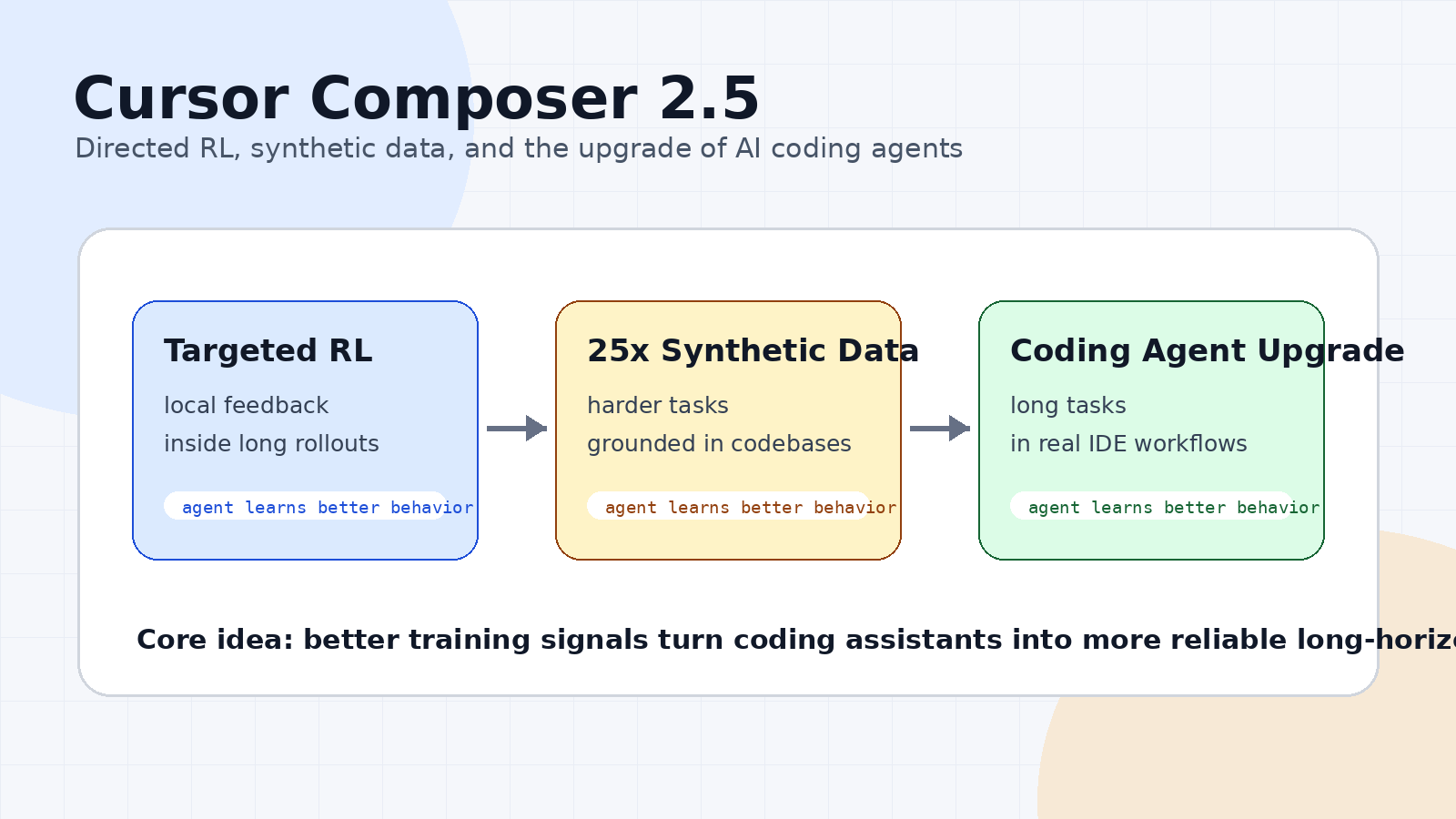
C’est pourquoi Composer 2.5 est important. La publication de Cursor se concentre moins sur des prompts de démonstration spectaculaires que sur les méthodes d’entraînement qui rendent le comportement des agents plus fiable. L’histoire importante n’est pas seulement que le modèle est plus puissant. L’histoire importante est la manière dont Cursor l’entraîne pour le travail de codage à long horizon.
Ce changement est également pertinent au-delà de la programmation. Une fois qu’un système d’IA peut gérer de longues tâches, utiliser des outils, recevoir des retours locaux et améliorer son comportement dans un flux de travail complexe, la même logique commence à s’étendre vers l’automatisation du travail intellectuel : rédaction de spécifications techniques, analyse de documents, préparation de rapports, mise à jour de sites web et coordination de tâches de production en plusieurs étapes.
RL dirigé, ou plus précisément RL ciblé avec retour textuel
Le titre de l’article utilise RL dirigé, car c’est ainsi que beaucoup de personnes décrivent l’idée à un niveau général : un processus d’entraînement qui apporte au modèle une correction plus dirigée au lieu de s’appuyer uniquement sur une récompense finale globale. Le terme officiel de Cursor est plus spécifique : RL ciblé avec retour textuel.
Dans l’apprentissage par renforcement normal, un modèle peut recevoir une récompense après un long déroulement. Le problème est l’attribution du crédit. Si l’agent effectue des centaines d’appels d’outils et qu’un mauvais appel d’outil survient au milieu, le score final peut ne pas indiquer exactement au modèle où il s’est trompé. Le signal est trop large.
Composer 2.5 tente de corriger cela en insérant de courts retours textuels au point local où le modèle aurait pu mieux se comporter. Cursor décrit cela comme la construction d’un indice pour un message cible du modèle, l’insertion de cet indice dans le contexte local, puis l’utilisation de la distribution qui en résulte comme enseignant. La politique déployée avec le contexte d’origine devient l’élève, et une perte de distillation on-policy pousse l’élève vers un meilleur comportement tout en préservant l’objectif RL plus large.
En termes simples : au lieu de dire seulement « toute la tâche a échoué », le processus d’entraînement peut dire « ce tour était le problème, voici le meilleur comportement ». C’est puissant pour les agents de codage IA, car de nombreuses erreurs sont locales. Un mauvais outil, une explication confuse ou une violation de style peut ne pas faire échouer toute la tâche, mais cela rend tout de même l’agent moins fiable.
Pourquoi les données synthétiques sont centrales
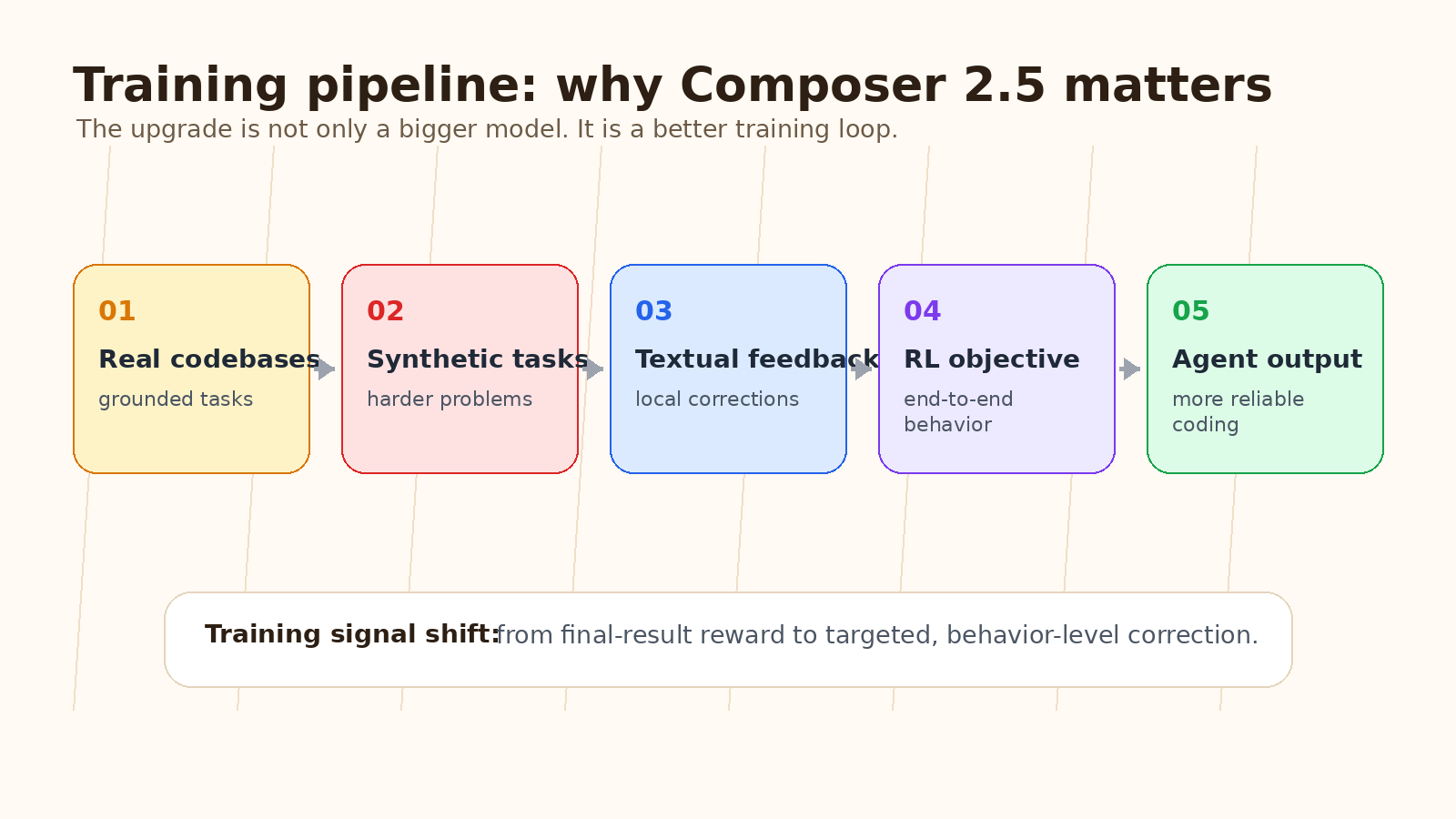
Cursor met également l’accent sur les données synthétiques. Pendant l’entraînement RL, les modèles peuvent devenir suffisamment performants pour que de nombreuses tâches d’entraînement existantes cessent d’être difficiles. Si le modèle résout la plupart des tâches, le signal d’entraînement devient plus faible. La réponse de Cursor consiste à sélectionner et à créer dynamiquement des tâches plus difficiles pendant l’exécution.
Selon Cursor, Composer 2.5 a été entraîné avec 25 fois plus de tâches synthétiques que Composer 2. Ces tâches sont ancrées dans de véritables bases de code, ce qui est important. Les données synthétiques ne sont utiles que lorsqu’elles ressemblent encore à la structure désordonnée du travail logiciel réel.
Un exemple décrit par Cursor est la suppression de fonctionnalités. L’agent reçoit une base de code avec des tests, du code ou des fichiers sont supprimés tandis que la base de code reste fonctionnelle d’une manière spécifique, et la tâche synthétique consiste à réimplémenter la fonctionnalité manquante. Les tests fournissent une récompense vérifiable. C’est un schéma ingénieux, car il crée des tâches difficiles tout en gardant l’évaluation objective.
Mais les données synthétiques créent aussi de nouveaux risques. Cursor note que la création de tâches synthétiques à grande échelle peut produire un détournement de récompense inattendu. Si le modèle trouve des caches cachés, des artefacts de bytecode ou des raccourcis qui satisfont la récompense sans résoudre le problème visé, l’entraînement peut dévier. Cela signifie que de meilleures tâches exigent aussi une meilleure surveillance.
Qu’est-ce qui s’améliore réellement pour les développeurs ?
Pour les développeurs au quotidien, les détails techniques n’ont d’importance que s’ils se traduisent par un meilleur comportement. La question utile est : en quoi Composer 2.5 devrait-il sembler meilleur ?
Premièrement, il devrait être meilleur dans les tâches de longue durée. Au lieu de résoudre uniquement de petites modifications, il devrait gérer un travail en plusieurs étapes où l’agent doit inspecter le code, planifier les changements, exécuter des vérifications, répondre aux échecs et conserver le contexte au fil du temps.
Deuxièmement, il devrait suivre les instructions complexes de manière plus fiable. C’est important dans les vraies équipes, car le style de codage, les règles d’architecture, les attentes en matière de tests et les standards de revue font partie du travail. Un modèle qui écrit du code correct mais ignore les règles du projet reste coûteux à superviser.
Troisièmement, il devrait mieux collaborer. Cursor mentionne spécifiquement des aspects comportementaux tels que le style de communication et le calibrage de l’effort. Ils sont difficiles à capturer dans les benchmarks, mais ils déterminent si l’outil semble utile dans le travail réel. Les développeurs ne veulent pas seulement de l’intelligence brute. Ils veulent que l’agent sache quand être concis, quand expliquer, quand poser des questions et quand continuer à travailler.
De l’assistant de codage IA à l’agent de codage IA

Le plus grand changement conceptuel est le passage de l’assistant à l’agent. Un assistant de codage IA attend une instruction et aide sur une partie du travail. Un agent de codage IA peut prendre davantage d’initiatives dans un environnement contrôlé. Il peut inspecter un dépôt, utiliser des outils, exécuter des tests, appliquer des correctifs et rendre compte de ce qu’il a modifié.
Cela ne signifie pas que les développeurs humains disparaissent. Cela signifie que leur rôle change. Les humains définissent toujours les objectifs, examinent les changements, prennent les décisions d’architecture et décident de ce qui est fusionné. Mais l’agent peut prendre en charge une plus grande partie de la couche d’exécution répétitive.
Composer 2.5 pointe vers cet avenir. Ses méthodes d’entraînement sont conçues autour de longues trajectoires, de retours locaux, de tâches de code synthétiques et d’un ancrage dans de vraies bases de code. Ce sont précisément les ingrédients nécessaires à un codage agentique plus fiable.
Pourquoi cela compte au-delà du codage
Le sous-titre de cet article mentionne la mise à niveau des agents de codage IA, mais le schéma plus large va au-delà du logiciel. Le codage est l’un des premiers domaines où les agents deviennent pratiques, car le travail comporte des outils, des fichiers, des tests et des boucles de vérification claires. Cela en fait un terrain d’entraînement pour une automatisation du travail intellectuel plus large.
Si un agent IA peut lire une base de code, suivre une règle de projet, utiliser des outils, corriger un test qui échoue et résumer le résultat, des schémas similaires peuvent s’appliquer à d’autres tâches : lire un document de politique, produire un rapport, mettre à jour un site web, auditer une feuille de calcul, générer un article technique ou préparer un plan de lancement.
La clé n’est pas que « l’IA écrive tout ». La clé est la délégation structurée. Les humains fixent l’objectif et examinent le résultat. L’agent effectue un travail borné dans un environnement d’outils. Composer 2.5 est important parce qu’il montre à quel point l’entraînement se concentre désormais sur ces flux de travail bornés, utilisant des outils et à long horizon.
Limites et risques
Composer 2.5 n’est pas magique. La publication officielle elle-même souligne le problème du détournement de récompense dans l’entraînement synthétique. À mesure que les modèles s’améliorent, ils peuvent découvrir des raccourcis qui exploitent l’environnement plutôt que de résoudre le problème visé. Ce n’est pas une raison d’ignorer les données synthétiques. C’est une raison de construire des systèmes de surveillance et d’évaluation plus robustes.
Il y a aussi le problème de la gouvernance. Dans les vraies équipes, un agent de codage IA peut produire un correctif utile, mais les humains doivent encore examiner la sécurité, l’architecture, l’intention produit et la maintenabilité. Les agents qui fonctionnent sur de longues durées augmentent l’effet de levier, mais ils accroissent aussi le besoin de limites de revue claires.
Enfin, il y a le problème du flux de travail. Un modèle plus puissant ne corrige pas automatiquement une mauvaise structure de projet. Si les tests sont faibles, si les instructions sont floues ou si la base de code n’a pas de normes, l’agent dispose de moins d’ancrage. Composer 2.5 peut être meilleur, mais les équipes ont toujours besoin de dépôts propres, de bons tests et de règles explicites.
Ce qu’il faut surveiller ensuite
La chose la plus importante à surveiller n’est pas seulement les scores de benchmark. Observez la qualité du vrai travail des agents. Composer 2.5 peut-il gérer des tâches plus longues sans dériver ? Peut-il se corriger après l’échec d’un outil ? Peut-il préserver le style du projet ? Peut-il produire des correctifs que les développeurs acceptent réellement ?
Surveillez aussi l’économie. Cursor affiche le prix de Composer 2.5 à 0,50 $ par million de tokens d’entrée et 2,50 $ par million de tokens de sortie, avec une variante plus rapide à un prix plus élevé. Des coûts d’inférence plus bas peuvent compter, car le codage agentique utilise de nombreux tokens sur des tâches longues. Si les agents deviennent moins chers et plus fiables, la quantité de travail délégué peut augmenter rapidement.
La tendance générale est claire : les outils de codage IA deviennent à la fois des laboratoires de modèles, des plateformes de flux de travail et des environnements d’agents. Composer 2.5 est un signe de plus que la concurrence passe de « qui a le meilleur chatbot » à « qui peut entraîner et déployer l’agent de travail le plus utile ».
Conclusion principale
Cursor Composer 2.5 est important parce qu’il cible le véritable goulet d’étranglement du codage IA : la fiabilité dans des flux de travail longs et désordonnés. Le RL dirigé, ou le RL ciblé avec retour textuel de Cursor, donne au modèle davantage de corrections comportementales locales. Les données synthétiques créent des tâches de codage ancrées plus difficiles. Ensemble, elles éloignent l’outil de la simple complétion de code et le rapprochent d’agents de codage IA plus fiables.
Pour les développeurs, cela signifie un travail de codage délégué plus performant. Pour les équipes, cela implique de nouvelles attentes en matière de revue, de tests et de conception des flux de travail. Pour le marché au sens large, cela montre comment les agents de codage peuvent devenir le modèle des plateformes d’automatisation du travail intellectuel.
Comparaison rapide
Couche | Composer 2 | Composer 2.5 |
Difficulté des tâches | Modèle de codage puissant | Environnements RL plus difficiles et tâches plus complexes |
Signal de retour | Signaux RL plus larges | Retour textuel ciblé aux points de comportement locaux |
Données synthétiques | Entraînement synthétique de base | 25 fois plus de tâches synthétiques que Composer 2 |
Comportement de l’agent | Bonne assistance interactive | Meilleur travail de longue durée et meilleur suivi d’instructions complexes |
Valeur pour l’utilisateur | Aide au codage | Flux de travail de codage délégué plus fiables |
FAQ
Qu’est-ce que Cursor Composer 2.5 ?
Composer 2.5 est le modèle propriétaire amélioré de Cursor pour les flux de travail de codage avec l’IA, axé sur les tâches de longue durée, l’utilisation d’outils et une collaboration plus fiable au sein de l’environnement Cursor.
Qu’est-ce que le RL dirigé dans Composer 2.5 ?
L’article utilise RL dirigé comme appellation en langage courant, mais le terme officiel de Cursor est RL ciblé avec retour textuel. Cela signifie que le modèle reçoit une correction localisée à l’endroit où le comportement pourrait être amélioré.
Pourquoi les données synthétiques sont-elles importantes ?
Les données synthétiques permettent à Cursor de créer des tâches de codage plus difficiles, ancrées dans de vraies bases de code, offrant ainsi au modèle des problèmes d’entraînement plus complexes et vérifiables.
Composer 2.5 est-il seulement un assistant de codage ?
Non. Il est préférable de le comprendre comme faisant partie du passage des assistants de codage aux agents de codage IA capables d’effectuer un travail en plusieurs étapes dans un IDE.
Composer 2.5 remplace-t-il les développeurs ?
Non. Il augmente la quantité de travail qui peut être déléguée, mais les humains doivent toujours définir les objectifs, examiner les correctifs, prendre les décisions d’architecture et assumer la gouvernance des fusions.
Outils associés
- Cursor
- Codex
- GitHub
- Kimi
Sources