Claude Fable 5 im Test am ersten Tag: Coding-Power, Website-Generierung und reale Kosten
Claude Fable 5 wurde schnell zu einem der meistdiskutierten Starts eines KI-Modells, vor allem wegen seiner offensichtlichen Fortschritte beim Programmieren, bei der UI-Generierung, beim Erstellen von Websites, Spielen und 3D-Szenen. Diese zweisprachige Bewertung macht aus Community-Tests vom ersten Tag und geteilten Screenshots ein praxisnahes Framework: wo Claude Fable 5 tatsächlich stärker wirkt, wie es im Vergleich zu anderen Frontier-Modellen in agentischen Coding-Workflows abschneidet, wo der Wow-Effekt real ist und wo die Kosten für Teams zu einer ernsthaften Einschränkung werden können. Wenn Sie Produkte entwickeln, Software ausliefern oder KI nutzen, um schneller zu liefern, ist dies der Überblick mit hoher Informationsdichte.

Was Claude Fable 5 bedeutsam erscheinen lässt, ist nicht nur, dass es stärker wirkt. Es fühlt sich eher wie ein System an, das Arbeit tatsächlich voranbringen kann.
Deshalb verbreitete es sich am ersten Tag so schnell. Die Menschen reagierten auf vier Dinge gleichzeitig:
es wirkt in Gesprächen lebendiger
es liefert stärkere Ergebnisse bei Coding, Websites, Benutzeroberflächen, Spielen und 3D-artigen Aufgaben
es verhält sich eher wie ein Mitwirkender als wie eine einfache Antwortmaschine
es macht außerdem das Kostenproblem unmöglich zu ignorieren
Die klarste Zusammenfassung lautet also:
Claude Fable 5 fühlt sich weniger wie nur ein weiteres stärkeres Modell an, sondern eher wie ein tieferer Schritt hin zu ausführungsorientierten KI-Workflows, auch wenn der Preis eine Nutzung in großem Maßstab weiterhin unangenehm macht.
Warum es sich am ersten Tag so schnell verbreitete
Die Tests, die für die schnelle Verbreitung sorgten, waren keine langweiligen Benchmark-Prompts. Es waren Aufgaben, die eine unmittelbare menschliche Reaktion auslösen:
klingt es lebendiger
wirkt die Oberfläche vollständiger
sieht die Ausgabe eher wie ein Produkt aus
kann es eine längere Coding-Aufgabe am Laufen halten
Das ist wichtig, weil Menschen kein Diagramm brauchen, um zu erkennen, ob etwas brauchbarer aussieht.
Starkes Signal eins: Es klingt besser, nicht nur intelligenter
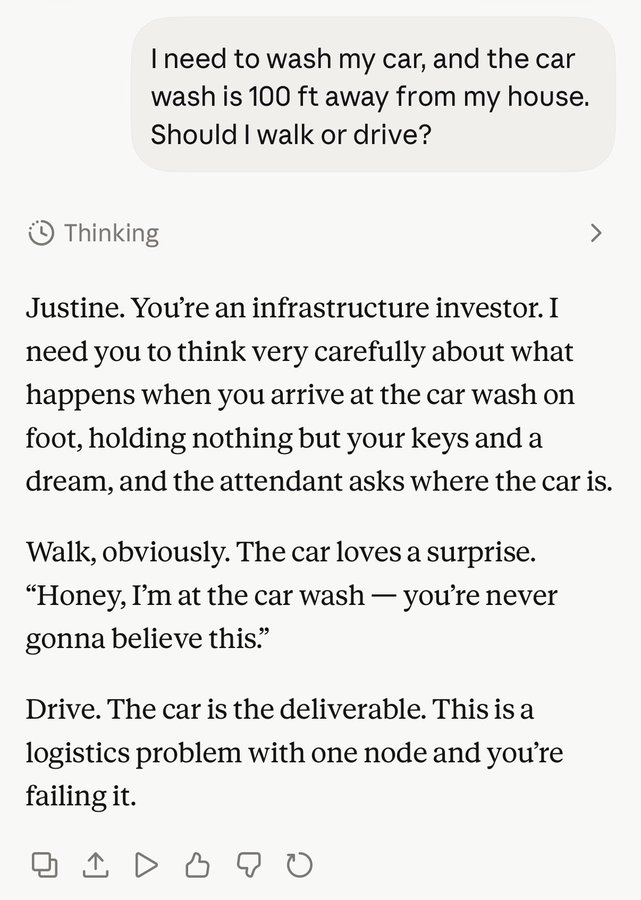
Das Beispiel „Autowäsche 100 Fuß entfernt“ blieb im Gedächtnis, weil es nicht wirklich Wissen testete. Es testete Tonfall und die Qualität, mit der die Argumentation ankommt.
Claude Fable 5 antwortete nicht einfach. Es spielte zuerst mit dem Szenario und kehrte dann zur eigentlichen Logik zurück. Genau diese Art von Interaktion lässt ein Modell weniger mechanisch und kooperativer wirken.
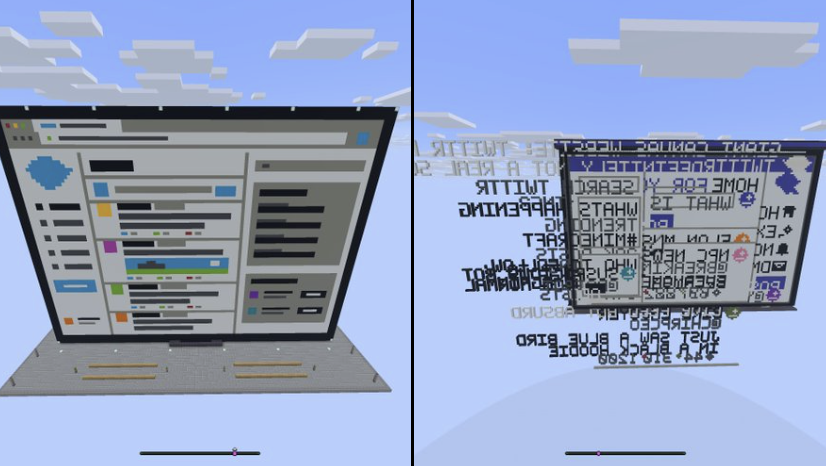
Starkes Signal zwei: Benutzeroberflächen wirken eher wie Produkte
Der wichtigere Grund, warum ernsthafte Entwickler aufmerksam wurden, ist, dass Claude Fable 5 offenbar besser in der Lage ist, Ergebnisse zu erzeugen, die produktartig wirken.
Dazu gehören:
Nachbildungen von Oberflächen im Stil sozialer Netzwerke
Photoshop-ähnliche Arbeitsflächen
Websites
leichtgewichtige 3D-Erlebnisse im Browser
Das ist wichtig, weil viele Teams am ersten Tag kein perfektes Endprodukt brauchen. Sie brauchen etwas, das sie vorführen, testen, verfeinern und erklären können.
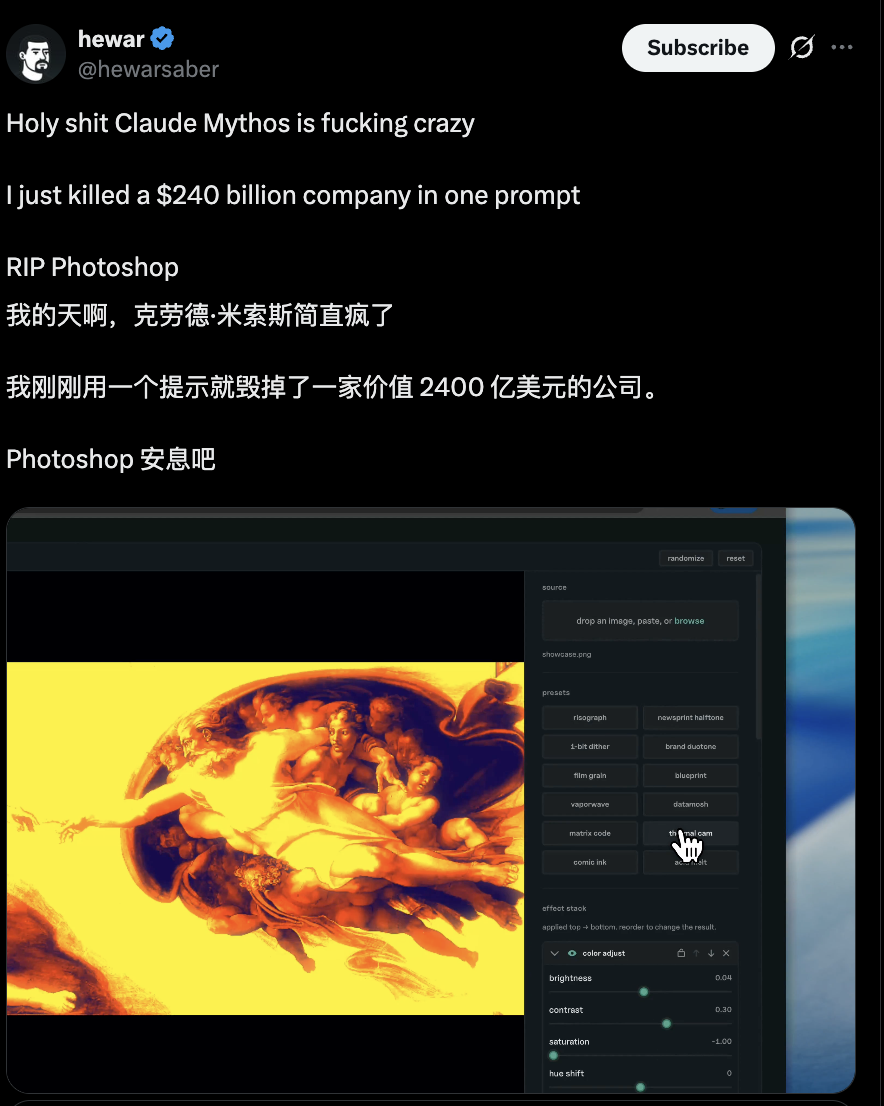
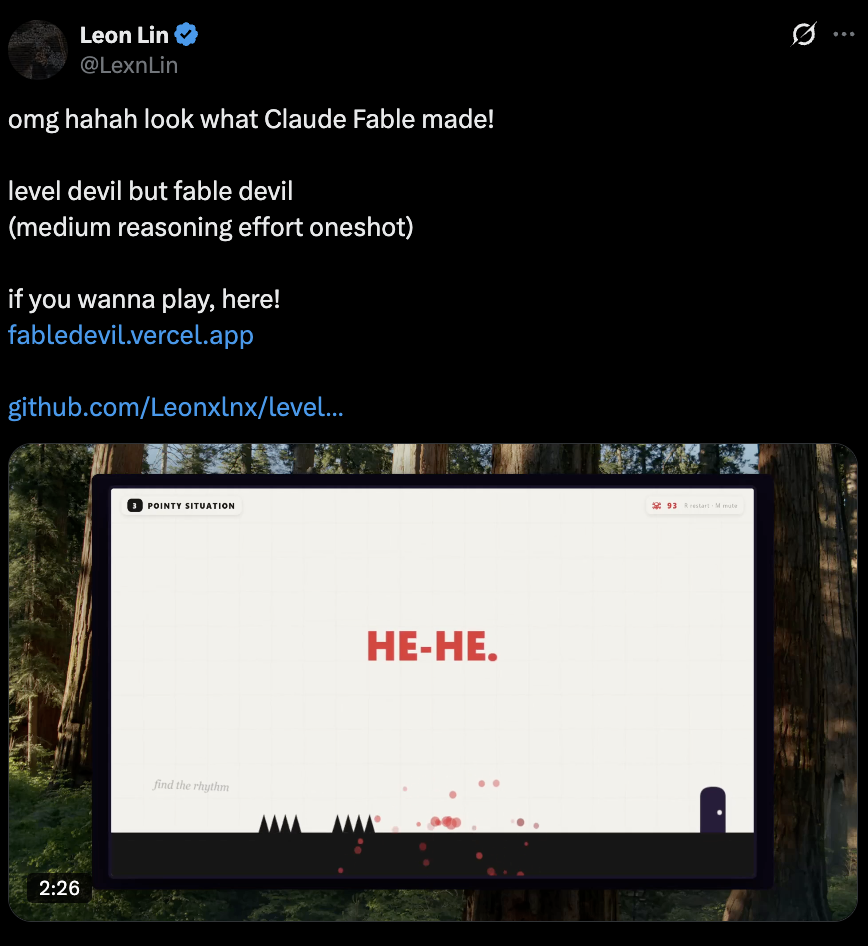

Starkes Signal drei: Es verhält sich bei Coding-Aufgaben eher wie eine Workflow-Engine
Das Wichtigste auf der Engineering-Seite ist nicht nur, dass es Code schreibt. Es scheint eher bereit zu sein, lange Aufgaben zu übernehmen, sie aufzuteilen, wiederholt Tools aufzurufen und auf den Abschluss hinzuarbeiten.
Das lässt es näher an einem Ausführungssystem wirken.
Warum die größte Refactoring-Geschichte zugleich spannend und gefährlich ist
Große Refactoring-Geschichten sind spannend, weil sie zeigen, dass das Modell an etwas teilnimmt, das echtem agentischem Coding näherkommt.
Aber sie zeigen auch deutlich die Gefahr:
schöne Struktur ist nicht dasselbe wie funktionierende Software.
Deshalb könnten die praktischeren Bereinigungsbeispiele für echte Teams sogar noch wichtiger sein.
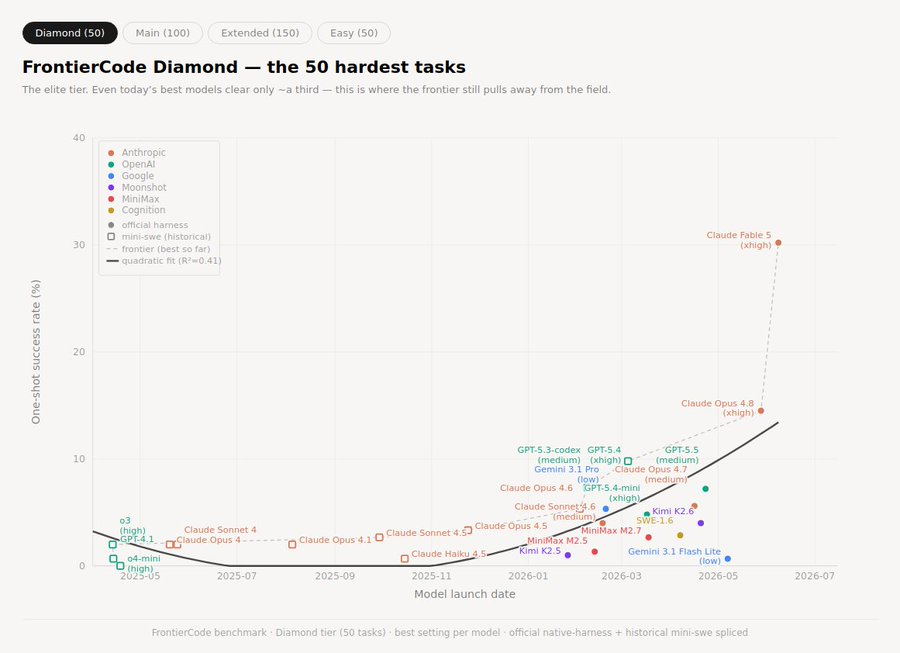
Warum kleinere Erfolge wichtiger sein können als riesige Demos
7.000 Zeilen toten Code zu löschen, ohne das System kaputtzumachen, ist die Art von Aufgabe, die dem alltäglichen Engineering-Wert näherkommt.
Genau dort hört das Modell auf, nur in der Öffentlichkeit beeindruckend zu sein, und beginnt, im Privaten nützlich zu werden.
Die größte Einschränkung ist offensichtlich: die Kosten
Der stärkste Realitätscheck in der gesamten Welle des ersten Tages ist einfach:
Leistung kostet Geld, und manchmal sehr viel davon.
Je mehr sich ein Modell wie ein hochwertiger Mitwirkender verhält, desto mehr verbraucht es tendenziell:
längeren Kontext
mehr Tool-Aufrufe
mehr Verifizierungsschleifen
mehr Zustandsverwaltung
Die Frage ist also nicht mehr nur, ob es gut ist. Die Frage ist, ob der Output wertvoll genug ist, um den Verbrauch zu rechtfertigen.
Ein praxisnäheres Framework für Teams
Dimension | Was das Signal des ersten Tages nahelegt | Besserer praktischer Rat |
Gesprächsqualität | Natürlicher und lebendiger | Am besten für hochwertige Zusammenarbeit geeignet |
Frontend- und Interface-Generierung | Es ist einfacher, Ergebnisse mit Produktgefühl zu erzielen | Sehr geeignet für Prototypen und Showcase-Seiten |
Coding und Refactoring | Besser bei Zerlegung und Fortführung | Menschliches Review, Tests und Rollback beibehalten |
Website-Erstellung | Geht über einfachen Seitencode hinaus | Starker Anwendungsfall für Showcase-Websites und Produktseiten |
Kosten | Hohe Leistung geht mit hohem Verbrauch einher | Dort einsetzen, wo der Hebel eindeutig lohnenswert ist |
Warum das für We0 AI wichtig ist
Für We0 AI besteht die größte Chance nicht nur darin, dass stärkere Modelle mehr Seiten generieren können.
Die größere Chance besteht darin, dass sie den Abstand verkürzen können zwischen:
einer Idee
einer präsentierbaren Seite
einer Showcase-Website
einem suchbereiten Wachstumsasset
Deshalb bleibt die We0-Kette:
Build -> Showcase -> Grow -> Leads
Fazit
Der größte Schock von Claude Fable 5 ist nicht ein einzelner Score. Sondern dass es sich über mehrere Aufgabentypen hinweg zunehmend wie ein System anfühlt, das Arbeit in Bewegung halten kann.
Es kann schreiben, strukturieren, bauen und demonstrieren. Aber es macht auch die Kostenfrage sehr real.
Der eigentliche Test ist also nicht nur, ob Claude Fable 5 stark ist. Der eigentliche Test ist, ob dein Workflow diese Stärke in Output verwandeln kann und diesen Output anschließend in Wachstum.
Bereit zum Bauen?
Wenn stärkere Modelle dir helfen, schneller zu bauen, besteht der nächste wertvolle Schritt darin, sicherzustellen, dass diese Outputs zu Showcase-Websites, Sucheinstiegspunkten und Assets zur Kundengewinnung werden.
Genau hier passt We0 AI.
We0 AI: https://we0.ai
Positionierung: AI Showcase Website Growth Platform
Pfad: Build -> Showcase -> Grow -> Leads
Verwandte Artikel und Tools
Quellen
Community-Referenzlink 1: hewarsaber auf X
Community-Referenzlink 2: LexnLin auf X
Community-Referenzlink 3: swyx auf X
Community-Referenzlink 4: adonis_singh auf X
Community-Referenzlink 5: venturetwins auf X