Gemini 3 Flash 生产级应用开发指南:流式架构、成本优化、监控与迁移实战
这是一篇面向开发者与 AI 产品团队的 Gemini 3 Flash 生产级应用开发指南,系统整理了流式输出、批处理、混合路由、缓存策略、错误重试、熔断、迁移、监控、安全与成本优化等核心问题。文章同时从 We0 AI 的增长视角补充了产品官网、文档页、SEO / GEO 内容页与线索转化链路,帮助团队把模型能力真正落成可上线、可增长、可持续获客的产品

Gemini 3 Flash 最值得关注的,不只是更快,而是它第一次把“快”和“能上线”放进了同一个模型里。
如果你的产品有高频问答、写作辅助、实时翻译、批量抽取这类场景,它很可能比上一代默认方案更划算。
真正决定上线效果的,不是模型名字,而是你有没有把 streaming、缓存、重试、熔断、监控和 fallback 一起补齐。
对 We0 AI 这种既要做产品能力、又要做展示型官网和搜索获客的团队来说,模型性能只是前半程,后半程是 Build -> Showcase -> Grow -> Leads。
Gemini 3 Flash 生产级应用开发指南:架构、性能与成本优化实战
2026 年 5 月整理版
Gemini 3 Flash 现在最有讨论度的点,是它把 速度、质量和成本 放到了一个更容易平衡的位置。对很多团队来说,这意味着原本只能在 Demo 里跑通的能力,终于有机会往真实生产环境推进。
但这里有个很现实的问题:模型变便宜了,不代表生产环境就自动变简单。 真正上线之后,用户体验、错误处理、缓存命中率、限流、监控、回退链路,哪一项没补上,都会把账单和口碑一起拉垮。
这篇文章按原文结构做了微改整理,重点放在:架构模式、性能调优、错误处理、迁移策略、真实业务场景、成本控制,以及怎么把技术能力最终接到增长链路上。
为什么 Gemini 3 Flash 值得单独研究
在过去,“快模型”往往意味着要牺牲一部分质量;“强模型”又常常意味着更高成本和更长延迟。Gemini 3 Flash 真正让人愿意认真评估的地方,在于它更像一个可以直接放进生产栈里的默认层。
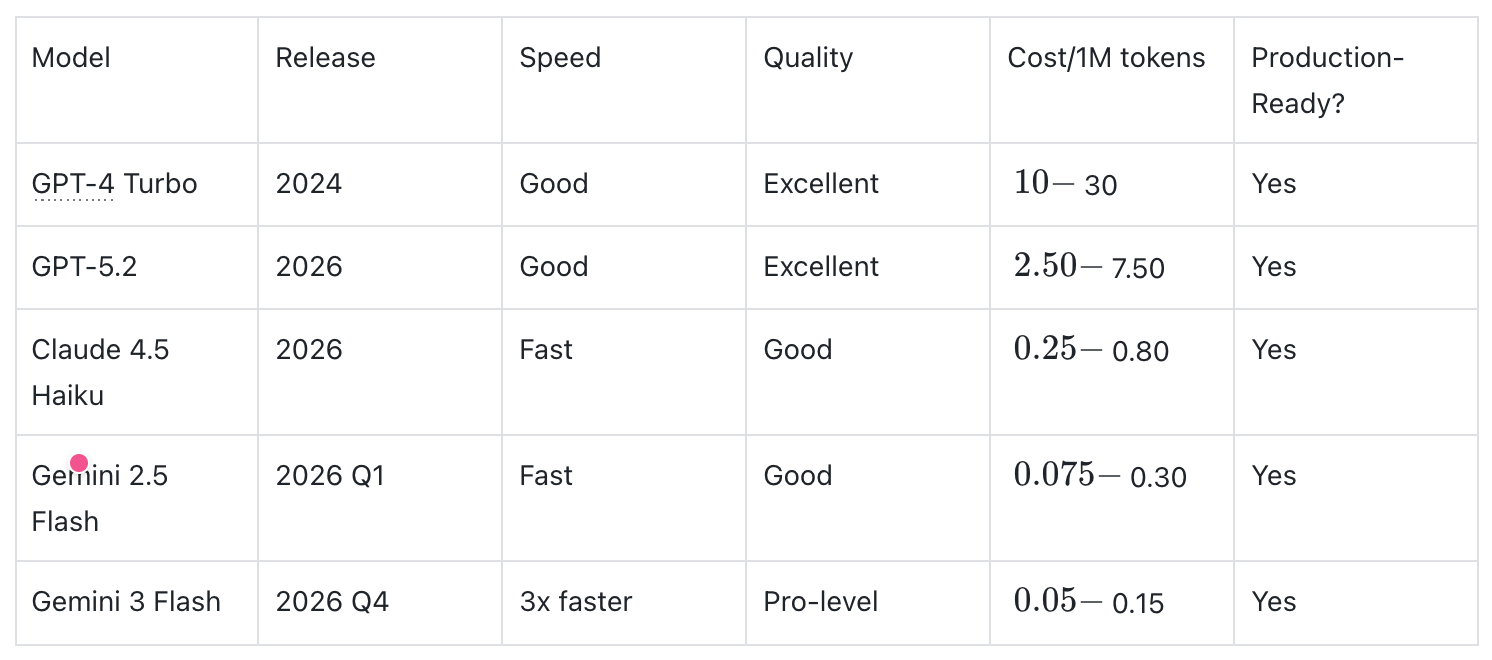
真正的突破点是:Gemini 3 Flash 开始接近“快而不降级”的状态。 这会让很多以前必须做双模型分层的产品,重新评估默认路由。
现实业务里的影响
如果你的产品是:
面向用户的聊天、问答、实时写作
高频批量生成、分类、抽取
需要在速度和成本之间反复抠细节的 API 服务
那么 3 倍速度 + 更低单价 往往不只是成本数字更漂亮,而是能直接改写产品的交互手感、单位会话成本和可承载并发。

生产环境里最实用的三种架构模式
模式 1:Streaming for Real-Time UX
用户最敏感的不是“模型总共跑了几秒”,而是“我有没有立刻看到东西开始出来”。所以在聊天、写作助手、Copilot 类产品里,streaming 基本应该是默认项,而不是锦上添花。
import { GoogleGenerativeAI } from '@google/generative-ai';
const genAI = new GoogleGenerativeAI(process.env.GEMINI_API_KEY!);
const model = genAI.getGenerativeModel({ model: 'gemini-3-flash' });
export async function POST(req: Request) {
const { prompt } = await req.json();
const result = await model.generateContentStream(prompt);
const encoder = new TextEncoder();
const stream = new ReadableStream({
async start(controller) {
for await (const chunk of result.stream) {
const text = chunk.text();
controller.enqueue(encoder.encode(text));
}
controller.close();
},
});
return new Response(stream, {
headers: { 'Content-Type': 'text/plain; charset=utf-8' },
});
}前端如果同步按 token 级别渲染,用户会明显感觉“系统是活的”。这类场景里,感知延迟通常比总耗时更影响留存。
const response = await fetch('/api/chat', {
method: 'POST',
body: JSON.stringify({ prompt }),
});
const reader = response.body?.getReader();
const decoder = new TextDecoder();
let content = '';
while (reader) {
const { done, value } = await reader.read();
if (done) break;
content += decoder.decode(value);
setMessage(content);
}模式 2:Batch Processing for Cost Optimization
只要工作负载不是强实时,批处理就是最该先考虑的降本方式之一。比如:
批量内容摘要
商品标签抽取
FAQ 清洗
支持工单分类
import PQueue from 'p-queue';
const queue = new PQueue({ concurrency: 10 });
async function processBatch(items) {
return Promise.all(
items.map((item) =>
queue.add(async () => {
const result = await model.generateContent(item.prompt);
return { id: item.id, output: result.response.text() };
})
)
);
}这类模式的关键不只是“并发跑起来”,而是:你要同时管理好队列深度、失败重试、限流响应和单批成本。
模式 3:Hybrid Routing(Flash + Pro)
并不是所有请求都值得上高成本模型。一个更稳的办法是:
普通问答、补全、结构化抽取走 Flash
高复杂度分析、关键业务判断走 Pro
class ModelRouter {
async generate(prompt, taskType) {
if (taskType === 'simple_chat' || taskType === 'autocomplete') {
return geminiFlash.generateContent(prompt);
}
if (taskType === 'complex_reasoning' || taskType === 'code_review') {
return geminiPro.generateContent(prompt);
}
return geminiFlash.generateContent(prompt);
}
}这种路由方式的价值在于,你不用为每一次普通请求支付“最强模型税”。
性能调优:别只盯模型,先盯系统
1. 延迟优化
大多数场景里,真正拖慢体验的并不只是模型推理本身,还包括:
过长 prompt
重复上下文
不必要的串行调用
缺乏缓存
实践上可以先做三件事:
能 stream 的先 stream
能缓存的先缓存
能缩短上下文的先缩短上下文
2. 缓存策略
缓存通常是最直接的省钱按钮。很多团队上线之后才发现,重复问题、重复模板、重复系统指令其实非常多。
import Redis from 'ioredis';
const redis = new Redis(process.env.REDIS_URL!);
async function cachedGeneration(prompt) {
const cacheKey = `gemini:${hash(prompt)}`;
const cached = await redis.get(cacheKey);
if (cached) {
return JSON.parse(cached);
}
const result = await model.generateContent(prompt);
const text = result.response.text();
await redis.setex(cacheKey, 3600, JSON.stringify(text));
return text;
}很多业务里,30% 到 50% 的成本下降,往往不是靠换模型,而是靠缓存命中率。
3. Prompt 优化
Gemini 3 Flash 对结构清晰、任务边界明确的 prompt 往往更稳定。与其不断加长系统提示,不如:
把目标写清楚
把输出格式写清楚
把工具调用边界写清楚
让 Markdown 结构替代冗长自然语言

错误处理与可靠性
指数退避重试
async function generateWithRetry(prompt, maxRetries = 3) {
let lastError;
for (let i = 0; i < maxRetries; i++) {
try {
return await model.generateContent(prompt);
} catch (error) {
lastError = error;
const delay = Math.pow(2, i) * 1000 + Math.random() * 1000;
await new Promise((resolve) => setTimeout(resolve, delay));
}
}
throw lastError;
}真正上线之后,有没有 retry 不是可选项,而是最低限度的自我保护。
熔断器模式
class CircuitBreaker {
constructor(threshold = 5, timeout = 60000) {
this.failures = 0;
this.threshold = threshold;
this.timeout = timeout;
this.lastFailureTime = 0;
this.state = 'CLOSED';
}
async call(fn) {
if (this.state === 'OPEN') {
if (Date.now() - this.lastFailureTime > this.timeout) {
this.state = 'HALF_OPEN';
} else {
throw new Error('Circuit breaker is OPEN');
}
}
try {
const result = await fn();
this.onSuccess();
return result;
} catch (error) {
this.onFailure();
throw error;
}
}
}如果你没有熔断,局部故障很容易把整条链路拖下去。
迁移策略
从 GPT-4 / GPT-5 路线迁移
一个更稳的迁移方法,不是一次性切换,而是:
先找出高流量、速度敏感、成本敏感的接口
做 A/B 测试
比质量、比延迟、比成本、比错误率
分阶段放量
async function abTestGeneration(prompt, userId) {
const useGemini = hashUserId(userId) % 100 < 10;
if (useGemini) {
const result = await geminiFlash.generateContent(prompt);
logMetric('gemini_flash', result);
return result.response.text();
} else {
const result = await openai.chat.completions.create({
model: 'gpt-4',
messages: [{ role: 'user', content: prompt }],
});
logMetric('gpt4', result);
return result.choices[0].message.content;
}
}从 Claude 迁移到 Gemini 3 Flash
这里最容易踩坑的是 prompt 结构和 tool schema。很多 Claude 风格 prompt 偏 XML 化,而 Gemini 往往更适合清晰的 Markdown 结构。
## Instructions
Analyze this code for bugs.
## Code
```javascript
function foo() { ... }
```函数调用部分也要检查字段结构差异:
const claudeTools = [{
name: 'get_weather',
description: 'Get weather for a location',
input_schema: {
type: 'object',
properties: { location: { type: 'string' } }
}
}];
const geminiTools = [{
functionDeclarations: [{
name: 'get_weather',
description: 'Get weather for a location',
parameters: {
type: 'object',
properties: { location: { type: 'string' } }
}
}]
}];真实业务场景
1. 客服聊天机器人
适合 Gemini 3 Flash 的典型配置是:
高并发
对首字节速度敏感
需要多轮对话
成本必须可控
2. 内容生成流水线
像标题生成、摘要、标签、FAQ 扩写、落地页文案这类任务,通常更适合批处理 + 缓存。对 We0 AI 这类要持续做展示型官网、案例页、SEO 内容页的团队来说,这一类流水线很容易直接接进增长系统。
3. 实时翻译 API
只要是低延迟、多语种、短文本密集调用的场景,Gemini 3 Flash 都会比“默认上大模型”更容易跑出健康的单位成本。
成本优化检查清单
默认开启 streaming,降低感知等待
缓存高重复请求,先吃到最容易拿的成本红利
按任务复杂度分流,避免每一跳都上 Pro
收紧 prompt,减少无意义上下文
追踪 fallback 比例,别只看主模型单价
用批处理吃吞吐,不要把离线任务伪装成实时任务
监控与可观测性
必看指标
p50 / p95 / p99 latency
input / output token usage
cache hit rate
retry rate
fallback rate
cost per request
error rate by endpoint
建议报警项
延迟异常上升
错误率突然抬头
每日 token 消耗偏离预算
fallback 调用比例上升
缓存命中率明显下滑
安全最佳实践
1. API Key 管理
export GEMINI_API_KEY=your_key_here2. 输入清洗
function sanitizeInput(input) {
return input
.replace(/<script[^>]*>.*?<\/script>/gi, '')
.replace(/javascript:/gi, '')
.trim();
}3. 输出过滤
function filterOutput(text) {
const blockedPatterns = [/api[_-]?key/i, /password/i, /secret/i];
for (const pattern of blockedPatterns) {
if (pattern.test(text)) {
throw new Error('Sensitive content detected');
}
}
return text;
}
常见坑与解决方案
坑 1:没处理限流
async function rateLimitedCall(fn, maxRetries = 5) {
for (let i = 0; i < maxRetries; i++) {
try {
return await fn();
} catch (error) {
if (error.status === 429) {
const retryAfter = error.headers?.['retry-after'] || Math.pow(2, i);
await new Promise((resolve) => setTimeout(resolve, retryAfter * 1000));
continue;
}
throw error;
}
}
}坑 2:忽略 token 限制
function chunkText(text, maxTokens = 30000) {
const estimatedTokens = text.length / 4;
if (estimatedTokens <= maxTokens) {
return [text];
}
const chunkSize = Math.floor(text.length / Math.ceil(estimatedTokens / maxTokens));
const chunks = [];
for (let i = 0; i < text.length; i += chunkSize) {
chunks.push(text.slice(i, i + chunkSize));
}
return chunks;
}坑 3:没有 fallback
async function generateWithFallback(prompt) {
try {
return await geminiFlash.generateContent(prompt);
} catch (error) {
console.error('Gemini Flash failed, trying fallback');
try {
return await openai.chat.completions.create({
model: 'gpt-3.5-turbo',
messages: [{ role: 'user', content: prompt }],
});
} catch (fallbackError) {
return { text: 'Service temporarily unavailable. Please try again.' };
}
}
}
结论:从 POC 到 Production,拼的是工程完整度
Gemini 3 Flash 改变的,不只是模型价格表,而是很多 AI 应用的可上线边界。过去一些看起来“功能能跑但算不过账”的能力,现在开始有机会跑进真实业务。
但别误会,便宜和快从来不等于简单。 真正把它变成生产能力,靠的是下面这些东西有没有一起补齐:
重试与限流处理
缓存与成本建模
监控、告警与回退
安全过滤与权限隔离
增长层的展示页面、文档页、FAQ 页与转化链路
如果你只是把 API 接上了,那只是 Build 的开始。真正能让产品持续拿到搜索流量、AI 推荐流量和销售线索的,是你有没有把 Showcase、Grow、Leads 那半条链也搭起来。
Related Tools and Resources
We0 AI Showcase Website Planner:规划产品官网、能力页、案例页、文档页和比较页的结构。
We0 AI SEO / GEO Content Map:把技术能力拆成可搜索、可推荐、可转化的文章和落地页矩阵。
API Cost Model Worksheet:提前估算 prompt 量、缓存命中率、fallback 率和 blended cost。
Rollout Checklist:把 streaming、重试、熔断、监控、fallback 和 rate limit 一起拉成上线清单。
Provider Comparison Board:横向比较 Gemini、Claude、OpenAI 与开源路线的速度、质量和预算。
FAQ
Gemini 3 Flash 为什么适合生产环境?
它的关键点在于:速度和质量不再是只能二选一。 对高频请求场景来说,这意味着更低单次成本、更快响应,以及更少的分层复杂度。
Gemini 3 Flash 最适合哪些产品?
聊天、写作助手、内容流水线、翻译接口、知识问答、结构化抽取,都很适合先拿它做默认层,再按复杂度决定是否升级到更强模型。
上线前最值得先做的三件事是什么?
streaming、缓存、fallback。 这三件事往往比继续纠结 prompt 细节更早带来真实收益。
技术团队为什么还要关心展示型官网和 SEO / GEO?
因为模型能力本身不会自动变成客户。真正能把产品能力讲清楚、被搜到、被 AI 推荐到、最后转成线索的,是官网结构、案例页、FAQ、比较页和内容矩阵。