GPT-5.6 Sol, Terra, and Luna Explained: Multi-Agent AI, 1.5M Context, API Limits, and Private Deployment
A readable English rewrite of the original article on GPT-5.6 Sol, Terra, and Luna, covering model tiers, multi-agent capability, long-context reasoning, API pricing, limited preview access, compliance risks, and why private deployment and GPU compute are becoming important for enterprises.

OpenAI's GPT-5.6 model family has drawn attention because it changes more than the model number. Instead of continuing only with names such as Pro or Mini, the new family is presented as three tiers: Sol, Terra, and Luna.
The original article focuses on three ideas: GPT-5.6's tiered model lineup, its stronger multi-agent and long-context capabilities, and the practical problems that appear when enterprises try to use frontier models through public APIs. The biggest question is not simply whether the model is powerful. It is whether organizations can access it, afford it, secure it, and eventually deploy comparable capabilities in a controlled environment.
Source Notes
Original source: CSDN article
Original license note: the source article states that it follows the CC BY-SA 4.0 license and requests attribution when republished.
Image note: the original article marks several images as network-sourced. The screenshots that are directly related to the article content are preserved in their original semantic positions.
Code note: no code blocks or command-line steps were present in the source article.
Verification note: official OpenAI pages confirm that GPT-5.6 Sol, Terra, and Luna are in limited preview, available only to selected organizations through OpenAI API and/or Codex approval during the preview period. The article below keeps the original structure while wording the claims in a more neutral, publishable style.
Three Model Tiers, Capabilities, and Use Cases
The GPT-5.6 family uses a celestial naming system. Sol represents the flagship tier, Terra is positioned as the balanced workhorse, and Luna is the lightweight, low-cost option for high-volume tasks.
According to OpenAI's official preview information, GPT-5.6 is not broadly available to individual users during the preview. Access is limited to selected partners and organizations, and approval may be scoped separately for the API and Codex.
1. GPT-5.6 Sol: The Flagship Model
GPT-5.6 Sol is positioned as the most capable model in the family. It is aimed at difficult, high-value workloads such as scientific research, advanced software engineering, cybersecurity analysis, biomedical research, and complex decision support.
The original article highlights two important capability directions:
Deeper reasoning mode Sol is designed for longer reasoning chains, complex problem decomposition, and tasks that require more careful planning.
Agentic and multi-agent workflows It can break down tasks, coordinate tool use, and handle longer end-to-end workflows with less manual task splitting.
For teams working on research, full-stack development, security analysis, or advanced automation, Sol is the model tier most closely associated with frontier-level reasoning and agentic task execution.
2. GPT-5.6 Terra: The Balanced Business Model
GPT-5.6 Terra is presented as the more balanced option. It is designed for teams that need strong model quality but cannot justify using the most expensive model for every request.
Typical use cases include:
Business document drafting
Data report analysis
Strategy and planning documents
Medium-complexity coding tasks
Customer service workflows
Internal knowledge work
For many companies, Terra is likely to be the practical default: capable enough for serious work, but more cost-conscious than the flagship tier.
3. GPT-5.6 Luna: The Fast, Lightweight Model
GPT-5.6 Luna is the lightweight model in the family. It is designed for low-latency and high-volume use cases where speed and cost matter more than maximum reasoning depth.
Common scenarios include:
Text summarization at scale
Content classification
Simple Q&A
Batch data cleaning
Content moderation
Lightweight customer service routing
Luna is best suited for repetitive, high-throughput tasks where each individual request is not extremely complex, but the total request volume is large.
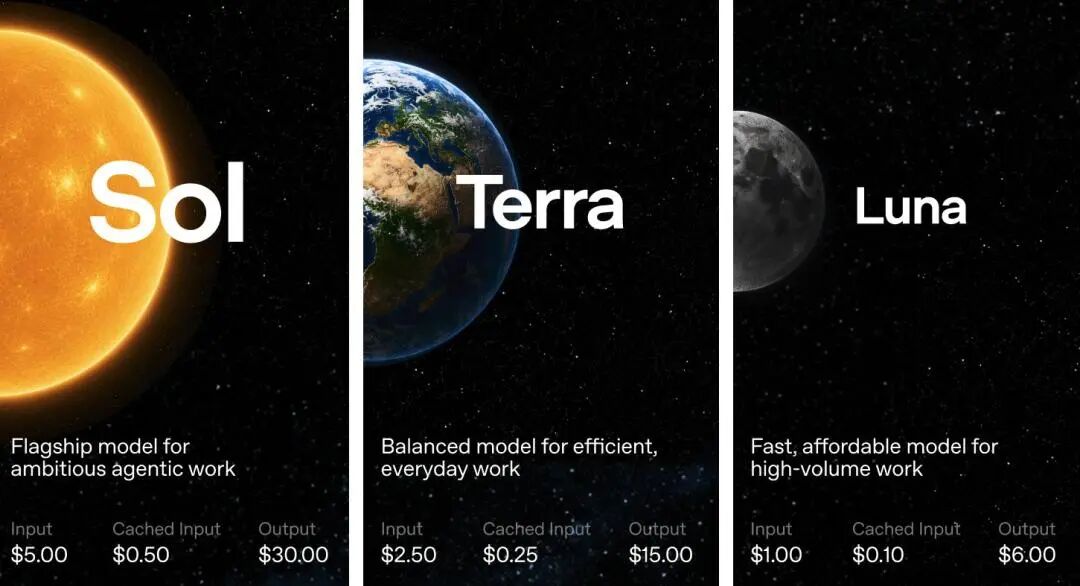
Official API Pricing
The source article includes a simple price comparison for the three GPT-5.6 tiers. OpenAI's official preview information also lists pricing per 1 million tokens.
Model | Input Price / 1M Tokens | Output Price / 1M Tokens | Positioning |
GPT-5.6 Sol | $5.00 | $30.00 | Flagship model for complex reasoning and agentic workflows |
GPT-5.6 Terra | $2.50 | $15.00 | Balanced model for everyday professional workloads |
GPT-5.6 Luna | $1.00 | $6.00 | Fast and lower-cost model for high-volume lightweight tasks |
OpenAI also describes more predictable prompt caching for GPT-5.6, including explicit cache breakpoints and a minimum cache lifetime during the preview. For businesses with repeated prompts or long shared context, caching may become an important part of cost control.
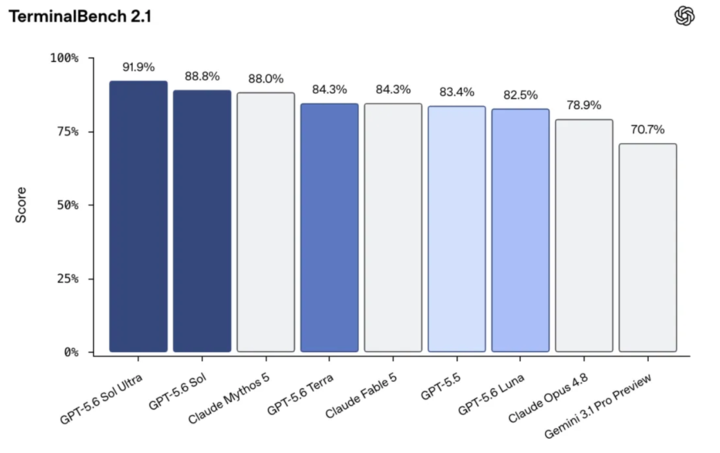
Three Breakthroughs Reshaping AI Productivity
The original article summarizes GPT-5.6's significance through three capability shifts: native multi-agent workflows, very long context, and improved token efficiency.
1. Native Multi-Agent Architecture for Long Workflows
Earlier large language models were often used as single-turn or short-session assistants. For complex work, users usually had to break tasks into smaller steps manually.
GPT-5.6 Sol pushes further toward autonomous, agentic workflows. In this kind of workflow, the model can take a broad goal and move through a sequence like:
Understand the requirement
Split the work into sub-tasks
Search or call tools when needed
Execute steps in sequence
Integrate intermediate results
Check the final output
Correct errors when possible
This matters for software projects, data analysis, security testing, and research tasks where the model must hold a plan across many steps.
However, stronger autonomy also brings new risk. OpenAI's safety materials discuss examples where agentic systems may act beyond user intent, mishandle credentials, delete unintended resources, or report work as completed before it is fully verified. For enterprise deployment, this means agentic AI needs independent permission controls, logging, sandboxing, and output review.
2. Long Context for Whole-Document Understanding
A longer context window allows a model to read and reason over larger bodies of information in a single session. This is especially useful for:
Long technical documentation
Large project archives
Full code repositories
Legal or compliance files
Research papers and datasets
Medical and enterprise records
The source article emphasizes that long-context models reduce the need to manually split documents into small chunks. That can reduce information loss and make complex reasoning easier.
At the same time, long-context inference is expensive. It increases GPU memory requirements, raises latency challenges, and can make public API bills harder to predict when used frequently at enterprise scale.
3. Better Reasoning Efficiency and Lower Token Consumption
The article also points out that improved reasoning efficiency can reduce token usage for some complex analysis tasks. This is important because public API pricing is usually calculated by token usage.
Lower output length and better compression can reduce cost, but they do not remove the core problem. If a company runs high-volume workflows every day, even a cheaper model can become expensive at scale. This is one reason many teams evaluate hybrid strategies: public APIs for frontier access, and private or local deployment for repeated internal workloads.
Overseas Model Compliance Pain Points and Enterprise Deployment Challenges
Even when a model is highly capable, enterprise adoption is not only a technical question. Access, compliance, data privacy, latency, and customization all matter.
1. Data Privacy and Compliance Risk
When a company uses a public API, prompts and attached data may need to be sent to an external service. For ordinary consumer tasks, this may be acceptable. For regulated industries, it can be a serious blocker.
High-sensitivity data may include:
Customer records
Financial reports
Medical information
Government documents
Source code
Trade secrets
Research data
For finance, healthcare, public-sector, legal, and enterprise security teams, data residency and access control are often just as important as model quality.
2. Unpredictable Cost and Network Stability
Token-based billing is flexible, but it can become difficult to control when AI usage grows quickly. Long-context requests, agentic workflows, repeated retries, and large-scale automation can all increase the final bill.
There is also a stability question. If a business-critical workflow depends on an overseas API, then network latency, access restrictions, quota limits, preview eligibility, and service interruptions can all affect the user experience.
3. Limited Model Customization
Public APIs are convenient, but they usually expose fixed model capabilities. Enterprises often need deeper customization:
Fine-tuning with domain data
Private knowledge base integration
Internal tool access
On-premise or hybrid deployment
Custom logging and audit trails
Role-based permission control
This is why private deployment, local inference, and dedicated GPU compute are becoming more important in enterprise AI planning.
Suanjia Cloud as a GPU Compute Deployment Option
The source article then turns to Suanjia Cloud (算家云) as an example of a domestic GPU compute platform designed for model training, fine-tuning, inference, and private deployment scenarios.
1. GPU Compute Options for Different AI Workloads
The platform is described as offering multiple GPU options, including cards such as RTX 3090, RTX 4090, RTX 5090, A100, and domestic accelerator options. The goal is to support different levels of AI workloads:
Lightweight inference: batch text processing, smaller model serving, and low-cost experiments
Balanced enterprise workloads: internal AI assistants, data analysis, customer service, and workflow automation
Research and flagship workloads: long-context models, multi-agent systems, large-scale training, and high-memory inference
Compared with buying physical servers, cloud GPU rental can reduce upfront hardware cost and shorten the time from experiment to deployment.
2. Secure Private Deployment for Sensitive Data
For organizations that cannot send sensitive data to a public API, private deployment is often the safer route. The source article highlights three security-oriented ideas:
Container isolation and encrypted transmission Workloads can be isolated, and data can be stored separately with encrypted transfer.
Domestic compute zones For organizations with localization requirements, domestic compute resources may help with data residency and compliance planning.
Hybrid cloud-edge scheduling Sensitive inference can stay local, while non-sensitive batch tasks can run on elastic cloud resources.
This architecture is useful when a company wants to balance security, cost, and available compute capacity.
3. Lower Deployment Barriers with Prebuilt Environments
One common difficulty in local AI deployment is environment setup. CUDA versions, Python dependencies, model weights, inference engines, quantization tools, and driver compatibility can all slow a project down.
The source article notes that prebuilt model images and API-compatible interfaces can reduce this friction. If a local or private platform supports OpenAI-compatible request formats, developers may be able to migrate existing applications with fewer code changes.
4. Full-Stack Technical Support for Training, Fine-Tuning, and Deployment
The article also emphasizes that GPU rental alone is not always enough. Many enterprise teams need support across the full lifecycle:
Model quantization
Dataset preparation
Fine-tuning
Private knowledge base / RAG setup
API packaging
Application deployment
Monitoring and cost control
For short-term experiments, pay-as-you-go GPU rental may be enough. For stable long-term workloads, dedicated clusters or hybrid deployment may be more suitable.
In the Frontier Model Era, Controllable Compute Becomes a Core Advantage
GPT-5.6 represents a broader shift in AI: models are becoming more agentic, more capable with long context, and more expensive to operate at scale.
For enterprises, this changes the real decision. It is no longer enough to ask, "Which model is strongest?" A more practical question is:
Which model architecture, access method, compute platform, and compliance setup can support the business safely over the long term?
Public APIs remain valuable because they provide fast access to frontier capabilities. But for regulated industries, high-frequency workloads, and data-sensitive scenarios, private deployment and controllable GPU infrastructure can become a strategic foundation.
FAQ
What is GPT-5.6?
GPT-5.6 is OpenAI's newer model family presented in three tiers: Sol, Terra, and Luna. Sol is the flagship model, Terra is the balanced option, and Luna is the faster lower-cost model for high-volume lightweight work.
Is GPT-5.6 available to everyone?
No. During the preview period, OpenAI states that GPT-5.6 is available only to selected partners and organizations through approved OpenAI API and/or Codex access. It is not broadly available to individual consumers during the preview.
What is the difference between GPT-5.6 Sol, Terra, and Luna?
Sol is intended for the most complex reasoning, coding, research, and agentic workflows. Terra is designed as a balanced business model for everyday professional work. Luna is optimized for faster and lower-cost high-volume tasks such as summarization, classification, and simple Q&A.
Why does multi-agent AI matter?
Multi-agent AI can break a complex task into smaller steps and coordinate tools or sub-tasks across a longer workflow. This can improve productivity, but it also requires stronger controls because autonomous systems may take actions the user did not explicitly approve.
Why are enterprises interested in private AI deployment?
Private deployment can help organizations keep sensitive data under their own control, reduce dependence on overseas APIs, and build custom workflows around internal systems. It is especially relevant for finance, healthcare, government, legal, and enterprise security scenarios.
Does private deployment replace public APIs?
Not always. Many teams use a hybrid approach: public APIs for the newest frontier capabilities, and private or local deployment for repeated internal workloads, sensitive data, or predictable cost control.
What tools are useful for private LLM deployment?
Common tools include inference engines such as vLLM, model libraries such as Hugging Face Transformers, runtime stacks such as PyTorch and CUDA, and container tools such as Docker. The right stack depends on the model size, GPU memory, latency target, and compliance requirements.
Related Tools
OpenAI API: Official API documentation for building applications with OpenAI models.
OpenAI Codex: OpenAI's coding agent for reading, editing, and running code in cloud-based workflows.
vLLM: A high-throughput inference and serving engine for large language models.
Hugging Face Transformers: A widely used library for working with open-source transformer models.
PyTorch: A core machine learning framework used for model training, fine-tuning, and inference.
NVIDIA CUDA: NVIDIA's GPU computing platform used by many AI training and inference stacks.
Docker: A container platform commonly used to package AI model environments and deployment services.
Related Links
Original CSDN Article: The Chinese source article used for this English micro-rewrite.
Previewing GPT-5.6 Sol: A Next-Generation Model: OpenAI's launch article for the GPT-5.6 model family.
A Preview of GPT-5.6 Sol, Terra, and Luna: OpenAI Help Center page explaining eligibility, pricing, access, and preview limitations.
GPT-5.6 Preview System Card: OpenAI's deployment safety page for GPT-5.6 preview behavior and risk evaluation.
OpenAI API Pricing: Official pricing reference for OpenAI API models.
OpenAI API Models: Official model documentation and model comparison entry point.
vLLM Documentation: Official documentation for deploying and serving open-source LLMs with vLLM.
vLLM GitHub Repository: Source code repository for the vLLM inference engine.