Gemini 3.5 Flash vs 3.1 Pro: Best Choice for MCP Agents, RAG, Long-Context Retrieval, and Terminal Coding
A practical Gemini 3.5 Flash vs Gemini 3.1 Pro decision guide built around five real workloads: MCP agents, tool-heavy workflows, 200-page document retrieval, high-frequency RAG, ARC-style reasoning, and terminal coding agents. This version preserves the original workload-by-workload structure, decision tree, June outlook, FAQ, and related articles, while reframing the CTA around We0 AI’s build-showcase-grow-leads model.
Key Takeaways
If the workload is mostly agent loops, tool calls, and multi-step execution, Flash should be your default.
If the workload is mostly long-document retrieval and exact clause finding over 100k+ tokens, Pro is still safer today.
For high-frequency RAG, the real advantage is often cache economics, not only list price.
ARC-style abstract reasoning and hardest-question workloads are still better aligned with Pro.
The most practical answer for production teams is not one model, but routing per task.
Gemini 3.5 Flash vs 3.1 Pro: When to Use Which
What makes the source article useful is that it does not stop at saying “Flash beat last year’s Pro.” It breaks that claim down into five concrete workloads, which is the only way a model comparison becomes operational instead of decorative.
The right question is not “which model is best in general?” It is which of your tasks are really paying for speed, tool use, cache leverage, long-context retrieval, or reasoning ceiling.
For a team like We0 AI, that question matters beyond raw API usage. Model choice affects how fast you can produce docs, showcase pages, FAQs, SEO content, knowledge bases, and lead-generation workflows that actually ship.
Workload 1: MCP Agents and Tool-Heavy Loops
Source verdict: Flash wins clearly.
This is the pattern where one task triggers multiple model turns and several tool calls in sequence: search, vector retrieval, terminal work, code execution, file reads, validation, and iteration.
Benchmark
Gemini 3.5 Flash
Gemini 3.1 Pro
MCP Atlas
83.6%
78.2%
Toolathlon
56.5%
49.4%
GDPval-AA (Elo)
1656
1314
That is not a narrow benchmark win. It is a workflow-level advantage. The source article treats the 342-point GDPval-AA gap as the strongest signal that Flash was post-trained for real agentic work, not only for conventional chat.
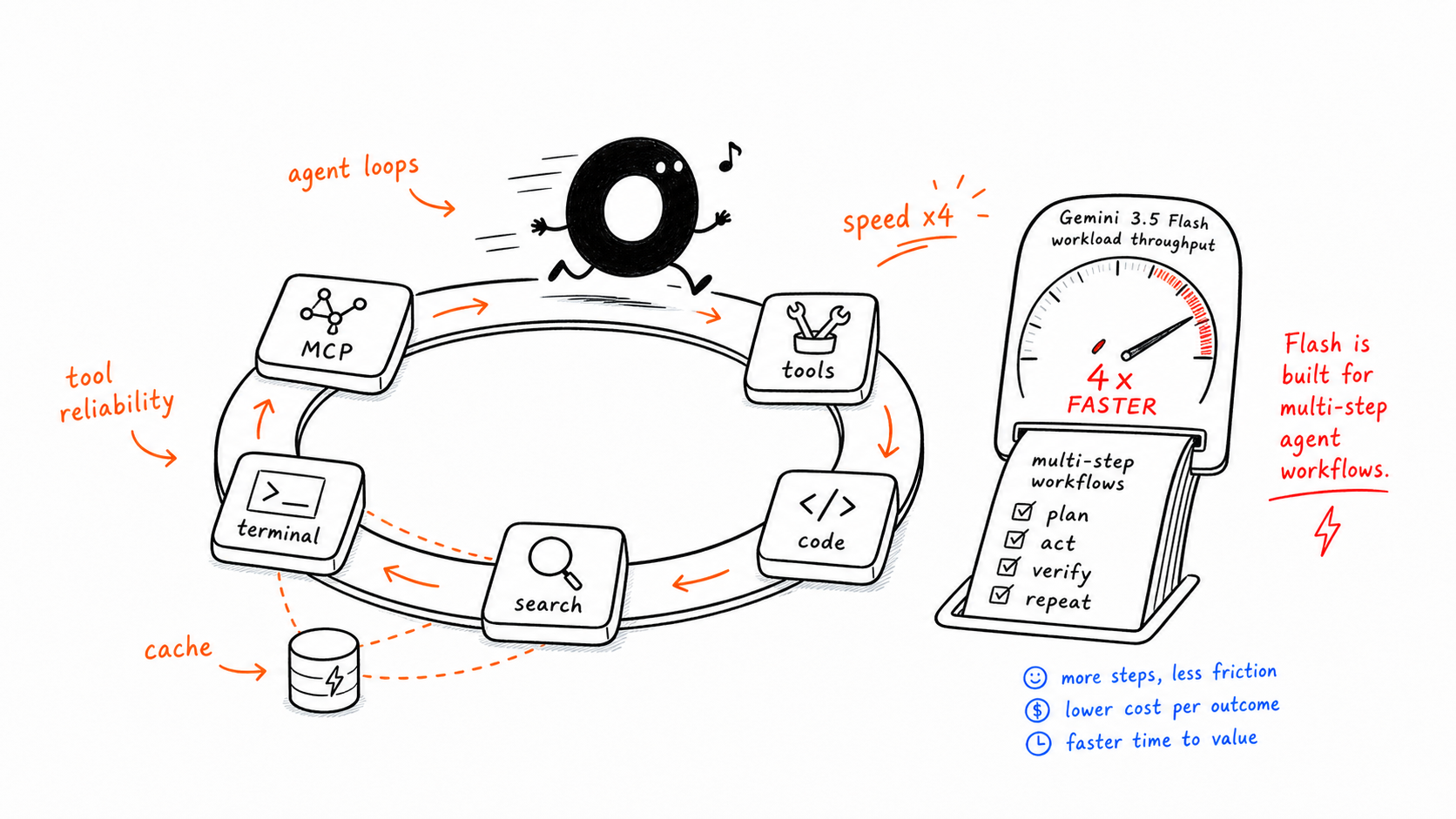
If your team is building:
MCP tool loops
research or automation agents
terminal-based coding assistants
high-frequency, multi-step workflows
then Flash is not only cheaper. It is faster, loop-friendlier, cache-friendlier, and better shaped for repeated execution.
That is especially relevant for We0 AI style systems where model output turns into:
content production pipelines
showcase-site docs and FAQ generation
SEO / GEO article workflows
knowledge-base and support automation
Workload 2: Needle-in-Haystack Retrieval Across Long Documents
Source verdict: Pro is still safer here.
This is the key exception in the whole article. Flash is not “bad” in absolute terms, but when the job becomes finding one exact clause inside a very long document, Pro remains the steadier choice.
Benchmark
Gemini 3.5 Flash
Gemini 3.1 Pro
MRCR v2 (128k)
77.3%
84.9%
MRCR v2 (1M)
26.6%
26.3%
The 128k slice is the practical warning sign. If your promise is “upload the whole contract and ask anything,” then this is not the category you should move blindly to Flash yet.
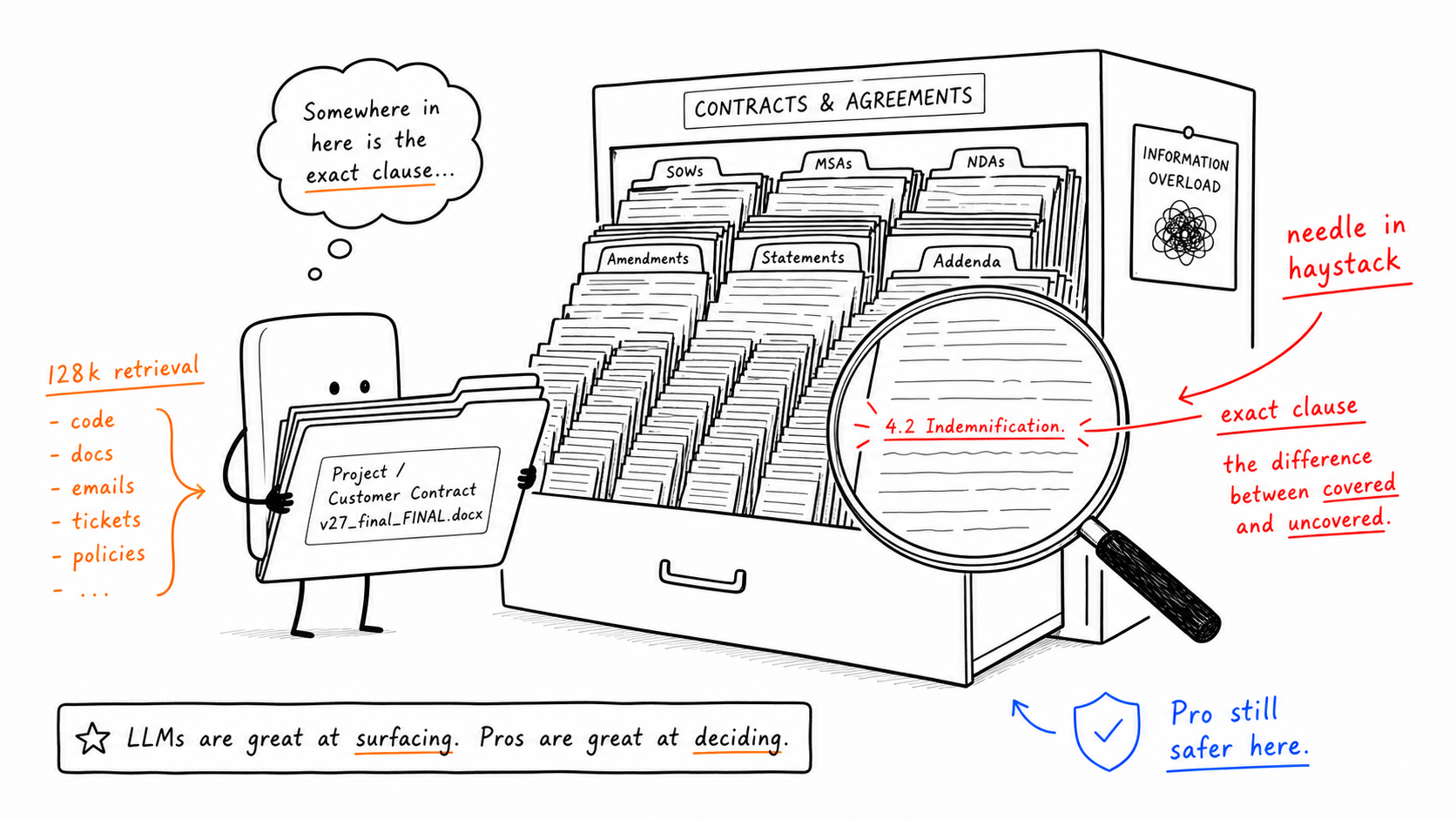
This matters for workloads like:
contract clause lookup
compliance and legal review
long technical specification search
large-codebase cross-file traceability
The underlying rule is simple: when the hardest part is not generating, but precisely locating the right sentence inside a huge context, Pro still deserves the job.
Workload 3: High-Frequency RAG With a Stable Corpus
Source verdict: Flash with aggressive caching is the obvious default.
This is the scenario most relevant to SaaS support systems, internal knowledge tools, and documentation-heavy products. The biggest cost is often not a single answer, but repeated reads against the same system prompt and stable documentation prefixes.
Factor
Gemini 3.5 Flash
Gemini 3.1 Pro
Input price
$1.50 / 1M
$2.00 / 1M
Output price
$9.00 / 1M
$12.00 / 1M
Cached input
$0.15 / 1M
$0.50 / 1M
Throughput
289 tok/s
~70 tok/s
The most important point here is that cache economics can matter more than the headline model price difference.
If you are building:
help-center RAG
internal SOP assistants
product docs and FAQ assistants
sales or support retrieval systems over stable content
then Flash is often what makes the system not just possible, but scalable.
That lines up with We0 AI’s broader logic too: content should not only exist. It should become searchable, recommendable, reusable, and able to keep acquiring leads over time. Stable corpora and cache-friendly model patterns are naturally aligned with that goal.
Workload 4: ARC-Style Abstract Reasoning
Source verdict: this is still Pro territory.
As soon as the task starts to look more like a puzzle, an abstract pattern challenge, a difficult olympiad problem, or expert-grade novelty, Flash is no longer the clear favorite.
Benchmark
Gemini 3.5 Flash
Gemini 3.1 Pro
ARC-AGI-2
72.1%
77.1%
Humanity's Last Exam
40.2%
44.4%
The source article makes the distinction cleanly: Flash optimized for agentic breadth. Pro still holds a higher reasoning ceiling.
If your application value depends on:
genuine abstract reasoning
hardest-question reliability
novel problem solving
research-style tasks
then staying on Pro is still the more conservative move today.
Workload 5: Terminal-Based Coding Agents
Source verdict: Flash for most terminal coding, with one important carve-out.
Benchmark
Gemini 3.5 Flash
Gemini 3.1 Pro
Terminal-Bench 2.1
76.2%
70.3%
SWE-Bench Pro (Public)
55.1%
54.2%
Blueprint-Bench 2
33.6%
26.5%
This is one of the most practical sections in the article because it matches real developer behavior closely:
fix a stack trace
implement a feature across a few files
run tests, patch code, and retry
convert a spec into code
For that kind of high-frequency, iterative, tool-heavy coding, Flash is the stronger default.
The carve-out matters, though: large-codebase, cross-file, high-context refactors are really a long-context retrieval problem in disguise. That is where Pro still keeps some ground.
The Decision Tree
The source article’s decision tree is worth preserving because it is actually usable:
Is your workload primarily agent loops or tool use?
├─ YES → Gemini 3.5 Flash
└─ NO → Is it long-context retrieval over 100k+ tokens?
├─ YES → Gemini 3.1 Pro
└─ NO → Is it abstract reasoning / hardest expert questions?
├─ YES → Gemini 3.1 Pro or Deep Think
└─ NO → Is it RAG with stable corpus?
├─ YES → Gemini 3.5 Flash with aggressive caching
└─ NO → Gemini 3.5 Flash by defaultFor most teams, the real message is this: Flash should probably be your default model, but not your only model.
What Doesn’t Change in June
The June section is smart because it deals directly with the natural follow-up: should you simply wait for Gemini 3.5 Pro?
The answer is not a blanket yes or no. It depends on the workload:
If you need MCP agents right now, Flash is already worth shipping.
If you need cache-friendly RAG, Flash already has a structural cost advantage.
If your system is reasoning-critical, bouncing from Pro to Flash and back is usually wasted motion.
June may shift some boundaries, but it does not erase today’s task-level trade-offs.
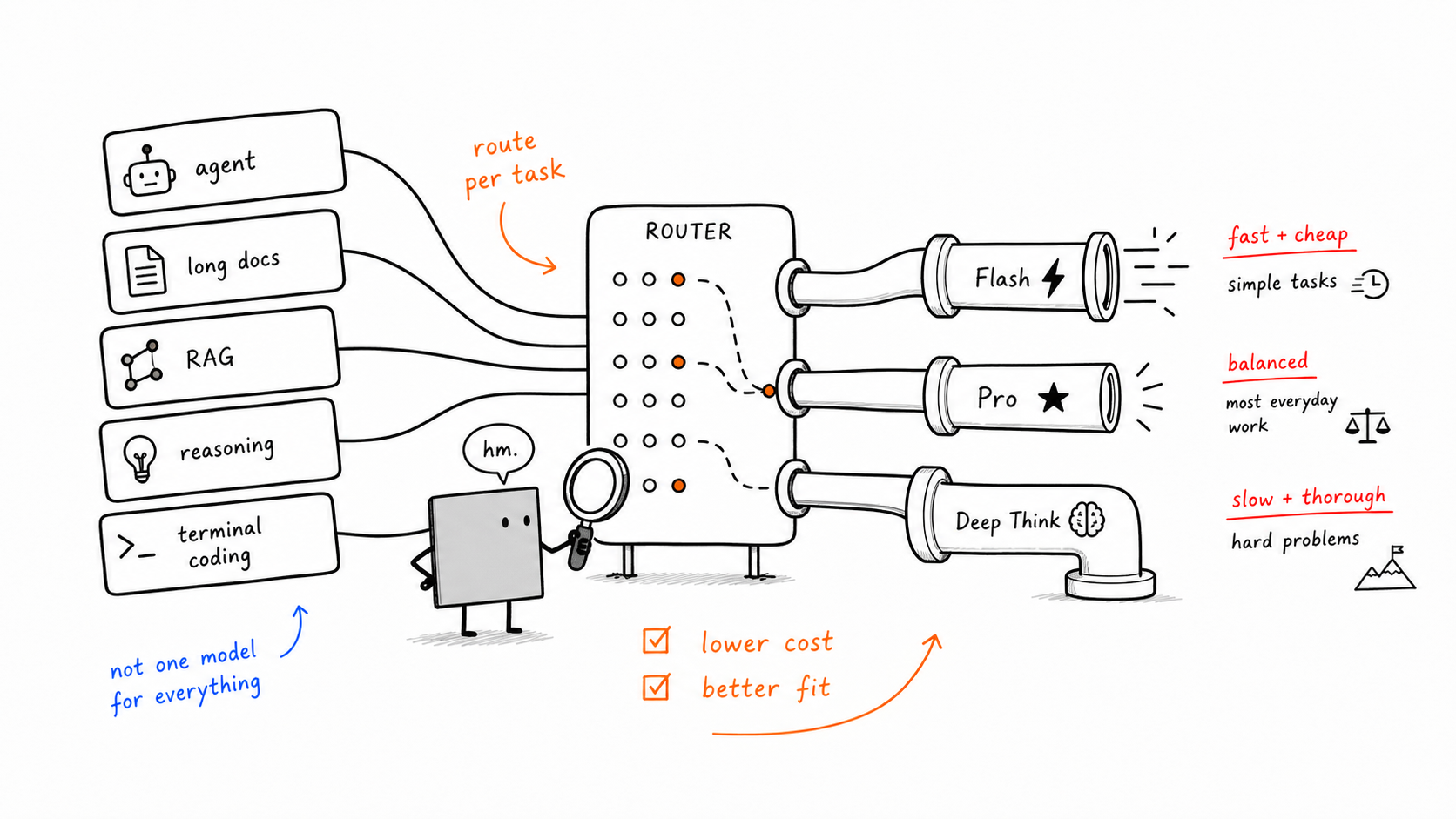
Ship Both — Route Per Task
This is the most production-grade takeaway in the article, and also the easiest one to reinterpret through We0 AI’s lens.
For real applications, the better move is often not arguing about the one best model, but routing intelligently:
send agent loops, tool use, and terminal coding to Flash
send long-document analysis and exact-clause retrieval to Pro
send hardest-reasoning cases to a deeper reasoning model
At We0 AI, that same principle extends beyond model routing. The fuller chain looks more like this:
choose the right model for the right task
turn output into usable product content, docs, FAQs, and showcase pages
make those assets discoverable through SEO / GEO and AI recommendation surfaces
convert that visibility into leads and customers
That is the real reason We0 AI cares about Build -> Showcase -> Grow -> Leads instead of stopping at “we integrated a model API.”
Ready to Build?
If you are already building AI products, workflows, or showcase websites, this comparison can turn into a straightforward execution rule set:
default to Flash for agentic workflows
route long-document retrieval to Pro
structure stable corpora and FAQs for cache efficiency
convert model output into docs, help-center content, case studies, and search assets
For We0 AI, the goal is not only to help a team connect a model. It is to help them turn those capabilities into showcase-ready, searchable, and lead-generating systems.
FAQ
Should I replace Gemini 3.1 Pro with Gemini 3.5 Flash everywhere?
No. Agentic workflows, terminal coding, and MCP tool loops are strong candidates for Flash. Long-document retrieval, abstract reasoning, and hardest-question workloads are still safer on Pro.
Is Gemini 3.5 Flash actually stronger overall?
Based on the published benchmarks in the source article, Flash wins 11 of 15 and is especially strong in MCP Atlas, Terminal-Bench 2.1, Finance Agent v2, and Blueprint-Bench 2.
Which one is cheaper?
Flash is cheaper on list price, but the more important difference is cached input pricing. For stable prefixes and repeated RAG-style workloads, that gap becomes much larger.
Is Gemini 3.5 Flash good for long-context document retrieval?
Not if the main requirement is exact clause retrieval across very long documents. The source article’s MRCR v2 128k numbers still favor Pro there.
Which model should I use for terminal coding agents?
For most tool-heavy, iterative terminal coding tasks, Flash is the better default. For massive, cross-file refactors over very large repositories, Pro still deserves consideration.
Should I wait for Gemini 3.5 Pro?
If your pipeline is reasoning-critical and the wait is only a few weeks, waiting can be rational. If you need MCP agents, terminal coding, and fast workflows now, Flash is already worth shipping.
Related Articles
Gemini 3.5 Flash complete guide: benchmarks, pricing, and API takeaways
Gemini 3.5 Flash developer guide: three API traps and a real MCP agent
Building production apps with Gemini 3 Flash: architecture, performance, and cost
Gemini 3.1 Pro vs GPT-5.4: how to choose by workload
Friend Links
Anthropic — Frontier AI models and AI safety research.
Hugging Face — Open-source AI models, datasets, and ML tools.
Vercel — Deployment platform for modern web applications.
LangChain — Framework for building LLM-powered applications.
Pinecone — Vector database for AI retrieval systems.
Cloudflare — Performance, security, and edge infrastructure.
We0 AI — Build, Showcase, Grow, and Generate Leads with AI.